【5】病例对照研究
一、前言
日本电影《典子》
一个艺术家的成长经历,一个失去双臂的姑娘自强不息的故事。
- 导演: 松山善三
- 主演: 辻典子,渡边美佐子,三上宽
- 上映年度:1981年
反应停与短肢畸形之间存在因果关系吗?
Individual-Based Approach: Cases
个体思维(一维空间):发病人数
Numerator(分子) :4人患病
Population-Based Approach:Incidence Rate
群体思维(二维空间):发生率
Causality: Relative Risk因果思维(三维空间):相对危险度
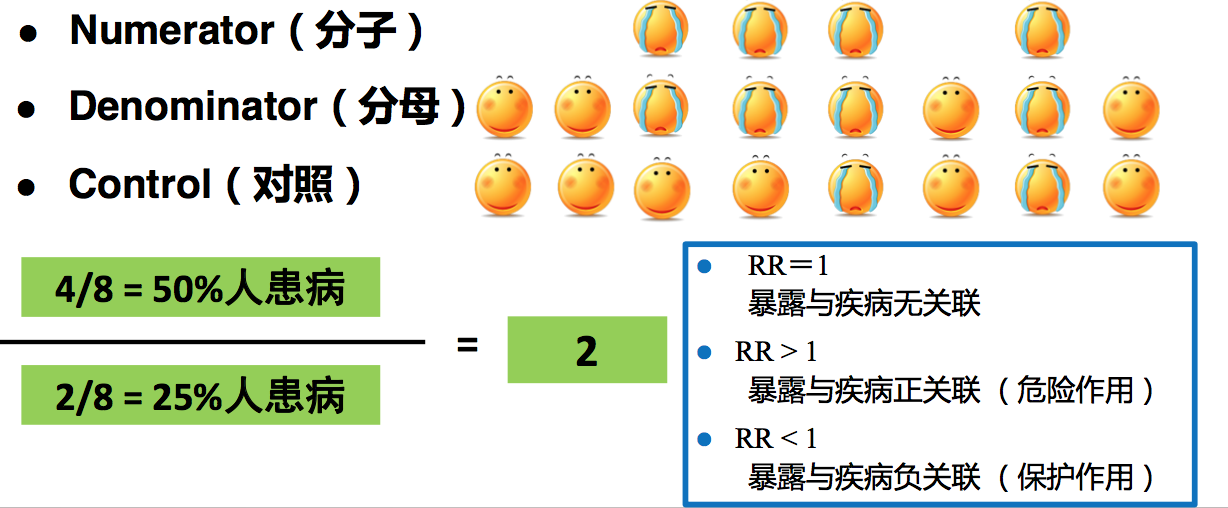
Causality: Relative Risk 因果关系的流行病学表达:相对危险度

1963年,Weicker H等报告了他们的一项回顾性研究。他们调查了200个病例的母亲和300个健康婴儿的母亲,发现病例的母亲年龄比对照者的母亲年龄大。病例死亡率增高,有较多的流产与死产。病例者母亲是医师、教师和工程师等比对照者为多。在分析病因方面,排除了放射线、避孕药、堕胎药、去污剂等因素,只有反应停有意义。
病例对照研究
Case-control study
Source: Weicker H et al (1962): Dtsch med Wschr. 87:1593
二、定义
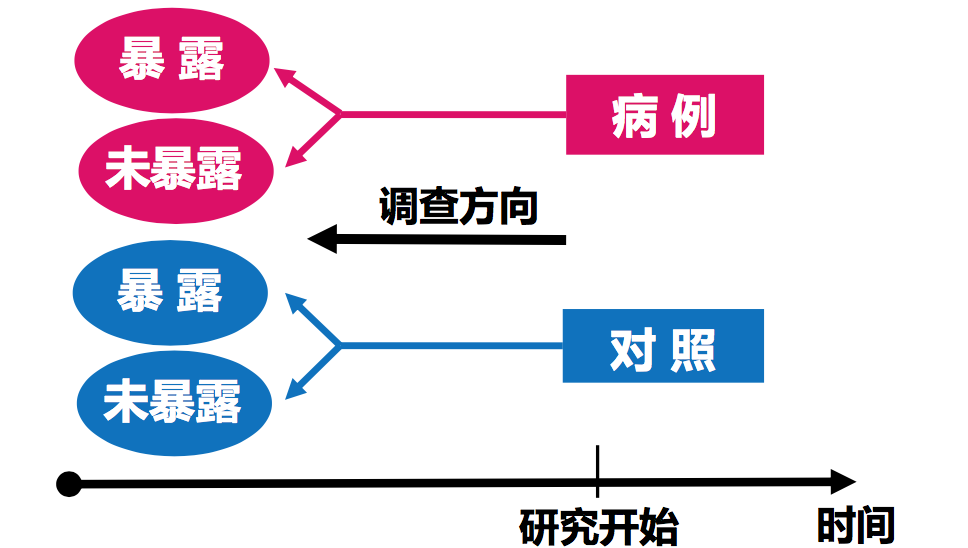
定义: 在疾病发生之后,以现在患有该病的病人为一组(病例组),以未患该病但其它条件与病人相同的人为另一组(对照组),通过询问、体检化验或复查病史,搜集既往各种可疑致病因素的暴露史,测量并比较两组对各种因素的暴露比例,经统计学检验若判为有意义,则可认为 因素与疾病间存在着统计学关联,在估计各种偏性对研究结果的影响之 后,再借助病因推断技术,推断出危险因素,而达到探索和检验病因假说的目的。
暴露 (exposure) 的定义
- 指研究对象曾经
- 接触过某些因素:物理因素、化学物质、生物因素
- 具备某些特征:人口学特征、遗传
- 处于某种状态:心理、精神
暴露因素可以是有害的,也可以是有益的。暴露因素也叫研究变量。
