【1.1】Nanopore
纳米孔是唯一可以直接对RNA链进行测序的技术,可选择不经过逆转录或PCR反应。Nanopore直接RNA测序技术是对天然RNA进行测序,能够保留并检测RNA碱基修饰信息,对poly(A)尾长进行相对准确的估算,同时进行全长异构体分析,还原真实RNA特征。


Oxford Nanopore推出的纳米孔测序装置
一、基本介绍
1.1 工作原理
新型纳米孔测序法(nanopore sequencing);采用电泳技术。
Nanopore测序当中的核心部件是这个由蛋白质构成的纳米级的小孔,我们称之为“Pore”。
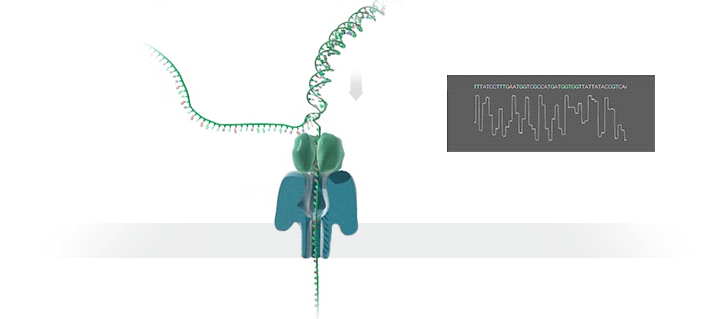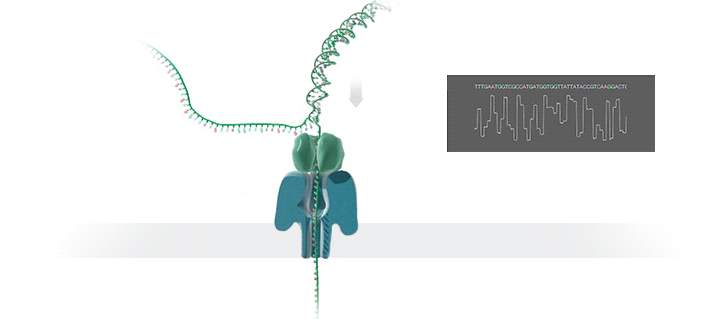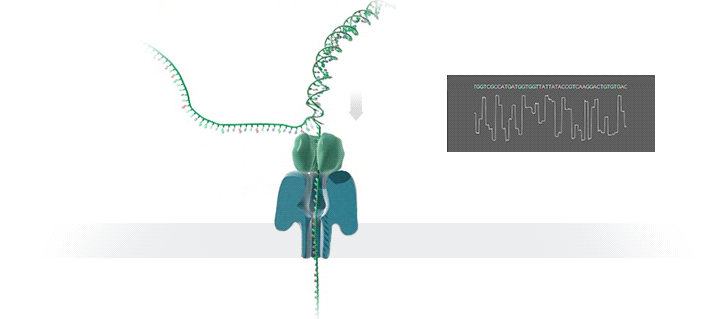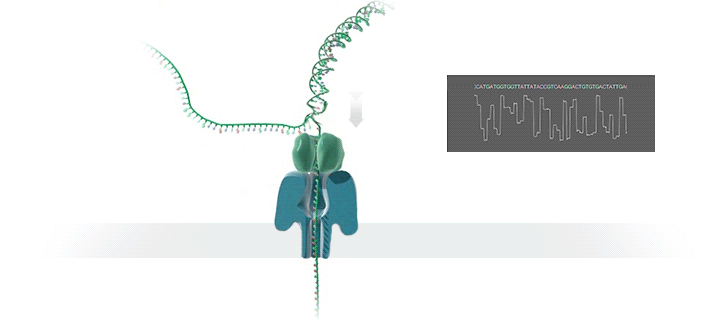
这个蛋白质插在一层电阻率很高的薄膜当中。薄膜的两侧都浸没在含有离子的buffer当中。在薄膜的两侧加上不同的电位,离子就会通过蛋白质小孔,从膜的一侧移动到膜的另一侧,小孔当中就会有电流通过。当DNA的单链通过这个小孔的时候,就会对离子的流动造成阻碍。不同的碱基造成的阻碍大小是不一样的。这样,不同的碱基所造成电流大小的波动,就被记录下来。
- motor蛋白牵引DNA至nanopore并解链
- DNA的单链通过小孔的时候,会对离子的流动造成阻碍。
- 不同的碱基所造成电流大小的波动,就被记录下来。
这些被记录下来的电流波动信号。经过分析,反推出原来经过小孔的是什么碱基。这就是Nanopore测序的基本原理。
-
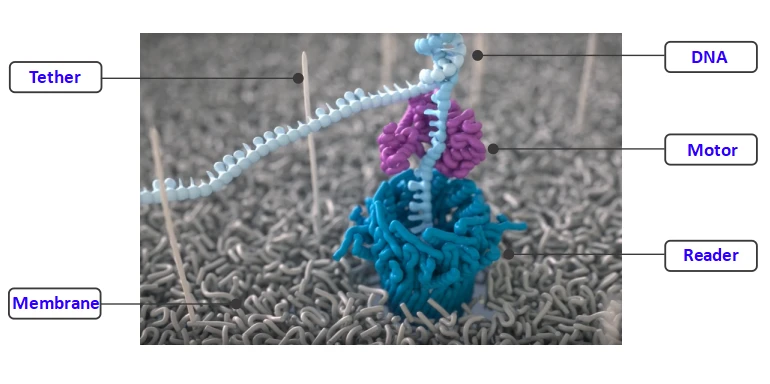
