【4.3.1】抗神经网络(GAN)
GAN中有两个这样的博弈者:
- 一个人名字是生成模型(G)
- 另一个人名字是判别模型(D)
自从Goodfellow在2014年提出了对抗神经网络后在这个这个领域十分火热。GAN在过去几年里已成为深度学习中最热门的子领域之一,Yann LeCun说GAN是过去10年机器学习最有趣的想法。
- GAN简介(与图灵学习和纳什均衡的关系)
- 使用“垃圾邮件识别“进行详细说明(定义混淆矩阵,双方博弈流程)
- GAN的应用(较为轻松)
- GAN的Keras简单实现,使理解更清晰(到这里请认真一些,严肃脸)
GAN最经常看到的例子就是斑马和马的互相转换了,相信你即使不知道GAN是什么,也曾见过这个例子。

一、GAN简介
GAN的想法非常巧妙,它会创建两个不同的对立的网络,目的是让一个网络生成与训练集不同的且足以让另外一个网络难辨真假的样本。
“图灵学习”本质上可以对GAN进行概括。相关的“图灵测试”是广为人知的概念,即计算机试图与人对话并让人误以为它也是一个正常人类。“图灵测试”类似于GAN中generator(生成器)的目标,试图欺骗的是对应的‘adversary’— discriminator(鉴别器)。
GAN可以用任何形式的generator和discriminator,不一定非得使用神经网络。而神经网络被广泛使用的主要原因是它一种通用函数逼近算法(universal function approximator),即我们能够使用大量节点的神经网络来模拟任何非线性的Input与Output之间的函数,相对其他方法具有更高的自由度,不会因为算法本身的能力而受限。对于generator或discriminator没有任何形式的限制,两者的形式也不必要相同
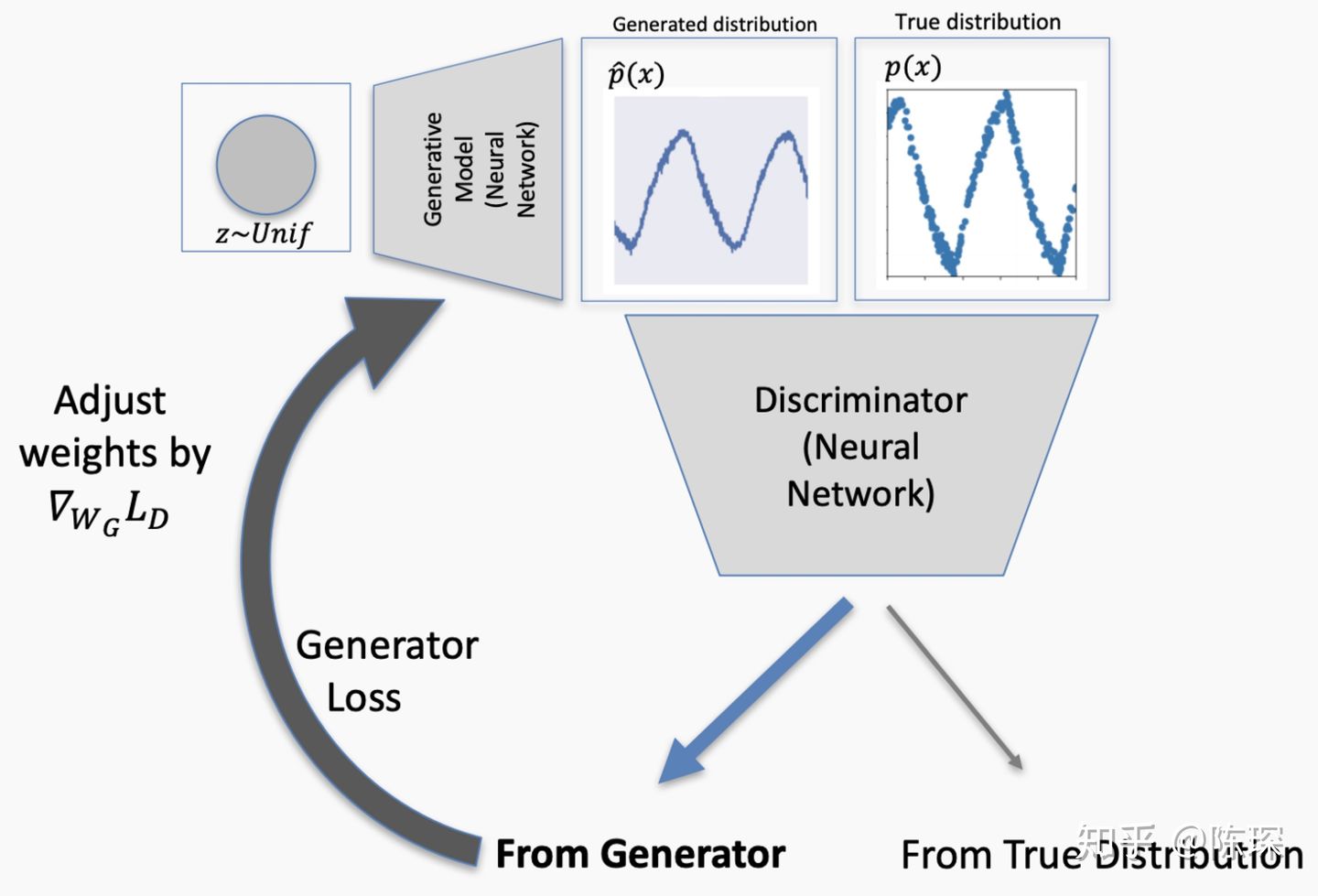
这里我们先把generator和discriminator看做两个黑盒,里面包着全能的神经网络。generator(G)的输入是noise z,输出是生成的样本G(z)。