病例对照研究示意图
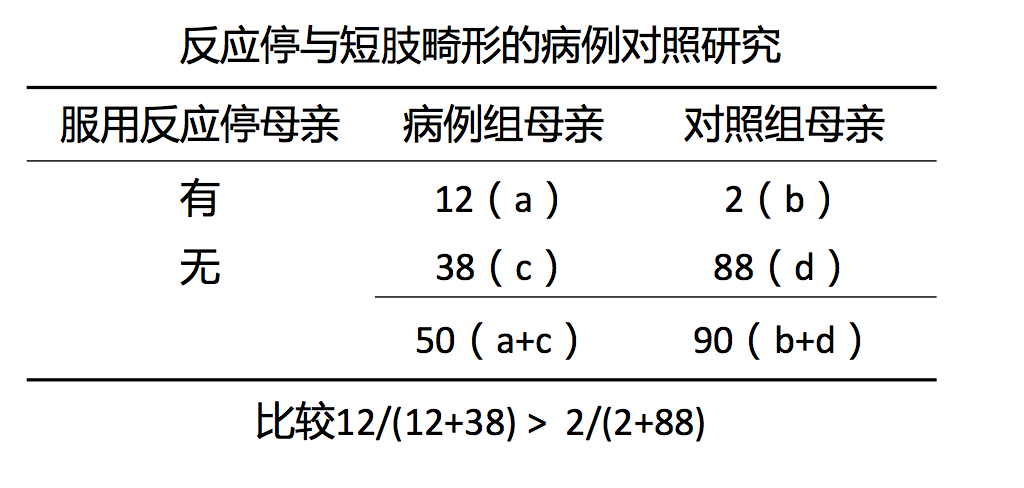
病例对照研究实例:
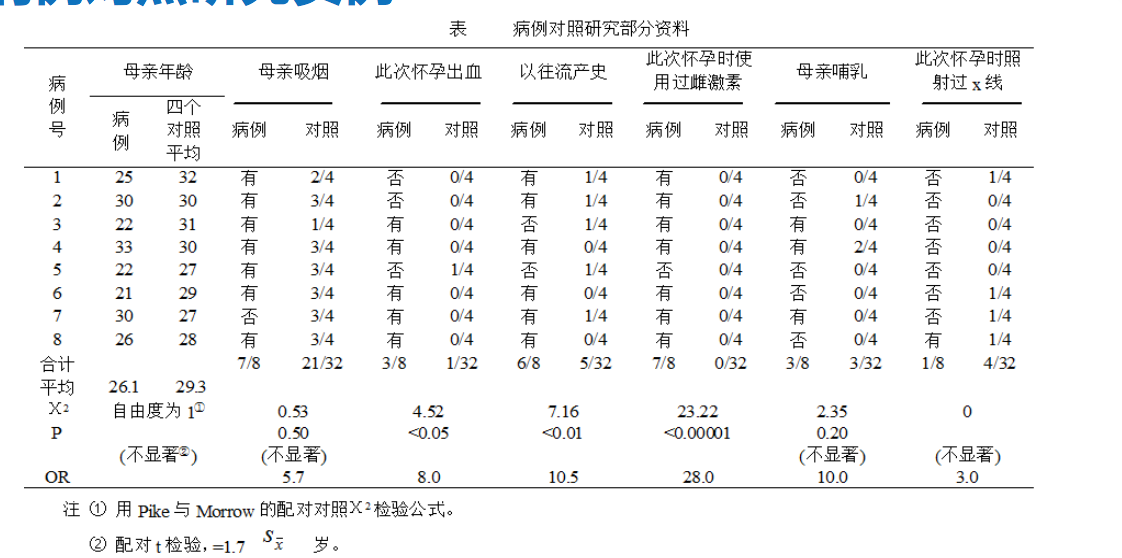
用途:
- 探索病因——筛选危险因素
- 检验假说
三、病例对照研究的主要实施步骤
主要实施步骤:
- 明确研究目的
- 确定研究对象
- 收集资料
- 偏倚(Bias)及其控制
- 资料整理与分析
- 结果的解释
3.1 明确研究目的
病例对照研究可用于检验暴露和疾病之间的联系。
3.2 确定研究对象
- 病例与对照的选择(单独章节)
- 样本量的计算(单独章节)
3.3 收集资料
选择研究因素
- 根据研究目的确定研究变量
- 每个变量均需明确定义 公共卫生学院
资料来源:
- 问卷
- 记录
- 测量
3.4 资料整理与分析
(一)整理:再核查 分组、归纳,或编码、入机
(二)分析
- 描述性分析:描述一般特征 均衡性检验
- 推断性分析:
3.5 推断性分析思路
整理四格表
病例对照研究资料整理表
| - | 病例 | 对照 | 合计 |
|---|---|---|---|
| 有暴露 | a | b | a+b=n1 |
| 无暴露 | c | d | c+d=n0 |
| 合计 | a+c=m1 | b+d=m0 | n |
- 检验两组暴露率是否有统计学差异
- 计算关联强度(比值比,OR)
- 计算关联强度的可信区间
- 分层分析
- 剂量反应关系分析
3.6 偏倚 (Bias) 及其控制
在流行病学研究过程中,由于人为原因使所得结果与 真实情况存在系统误差,即偏倚。一般有三类偏倚
- 选择偏倚 (selection bias)
- 信息偏倚 (information bias)
- 混杂偏倚 (confounding bias)
3.7 结果的解释:
- 偏性的作用
- 机会的作用
- 因果关系推断
小结
优点: 省钱、快速、筛检多种因素、适于罕见病
缺点: 偏性、暴露与疾病的时间顺序难判断、不能估计率
四、病例与对照的选择
病例与对照选择的基本原则:
- 代表性
- 可比性
选择方法:
- 抽样
- 匹配
病例的选择:
定义:内、外部特征的限定
- 对疾病的规定: 采用国际或国内统一的诊断标准。