Reader——跨膜蛋白,可以嵌入到细胞膜中作为离子或分子通道的跨膜蛋白,具有天然的蛋白纳米孔。经过人为基因工程修饰后,得到Nanopore测序所需的Reader蛋白。
-
Membrane——多聚物薄膜,Reader蛋白会被嵌入到高电阻率的由人工合成的多聚物膜中,膜两侧是离子溶液,在两侧加不同的电位,离子就会在孔中流动,形成电流。
-
Motor——马达蛋白,在Nanopore文库构建时,需要在接头上连接一种马达蛋白,用于将DNA或RNA分子推入纳米孔中。
-
Tether——用于锚定DNA或RNA链,防止其在溶液中飘动,并使其进入纳米孔中。
1.2 实验设计
Nanopore的这层膜,现在是用的人工合成的一种多聚物的膜。膜上嵌入的这个蛋白,是整个测序芯片的核心。Nanopore公司给它起了名字叫“Reader”。用作Reader的蛋白,一般是天然能形成穿膜孔的跨膜蛋白,再经过基因工程进行改造,这样得来的。
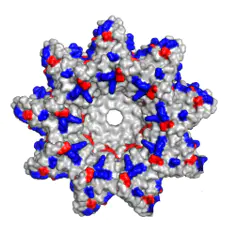
Nanopore公司已经试过了很多种跨膜蛋白来做这个Reader。目前R9版的芯片用的是一个来自于大肠杆菌的叫CsgG的蛋白质。在把这个蛋白做了几百处基因工程改造之后,用作Reader蛋白。之前Nanopore公司还用过Hemolysin蛋白和MspA蛋白(来做Reader蛋白)。Nanopore公司每换用一种新的Reader蛋白,就给新的芯片起一个新的版本号。例如:R7、R8等。现在用的芯片版本号是“R10”。
R7.3,3KHz,6mers/event;
R9,4KHz,5mers/event;