然后将生成的样本混合真实数据输入discriminator(D),discriminator进行二分类并给出一个是否为真的打分D(G(z))。

generator和discriminator的loss很大程度依赖于discriminator的好坏。G要maximizeD(G(z)), D要maximizeD(x),minimize D(G(z))。GAN的整个想法都以博弈论为基础,generator和discriminator相互对抗,最终相对于另一网络自己都处于峰值,达到纳什均衡。

可见下图描绘的是G和D在每一个epoch的Loss Function,最终平的部分即达到了纳什均衡。
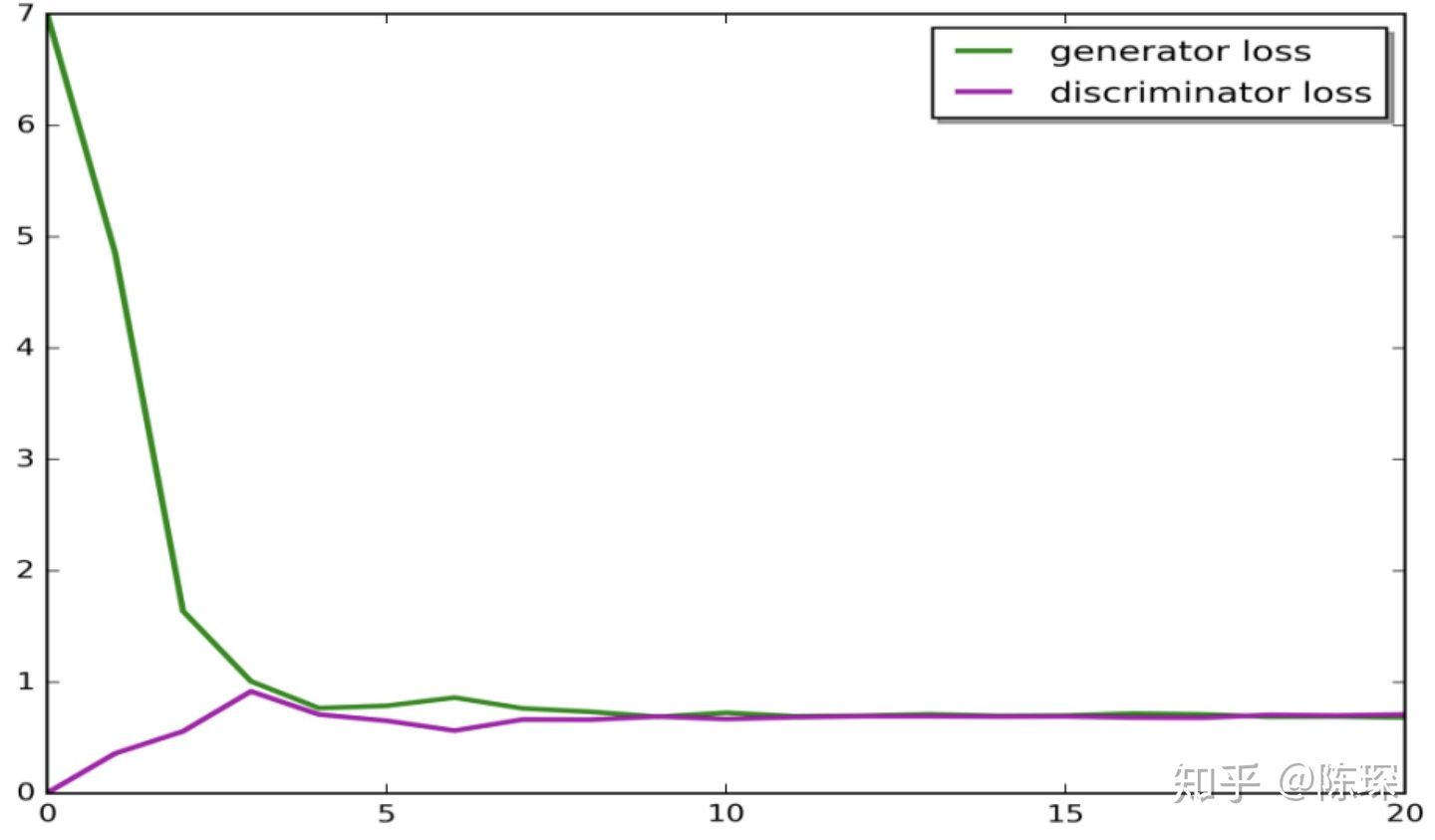
二、垃圾邮件的例子
举个邮件分类的例子来进行说明,假设有一个叫Gary的营销人员试图骗过David的垃圾邮件分类器来发送垃圾邮件。Gary希望能尽可能地发送多的垃圾邮件,David希望尽可能少的垃圾邮件通过。理想情况下会达到纳什均衡,尽管我们谁都不想收到垃圾邮件。