- 对病例其他特征的规定: 如性别、年龄、民族等。
类型:
- 新发病例
- 回忆偏倚小
- 代表性好
- 容易合作
- 被调查因素改变少
- 现患病例
- 死亡病例
来源:
- 医院: hospital-based case control study
- 比较合作
- 资料易得到且比较可靠
- 与对照的可比性好
- 代表性差
- 社区人群:community-based case control study
- 代表性好
- 工作开展比较困难
- 耗费人力物力
对照的选择
定义: 理想的对照应当从源人群中抽取,代表的是整个源人群 (source population)。
类型:
- 不匹配 (无条件):成组对照
- 匹 配 (有条件)
- 频数匹配(成组匹配)
- 个体匹配(1:1 配对 / 1:M 配比)
匹配:
- 匹配 (matching) 定义
- 匹配原则
- 匹配因素确定:最常见的因素
- 混杂因素
- 复合变量
- 年龄、性别最常见
- 匹配过头 (overmatching)
来源:
- 医院: 医院中患有其他疾病的病人
- 人群: 研究的总体人群或抽样人群
- 特殊: 亲属、邻居、同事、同学等
以社区为基础的和以医院为基础的病例对照研究各自的相对优点
| 以社区为基础的病例对照研究 | 以医院为基础的病例对照研究 |
|---|---|
| 可以较好地确定源人群 | 研究对象的可及性好 |
| 容易保证病例和对照来自于同一源人群 | 研究对象更易合作 |
| 对照的暴露史更可能反映病例源人群的暴露情况 | 比较容易从医疗记录和生物标本收集暴露信息 |
六、病例对照研究样本量的计算
决定样本大小的四个条件:
- Po :一般(对照)人群中所研究因素的暴露率
- OR:相对危险度
- 𝜶 :I型错误,显著性水平,5%
- 𝜷:II型错误,把握度(1-𝜷),80%
计算方法: 公式法或查表法
样本量的计算的工具:
- EpiCalc 2000
- NCSS-PASS
非匹配设计:病例数与对照数相等
拟进行一项非匹配设计的病例对照研究,探讨服用某种药物与白血病的关系。预期服药者发生白血病的相对危险度为2.0,人群中 的服药率约为20%,设 𝜶=0.05(双侧),𝜷 =0.10,估计样本含量。