在测双链DNA文库的时候,会用一个DNA解螺旋酶,来帮助解开DNA双螺旋,变成两条单链。以便其中一条单链能够穿过蛋白质小孔。这个DNA解螺旋酶,在这里也被称为“Motor”,就是动力(蛋白)的意思。
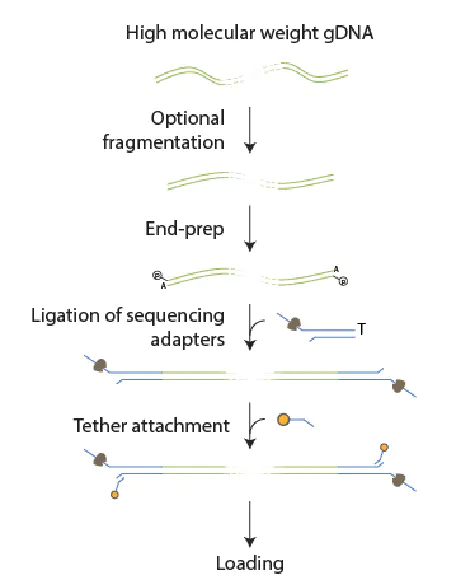
1.3 建库方法
1D文库测序,第1条DNA链测完以后,第2条链会脱离,后面也会测到,但是不会和第1条链对应上。
1D²文库,第1条DNA链测完以后,纳米孔会捕获互补链的马达蛋白进行互补链测序,但是互补链只是有一定概率能够紧接着被测序,两条链的数据相互校准,能够提高测序准确率(然并卵)。
此外, 2D的U型接头因侵权Pacbio,后弃用。
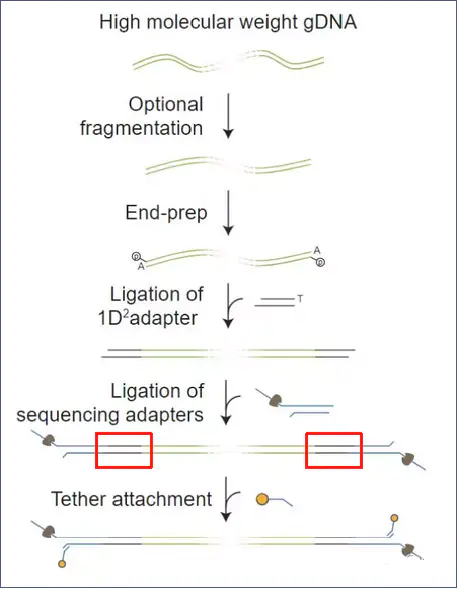
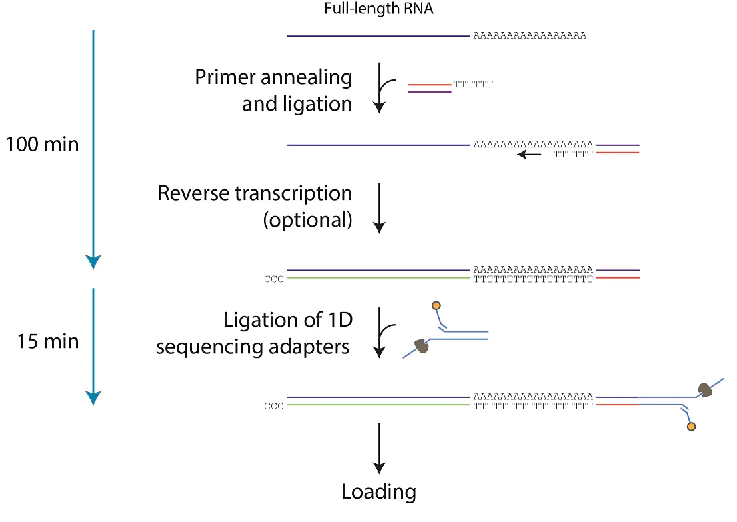
1.4 测序过程
Nanopore公司目前开发了几种测序仪:最大的是PromethION,一次可以承载48张芯片(GridIONx5,可以一次承载5张芯片;MinION,可以承载1张芯片;)
一张芯片上有2048个Mux(Mux是Multiplexer的简称)。Mux(Multiplexer)是“多路复用器”的意思。在Nanopore的芯片上,它也体现为一个物理的小孔。相邻的每 4个Mux形成一个小组。这一个小组的4个Mux共享一个信号放大器(Amplifier)。
一张芯片上有512个信号放大器,对应于512组Mux。在测序之前,机器会先把所有的Mux都通一下电,预测试一下。预测试完毕之后,机器就会知道每个小组当中,哪个Mux是最好的;哪个Mux是第二好的,再哪个是第三好的,哪个是排第四的。
