few-shot
Few-shot Learning(少样本学习)是Meta Learning(元学习)中的一个实例[1],所以在了解什么是Few-shot Learning之前有必要对Meta Learning有一个简单的认识。不过在了解什么是Meta Learning之前还是要了解一下什么是Meta。因此,阅读本文后你将对如下知识有一个初步的了解。
- What is Meta
- What is Meta Learning
- What is Few-shot Learning
1. What is Meta?
meta就是描述数据的数据。
比如照片,我们看到的是它呈现出来的数据, 即Data,但它还含有许多描述它拍摄参数的数据,比如光圈、快门速度、相机品牌等,即Meta。

2. What is Meta Learning?
机器学习模型一般要求训练集样本量足够大,才能取得不错的预测效果。但对于人来说却不需要,对于一个从没有见过小猫和小狗的小朋友来说,给他几张照片他就能轻松的学会如何分辨两只动物。如果一个人已经掌握了如何骑自信车,那么学习如何骑摩托车对他来说会非常轻松。我们能否设计一个模型,让模型仅从一点点训练样本就能学会新的“知识”呢?即让模型“自己学会去学习”[1]。
举个简单的例子,一个小朋友去动物园,里面有些动物他没有见过所以不知道叫什么名字,然后你给他一些小卡片,卡片上有各个动物的照片和名称,小朋友就可以自己学习,从这些卡片中找出这些动物的名字。这里的未知动物叫做query,小卡片叫做support set。培养小朋友从小卡片中自主学习就叫做meta learning。如果一个类别的小卡片只有一张,那么就叫做one-shot learning。

Meta learning是一种学习其它机器学习任务输出的机器学习算法(有一点绕,不过理解了meta data理解meta learning就会相对容易一些)。
Machine learning algorithm从历史数据中学习知识,然后泛化到新的数据样本中。
- Learning Algorithm: Learn from historical data and make predictions given new examples of data.
而meta learning是从其它学习算法(learning algorithm)的输出中学习,这就要求其它学习算法以及被预训练过。即meta learning算法将其它机器学习算法的输出作为输入,然后进行回归和分类预测。
- Meta Learning Algorithm: Learn from the output of learning algorithms and make a prediction given predictions made by other models.
如果说machine learning是使用信息做出更好的预测,那么meta learning就是利用machine learning的预测作出最好的预测。
3. What is Few-shot Learning
3.1 Few-shot learning
Few-shot learning指从少量标注样本中进行学习的一种思想。Few-shot learning与标准的监督学习不同,由于训练数据太少,所以不能让模型去“认识”图片,再泛化到测试集中。而是让模型来区分两个图片的相似性。当把few-shot learning运用到分类问题上时,就可以称之为few-shot classification,当运用于回归问题上时,就可以称之为few-shot regression。下面所提到的few-shot learning都只针对分类问题进行讨论。
假如我们的有一个很大的训练集,包含以下五类样本,有哈士奇、大象、老虎、金刚鹦鹉和汽车。我们的目标不是让模型认出哪个是哈士奇,哪个是大象,而是让模型知道不同类别间的区别。

我们现在给模型输入一张新的图片松鼠(squirrel),模型并不知道它是松鼠,因为训练样本中没有这一种动物。但当你把两只松鼠的图片都输入到网络中,它虽然不知道它们属于松鼠这一类别,但模型可以很确信的告诉你这是同一物种,因为长得很像。

但当你输入一只穿山甲(pangolin)和一只狗(dog),模型能够区分出来它们长得不像,所以不是同一种动物。

3.2 Support set vs training set
小样本带标签的数据集称为support set,由于support set数据样本很少,所以不足以训练一个神经网络。而training set每个类别样本量很大,使用training set训练的模型能够在测试集取得很好的泛化效果。
3.3 Supervised learning vs few-shot learning
监督学习:
(1)测试样本之前从没有见过
(2)测试样本类别出现在训练集中
Few-shot learning:
(1)query样本之前从没有见过
(2)query样本来自于未知类别
由于query并未出现在训练集中,我们需要给query提供一个support set,通过对比query和support set间的相似度,来预测query属于哪一类别。

3.4 k-way n-shot support set
k-way:support set中有个类别 n-shot:每一个类别有个样本 例如下图中有四个类别,每个类别有两个样本,所以是4-way 2-shot support set
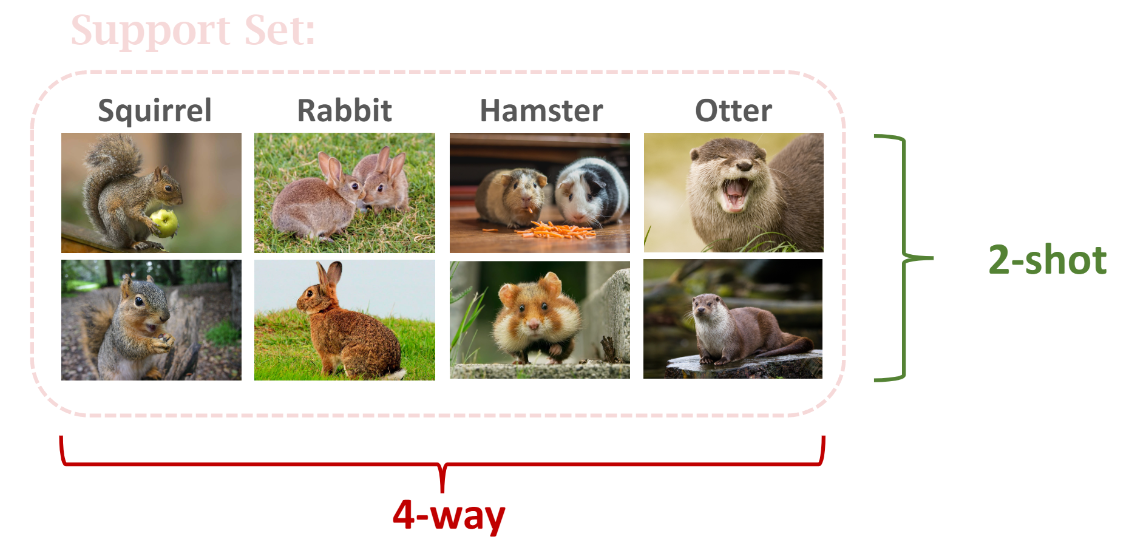
Few-shot learning的预测准确率随 #-way 增加而减小,随 #-shot 增加而增加。因为对于2-way问题,预测准确率显然要比1000-way问题要高。而对于 #-shot,一个类别中样本数越多越容易帮助模型找到正确的类别。
3.5 Basic idea behind few-shot learning
Few-shot learning的最基本的思想是学一个相似性函数:sim(x,x') 来度量两个样本x和x’的相似性。 sim(x,x') 越大表明两个图片越相似,sim(x,x') 越小,表明两个图片差距越大。
操作步骤:
(1)从大规模训练数据集中学习相似性函数
(2)比较query与support set中每个样本的相似度,然后找出相似度最高的样本作为预测类别

参考资料