1:1 匹配设计
拟进行一项1:1匹配设计的病例对照研究,研究口服避孕药与先天性心脏病的关系,设 𝜶=0.05(双侧),𝜷 =0.10,对照组暴露比例为p0=0.3,估计的RR=2,估计样本含量。
- 估计的样本含量并非绝对精确的数值,仅供参考
- 样本量不是越大越好
- 病例组和对照组样本量相等时效率最高
七、推断性分析类型
7.1 不匹配不分层资料的分析
| - | 病例 | 对照 | 合计 |
|---|---|---|---|
| 有暴露 | a | b | a+b=n1 |
| 无暴露 | c | d | c+d=n0 |
| 合计 | a+c=m1 | b+d=m0 | n |
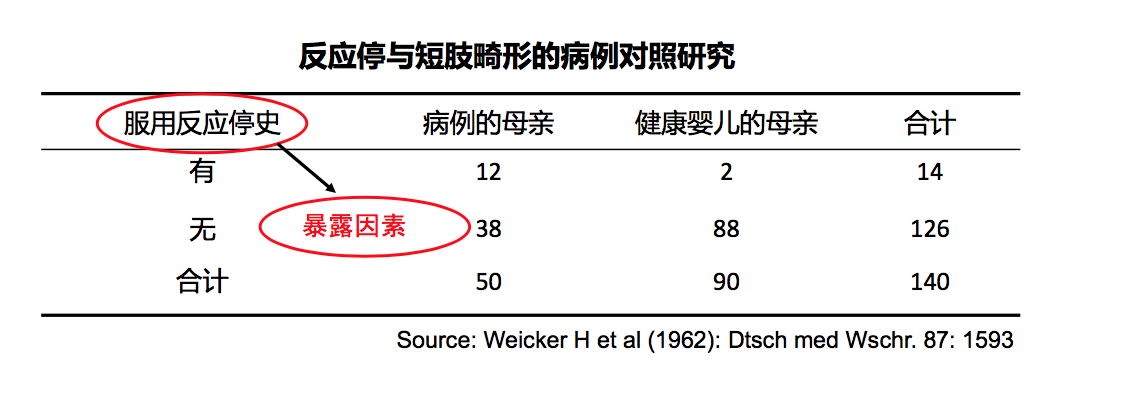
- 检验两组暴露率是否有差异,用χ2检验
- 用途:考察暴露与疾病有无统计学关联
$$ χ^{2} = \frac{(ad-bc)^{2}n}{n1n0m1m0} $$
$$ χ^{2} = \frac{(𝟏𝟐×𝟖𝟖−𝟑𝟖×𝟐)^{2}×𝟏𝟒𝟎 }{𝟏𝟒×𝟏𝟐𝟔×𝟓𝟎×𝟗𝟎} = 16.94 >10.83 𝟏𝟒×𝟏𝟐𝟔×𝟓𝟎×𝟗𝟎 $$
P<0.001 ,结论为拒绝无效假设,即两组暴露率差异有统计学意义。
计算关联强度:考察关联强度的大小
相对危险度 (Relative Risk, RR):即暴露组发病率与非暴露组发病率之比
RR = I1 / I0
比值比 (Odds Ratio,OR):病例对照研究中常常得不到发病率,因此只能用 RR的估计值 OR值来考察关联强度的大小
比值:某事件发生概率与不发生概率之比
- 暴露组患病比值 (a/𝒏𝟏)/(b/𝒏𝟏) = 𝒂/𝒃
- 非暴露组患病比值 (𝒄/𝒅)/(𝒅/𝒏𝟎) = c/d
—比值比: 𝐎𝐑 = (𝒂/𝒃)/(𝒄/𝒅) = 𝒂𝒅/𝒃𝒄
OR数值的意义:
- OR=1 暴露与疾病无关联
- OR > 1 暴露与疾病正关联,危险作用
- OR < 1 暴露与疾病负关联,保护作用

𝑶𝑹 = (𝟏𝟐×𝟖𝟖)/(𝟐×𝟑𝟖) = 𝟏𝟑.𝟗
OR的95%可信区间:2.8-131.2
即:有服用反应停史的母亲生育短肢畸形儿的风险,是没有服用反应停史的母亲的13.9倍!