在测序的时候,机器会先用每组当中最好的那个Mux进行测序;运行8小时之后,换第二好的那个Mux,再测序8小时,然后再换;依此类推,直到4批Mux都用完。(在测序的过程当中,目前一开始是先用180毫伏的电压。然后每10分钟,要短时间地颠倒一下电压的方向,让电流短时间地反向走一下。这样做,是为了激活一些被堵住的、或者被卡住的Pore(蛋白质小孔),让这些Pore能够重新工作。这样颠倒电压,也可能会让部分已进入Pore、但还没有走完的DNA链被吐回去。)
目前R9的芯片上,DNA链在Pore当中穿过的速度大约是每秒250个的碱基。所以10分钟能够测到全长为15万个碱基的一条单链(250 * 60 * 10 = 150,000)。
R9的芯片,开始测序的时候,是用180毫伏的电压。测序每进行2小时,要增加5毫伏的电压。这样做的原因是随着电极被用的时间越来越长,电极上的电压就会发生漂移。所以每2个小时,要增加5毫伏的电压来进行弥补。
Nanopore建议严格控制测序芯片的温度保持在34℃。
在实际的测序过程当中,并不是每个Mux都是有用的。据Nanopore公司公布的数据,2048个Mux当中,正常情况下会有1200个左右的Mux能够正常工作。
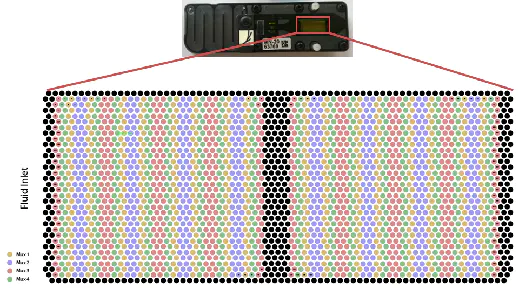

您将看到通道在捕获一条链(变为亮绿色)时闪烁,并在下一条链之前短暂返回到空状态(深绿色)。 您可能还会注意到一些pore偶尔会变成Recoving(深蓝色),这是正常行为,软件会在可能的情况下自动重新激活它们。
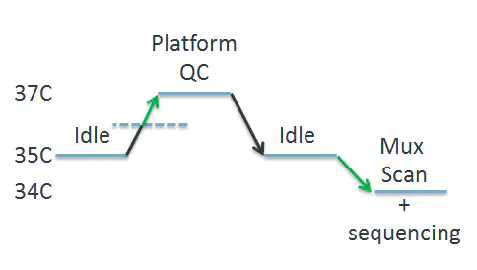
其概括为:
- Platform QC
- 散热片温度控温34℃
- 纳米孔使用情况
- 测序直方图
- Local basecalling
1.5 碱基判读
Nanopore的碱基判读是一个复杂的工作。