7.2 匹配资料的分析
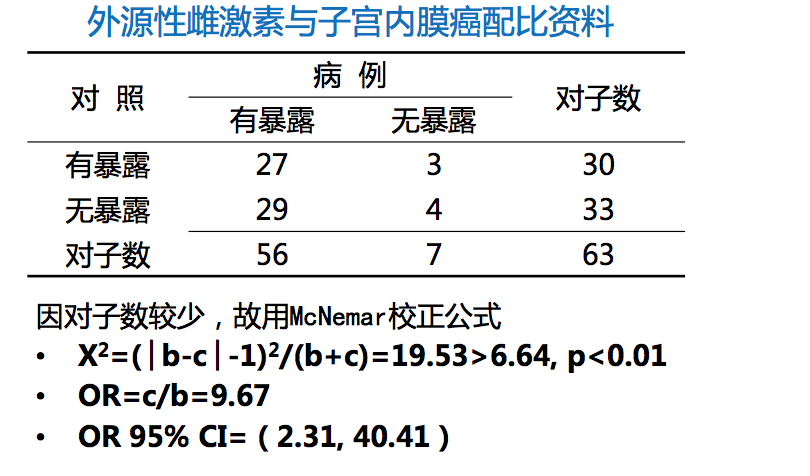
匹配资料(1:1配对资料)

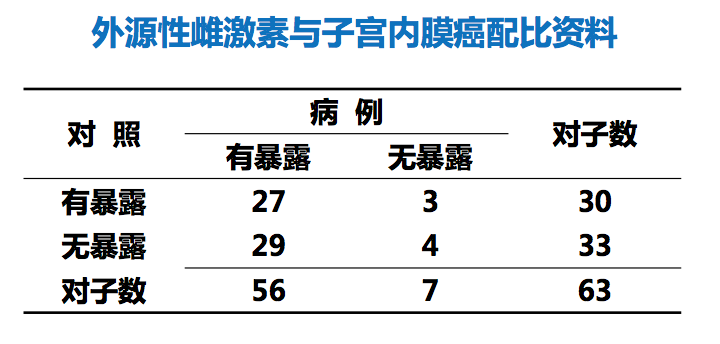
χ2检验McNemar公式:
$$ χ^{2} = \frac{(b-c)^{2}}{b+c} $$
矫正公式:
$$ χ^{2} = \frac{(|b-c|-1)^{2}}{b+c} $$
比值比: OR= c/b
7.3 偏倚 (Bias)
偏倚的流行病学定义:
在流行病学研究过程中,由于人为原因使所得结果与真实情况存在系统误差,即偏倚。
“Any systemic error in design, conduct or analysis of a study that results in a mistaken estimate of an exposure’s effects on the risk of disease. ”
Schlesselman JJ. Case-control studies: design, conduct, and analysis.Oxford University Press, New York; 1982.
偏倚的三种类型:
- 选择偏倚 (selection bias)
- 信息偏倚 (information bias)
- 混杂偏倚 (confounding bias)
选择偏倚
1.来源:选择偏倚是指研究设计阶段,选择研究对象的方法有问题,使入选者与落选者在某些特征上具有系统差异。
2.影响:降低研究的外部真实性
3.常见类型:
- 入院率偏倚 (admission rate bias/ Berkson bias)
- 存活病例偏倚 (prevalence-incidence bias/ Neyman bias)
- 检出征侯偏倚 (detection signal bias)
- 时间效应偏倚 (time effect bias)
- 其他:无应答偏倚、选择性转诊偏倚
Berkson bias:当利用医院病人作为病例和对照时,由于入 院率的不同导致病例组与对照组某些特征上的系统差异。
Neyman bias:从现患病例得到的很多信息可能只与存活有 公共卫生学院 关,而未必与该病的发病有关,从而高估了某些暴露因素的 病因作用。另一种情况是,某病的幸存者改变了生活习惯, 从而降低了某个危险因素的水平,或当他们被调查时夸大或 缩小了病前生活习惯上的某些特征,导致某一因素与疾病关 联误差。
信息偏倚
1.定义:信息偏倚是指收集资料阶段,测量暴露或结局的方法 有缺陷,使各比较组间产生系统差异 。
由于流行病学的暴露或疾病多为分类测量,所以信息 偏倚又称错误分类偏倚(misclassification bias)。
影响:降低研究的内部真实性
2.常见类型:
- 回忆偏倚 (recall bias):是指研究对象在回忆某些因素的暴露史时,由于在准确性和完整性上的 差异所导致的系统误差。
- 调查偏倚:可来源于调查对象和调查者双方。由于病例与对照的调查环境与条件不 同;调查技术、调查质量不高或差错以及仪器设备的问题所导致。
混杂偏倚
1.定义:研究暴露与疾病的因果关系时,混入外部因素,该外部因素与疾病和暴露都有一定的关联,此外部因素即为混杂因素。由于混杂因素的存在,影响了暴露与疾病间的关联强度,由此带来混杂偏倚。
2.判断混杂因子的必要条件 :
- 必须是所研究疾病的独立危险因子;
- 必须与研究因素(暴露因素)有关;
- 不是研究因素与研究疾病因果链上的中间变量。
例如: 年龄,吸烟,肺癌
偏倚的控制
1.选择偏倚 (selection bias)
控制措施:
- 充分了解、掌握研究中可能出现的各种选择偏倚
- 严格掌握研究对象的纳入与排除标准
- 应随机选取、多医院选取、用新发病例等
2.信息偏倚 (information bias)
控制措施:
- 选择不易为人们忘记的重要指标做调查
- 重视问卷的提问方式和调查技术、培训、一致性调查等。
3.混杂偏倚 (confounding bias)
控制措施:
- 设计阶段:
- 限制:制定恰当的入选和排除标准
- 匹配:按主要的混杂因子匹配
- 分析阶段:分层分析、多元模型、倾向评分法 (Propensity scores)
八、病因与因果推断
8.1 病因
流行病学:是研究人群中疾病与健康状况的分 布及其影响因素,并研究防制疾病及促进健康的策略和措施的科学。