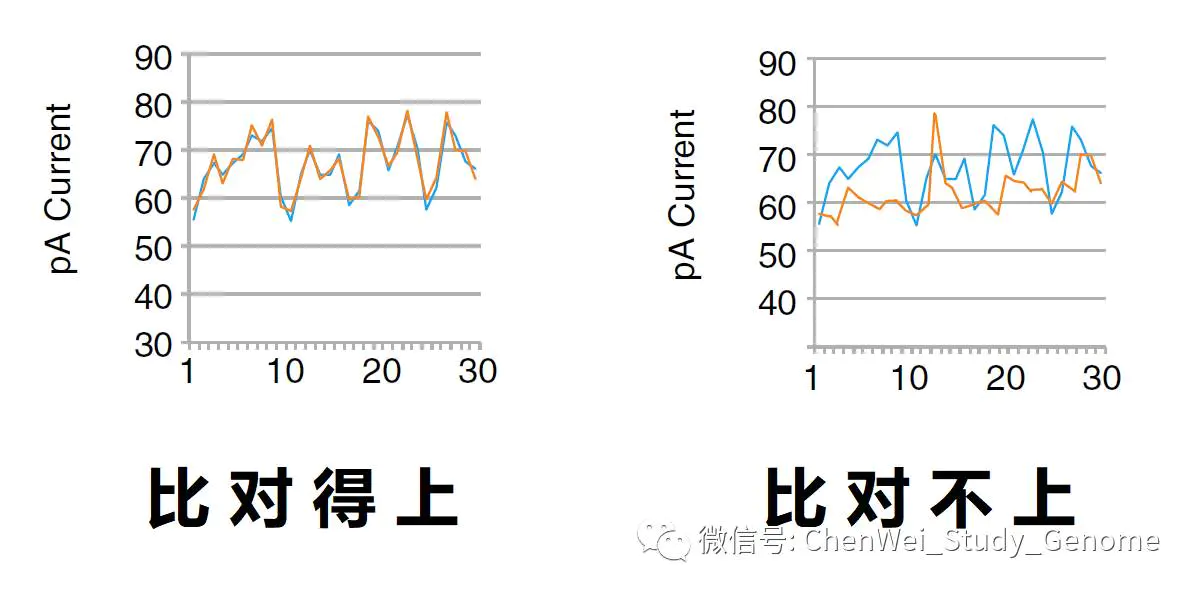
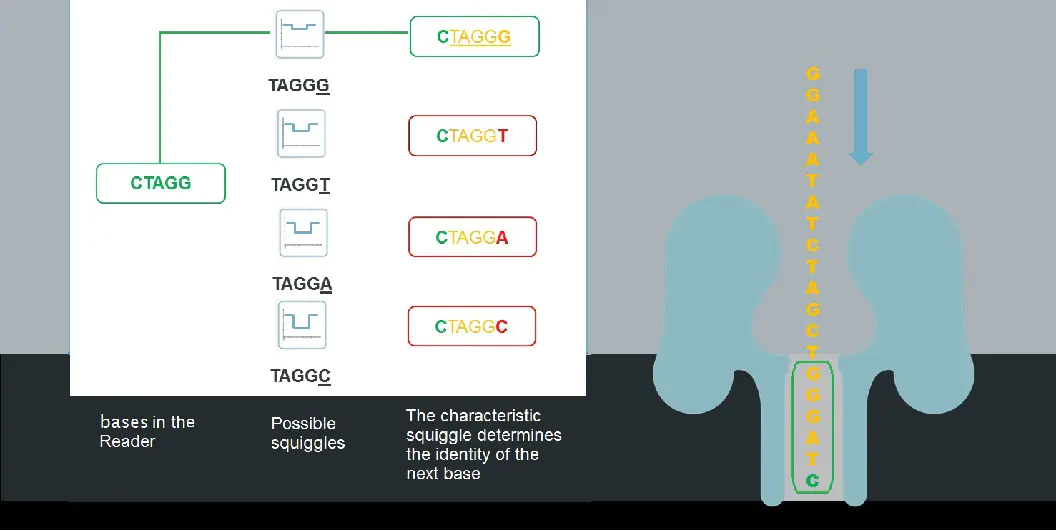
因为目前蛋白Pore狭窄处的纵向长度,对应的是DNA单链上大约5个碱基的长度。所以在某一个时间点测到的电流信号,是这5个碱基共同作用的结果,而不是单个碱基的作用结果。这样就导致要从电流信号来判读碱基序列是一个复杂的过程。
目前Nanopore做碱基判读的算法 ,是既观察电流的大小,又观察电流大小的变化。通过机器学习的得到的复杂算法对碱基进行判读。
所谓的“机器学习”,大家听了也许会觉得特别深奥。我用通俗的话来说,就是“经验拟合”。
DNA分子通过pore时的电流变化统计,五个碱基为一组信号,获取电流大小及电流变化的波形图,通过软件的参数修正,与数据库中已知序列的波形图进行比对,对碱基进行判读。
把各种已知的碱基序列会给出的信号波形图,做成一个“图形库”。将新测到的未知序列的波型图,与现有的波形图库的去做比对,看哪个波型是比得上的。比对得上,那大体上就是那几个碱基。
在比对的同时,再加上许多的修正参数,以提高比对的准确性。而这些修正参数,是拿大量的已知序列、和测到的波型图进行对照。经过反复试错、加上统计分析,得到的一系列优化值。用软件程序,通过试错、和统计,得到这些修正参数值的过程,就是“机器学习”。
目前ONT的碱基判读,可以达到约85%~90%及以上。
1.6 数据处理
ONT的下机数据格式为fast5,需要通过basecalling相关软件,转化为fastq。basecalling软件ONT服务器自带,同时在不断更新中,有albacore、guppy、flip-flop等。
bascalling完的fastq数据,可进一步通过测序质量值过滤(官方推荐qual >7 or 11).