研究病因的重要性:
- 个体采取预防措施的基础
- 社会干预行动的基础
- 有助于了解疾病发生发展的机制
因果观的发展:
- 决定论因果观
- 一定的原因 –》必然导致–》 一定的结果
- 概率论因果观
- 原因是使结果发生概率升高的事件或特征
- 一定的原因 –》可能而不是必然 –》一定的结果
现代流行病学的病因定义:
那些能使人群发病概率升高的因素,就认为是病因,其中某个或多个因素不存在时,人群疾病频率就会下降。 ——Lilienfeld
- 流行病学层次的病因一般称为危 险因素(risk factor)
- 它的含义就是使疾病发生概率或 风险 (risk) 升高的因素。
- 概率论因果观
充分病因和必要病因:
- 充分病因(sufficient cause) 指有某个或某些病因存在,必定(概率为100%)导致相应疾病发生。
- 必要病因(necessary cause) 指有某疾病发生,以前必定(概率为100%) 有相应某个或某些病因存在。
充分病因和必要病因存在局限性,我们应当放弃对充分病因和必要病因的追求,而对病因的 充分性和必要性进行概率测量 。
病因的分类
- 宿主病因
- 先天因素:基因、染色体、性别
- 后天因素:年龄、发育、营养状态、体格等等
- 环境病因
- 生物因素:病原体、感染动物、媒介昆虫
- 化学因素:营养素、化学药品、重金属
- 物理因素:气象、地理、大气污染
- 社会因素:人口、经济、家庭、嗜好兴趣
8.2 病因模型
理解不同的病因模型:
- 生态学模型
- 疾病因素模型
- 病因网模型
生态学模型
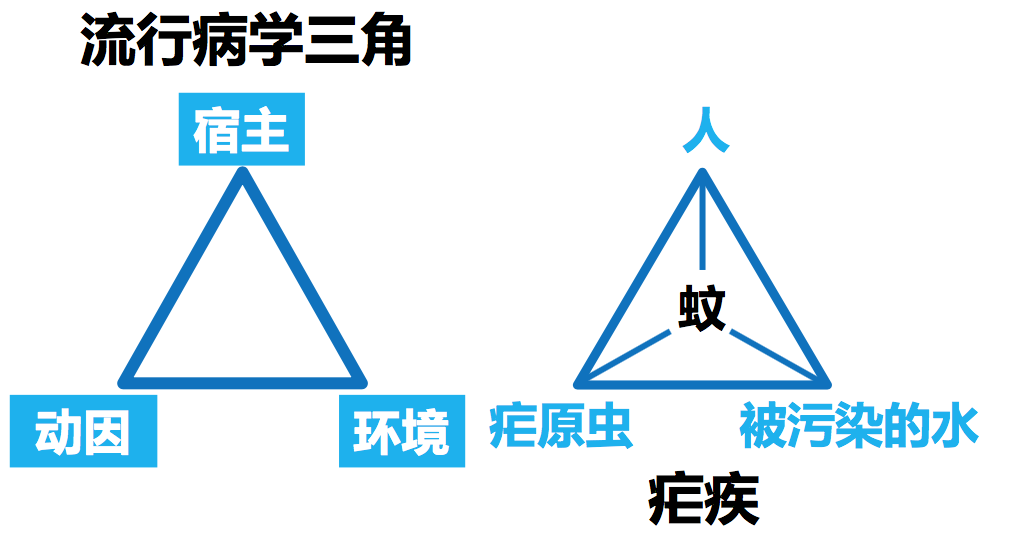
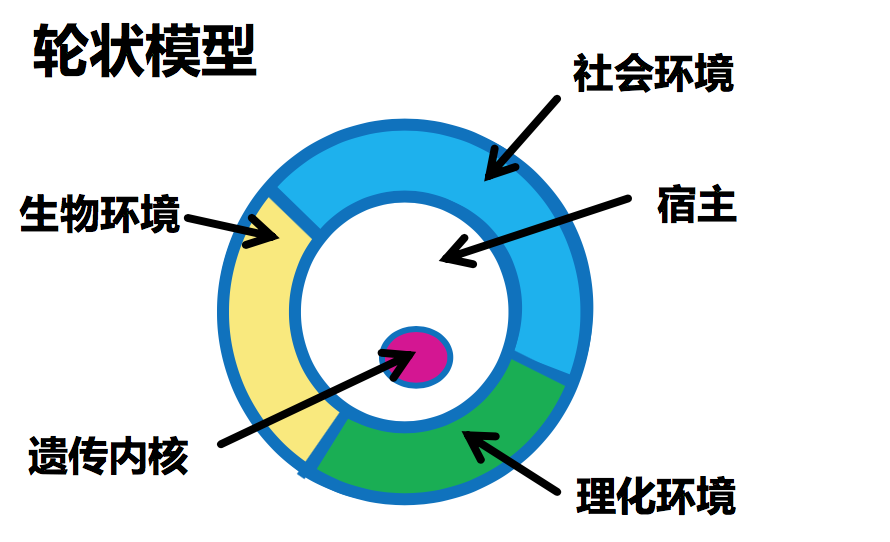
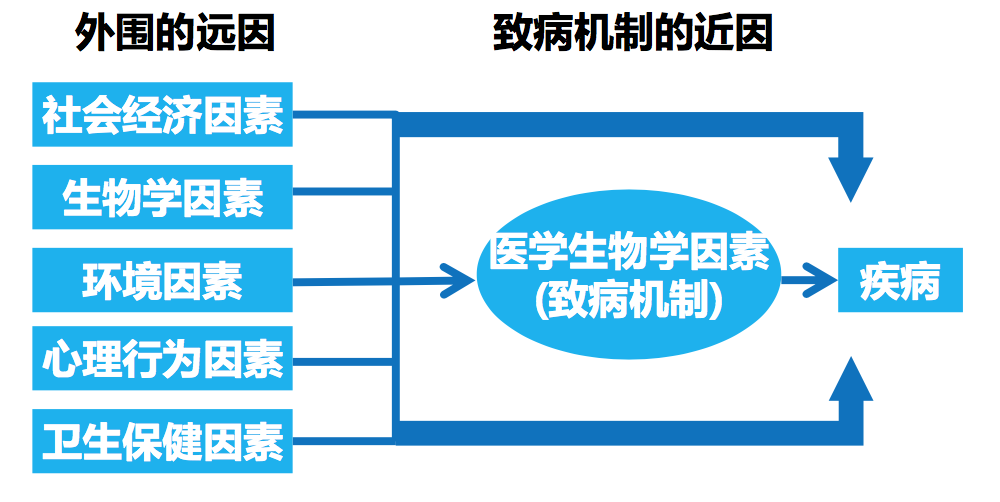
疾病因素模型
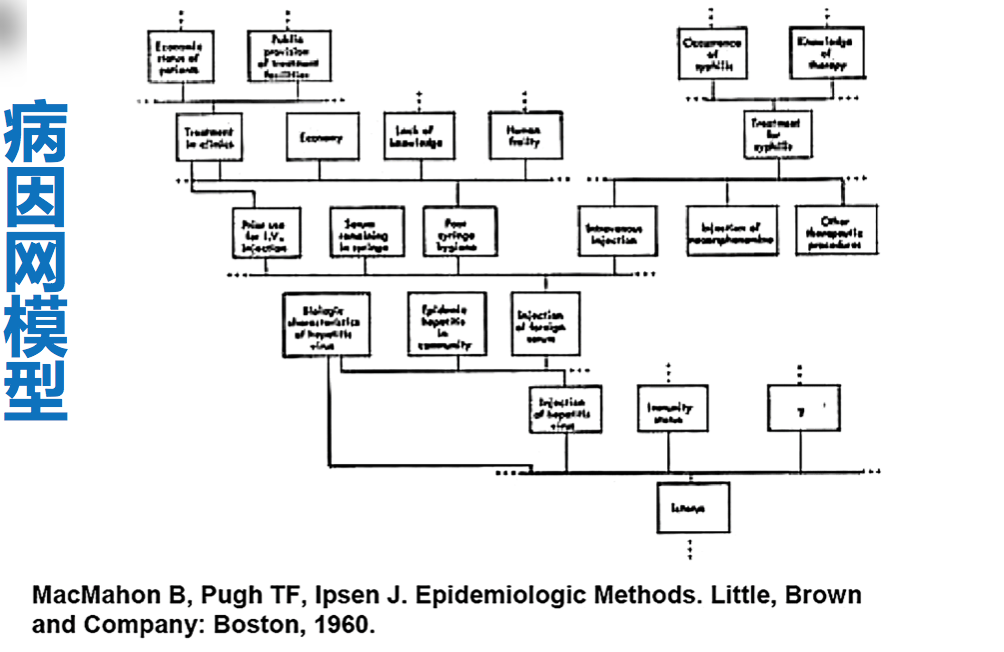
病因网模型
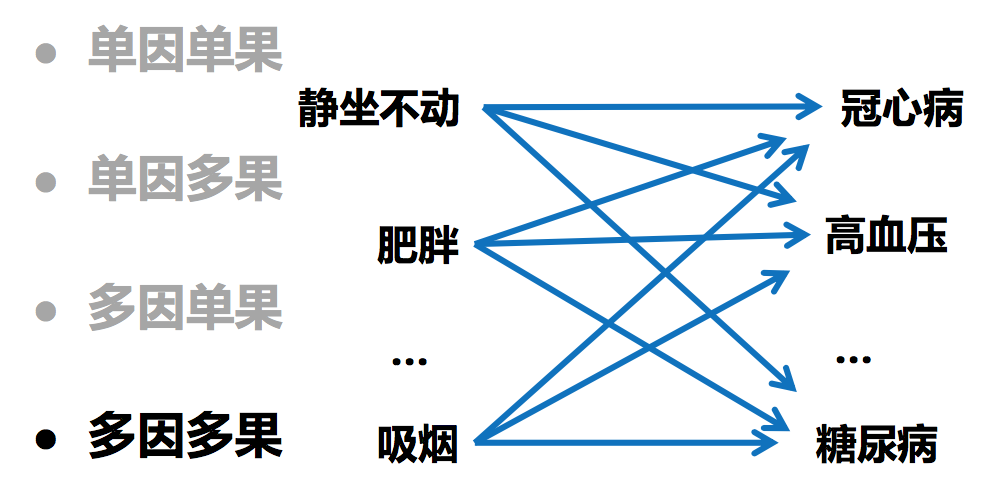
因果联接方式
8.3 因果推断的方法和步骤
8.3.1 因果推断的方法
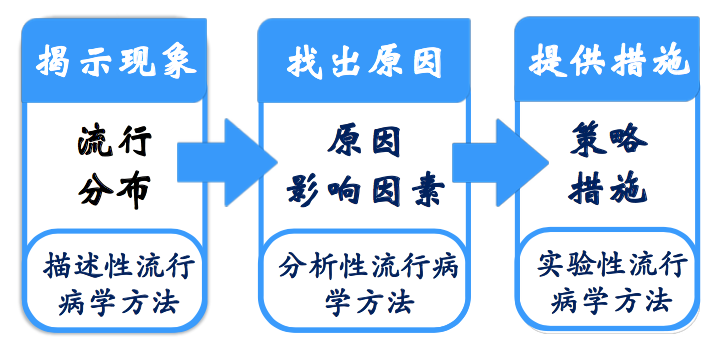
8.3.2 因果推断的步骤

8.3.3 不同研究方法因果推断的论证强度
| 设计类型 | 性质 | 可行性 | 论证强度 |
|---|---|---|---|
| 横断面研究 | 断面性 | 好 | 弱 |
| 病例对照研究 | 回顾性 | 好 | 中 |
| 队列研究 | 前瞻性 | 较好 | 次强 |
| 实验研究 | 前瞻性 | 差 | 强 |
8.3.4 因果推断的过程
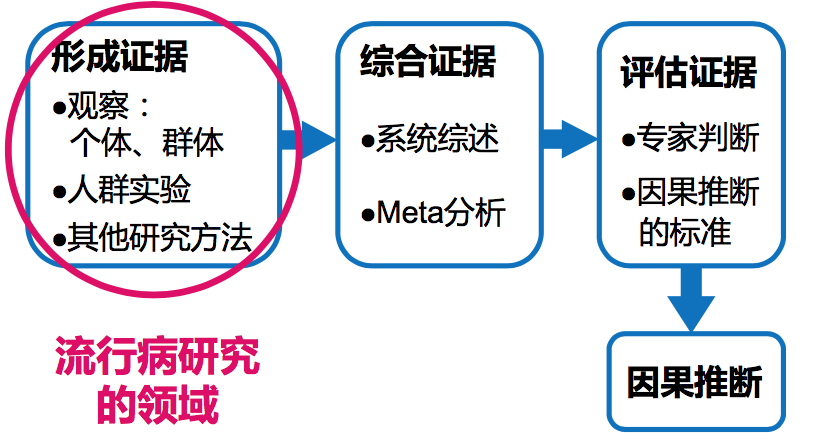
8.4 常用的因果推断标准
rules by which to judge of causes and effects” ——David Hume
8.4.1 现代因果推断标准的发展
| 提出者 | 年份 | 条数 | 标准 |
|---|---|---|---|
| 美国“吸烟 与健康报告”委员会 | 1964 | 5 | 1 关联的时间顺序;2 关联的强度;3 关联的特异性;4 关联的一致性或可重复性;5 关联的连贯性或合理性 |
| Hill | 1965 | 8 | 在上述标准基础上增加了3条: 1 剂量反应关系;2 生物学可能性(与上述5雷同) 3 实验证据 |
| 苏德隆 | 1980 | 8 | 基本同Hill标准 1 将“关联的连贯性”和“生物学可能性”合并 2 增加“分布一致性” |
| Lilienfeld | 1994 | 7 | 基本同Hill标准1 将“关联的连贯性”和 “生物学可能性”合并 |
8.4.2 常用的因果推断标准
- 关联的时间顺序 2.关联的强度
- 一般而言,关联的强度越大,该关联 为因果关联的可能性就越大 OR、RR
- 关联的可重复性
- 不同人群、不同地区、不同时间
- 关联的合理性
- 符合现有的理论知识
- 实验研究的证据
8.4.3 因果推断的例子
吸烟 ==> 肺癌
- 吸烟是否发生在肺癌之前?
- 吸烟和肺癌的关联程度有多强?
- 吸烟和肺癌的关联是否可以重复观察到?
- 有没有生物学机制可以解释吸烟和肺癌的关联?
- 有没有实验研究的证据可以证明这种关联?
参考资料:
北京大学公共卫生学院 詹思延老师的 《流行病学绪论》 课件