质控后的数据可经过minimap2、ngmlr等长序列比对软件和基因组进行比对。
数据通量:保守来说,R9芯片的通量在40~70G左右;reads num在4M~7M不等,经过qual过滤在2~5M 条。
1.7 主要优势
-
长读长:Reads可达Mb;MinION用户迄今为止报告的最长读取长度为>4 Mb。
-
设备成本低:测序芯片可清洗再生,重复利用;
-
实时获得序列信息:最快可在1小时内完成测序流程及数据分析,满足动态检测宏基因组需求;
-
便携式测序装置:重量轻且占用空间小,可以随身携带随时测序;
-
直接测序:直接测序原始DNA和RNA,不需要进行PCR扩增,避免了扩增偏好性;保留了原始碱基修饰信息,能够直接读出甲基化的胞嘧啶。
三、应用
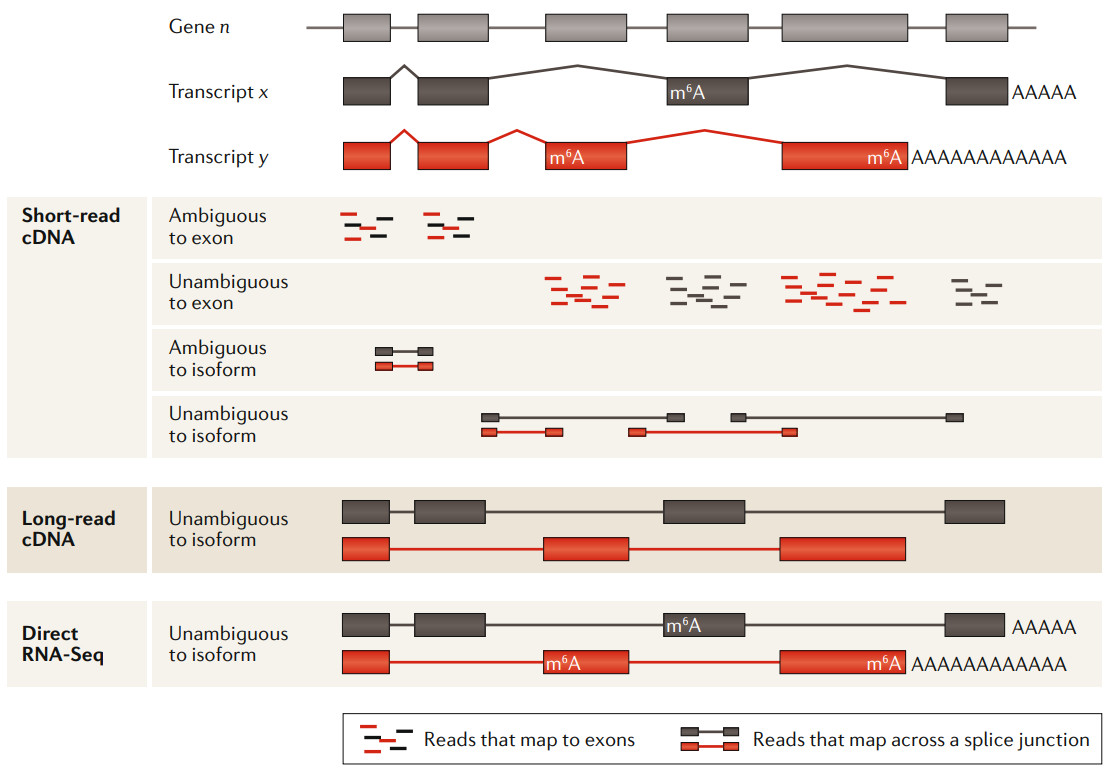
短读长、长读长与ONT直接RNA测序分析的比较
3.1 直接RNA测序无需PCR,没有测序GC偏好性
由于PCR 过程具有GC偏好性,对GC含量过高或过低的序列不容易扩增,所以短读长测序在建库和测序过程中都会引入GC偏好,降低了定量分析的准确性。使用ONT测序技术(直接 cDNA & 直接 RNA),无需PCR扩增,提供无偏倚、全长、链特异性的RNA序列。
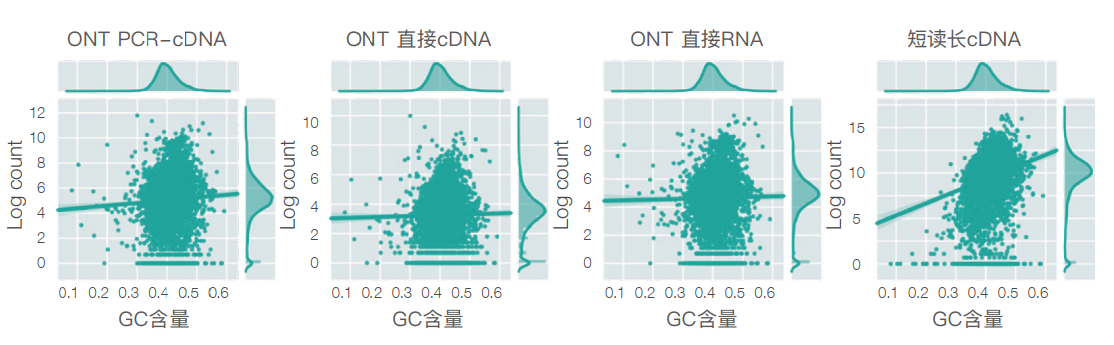
纳米孔数据集里的GC偏倚低于短读长数据集
3.2 准确检测转录本 poly(A)尾长度
转录本 poly(A) 尾被认为在转录后调控中起到重要作用,包括mRNA的稳定性和翻译效率。poly(A)尾长度可达数百个核苷酸,使用短读长测序的数据很难进行测量。ONT直接RNA测序获得的全长转录本包含poly(A)尾信息,利用算法工具计算出poly(A)尾的长度,估算每个读长序列的poly(A)尾长,甚至能够发现异构体间poly(A)尾的区别。
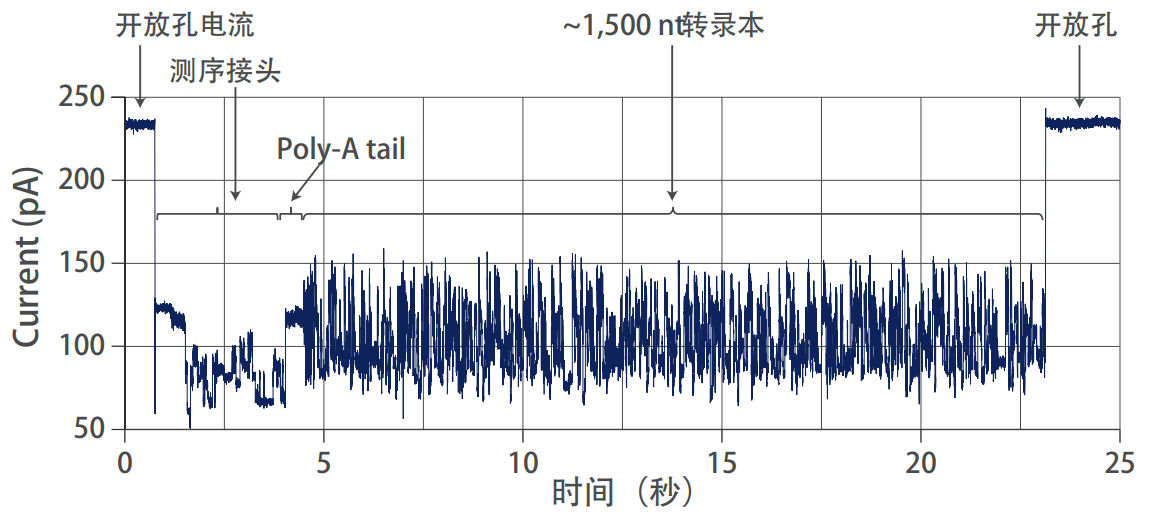
Nanopore 直接 RNA 测序鉴定转录本 poly(A)尾长
3.3 直接 RNA 测序鉴定 RNA 碱基修饰信息
短读长测序由于在建库过程需要 PCR,从而丢失了 RNA 分子中的碱基修饰信息。直接 RNA 测序不需要扩增或链合成,这意味着在测序过程中,修饰碱基直接穿过纳米孔,在原始信号中产生与未发生修饰的碱基不同的电流特征。通过特定的软件算法对电流特征进行识别,即可鉴定碱基修饰信息。
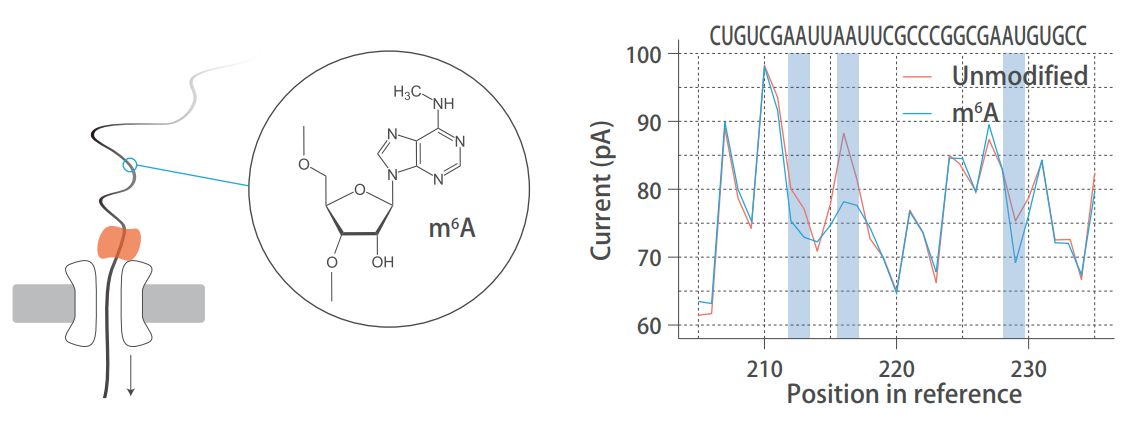
Nanoproe 直接 RNA 测序检测天然 RNA 修饰
参考资料
- https://www.jianshu.com/p/fd35555e000b
- https://www.grandomics.com/k_j_f_w/j_c_k_y_f_w/z_l_z_x_y_j/nanopore_z_j_rna_c_x/
- https://www.jianshu.com/p/fd35555e000b
- https://baijiahao.baidu.com/s?id=1712315457131273709&wfr=spider&for=pc
- https://new.qq.com/omn/20220210/20220210A01EJS00.html
- https://cloud.tencent.com/developer/article/1986121