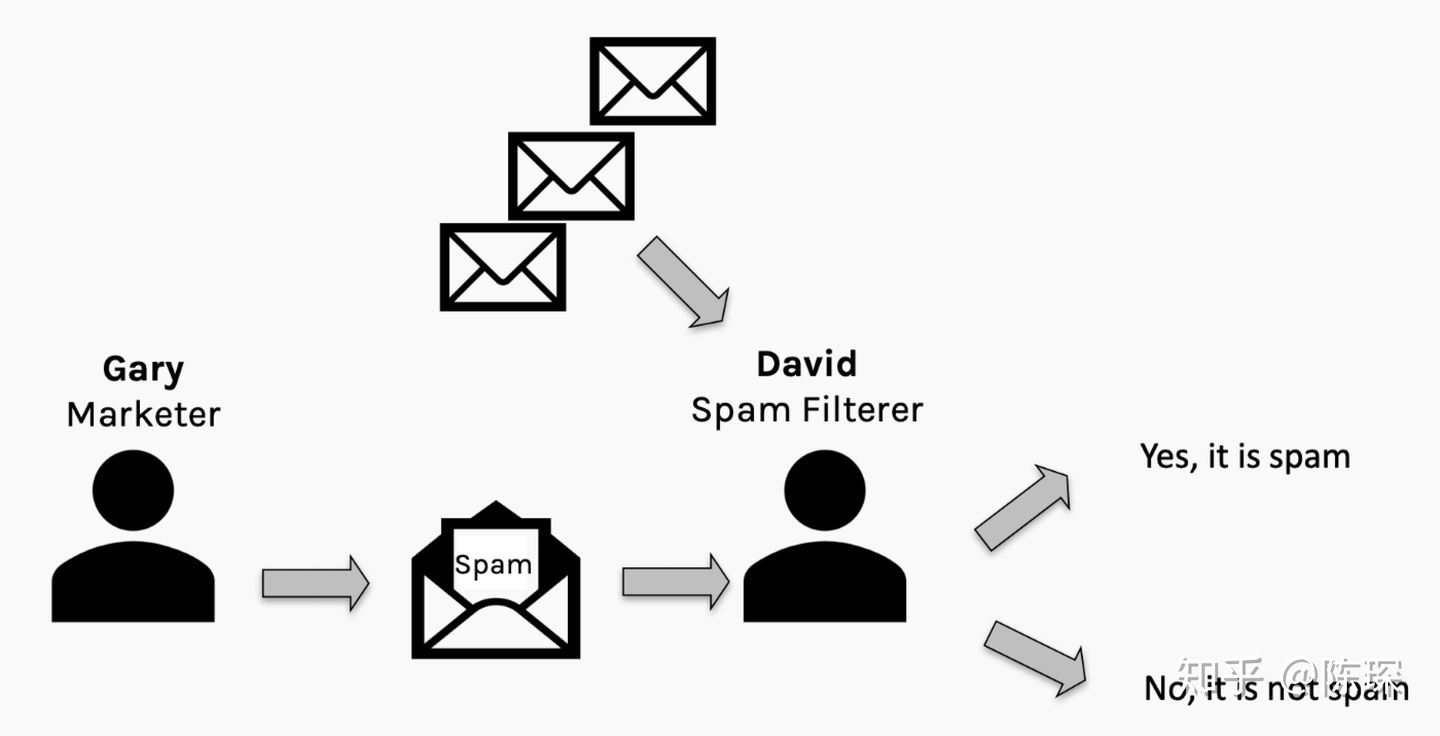
在收到邮件后,David可以查看spam filter的效果并通过”误报”或”漏报”来惩罚spam filter。
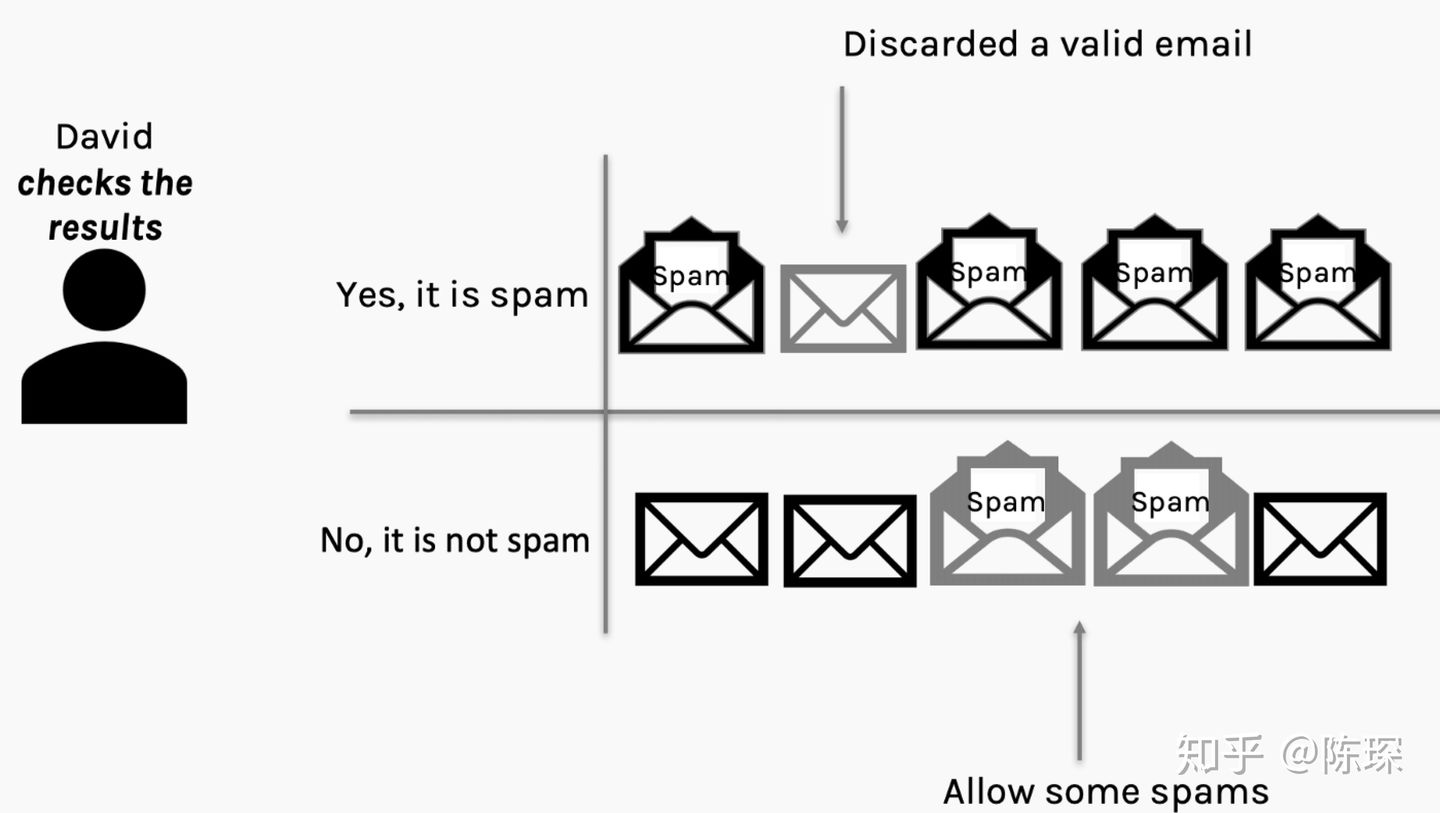
假设Gary通过自己发送给自己可以验证他的垃圾邮件哪些通过了,那么Gary和David就可以通过混淆矩阵(confusion matrix,名字听起来高大上,其实就是个表格而已)来评价自己的工作做的如何:
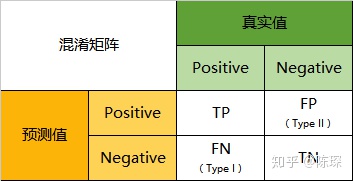
下面是Gary和David得到的混淆矩阵:

经过此之后,Gary和David都知道出了什么问题,并从错误中学习。Gary会基于之前的成功经验尝试其他的方法来生成更好的垃圾邮件。David会看一下spam filter哪里出错了并改进过滤机制。
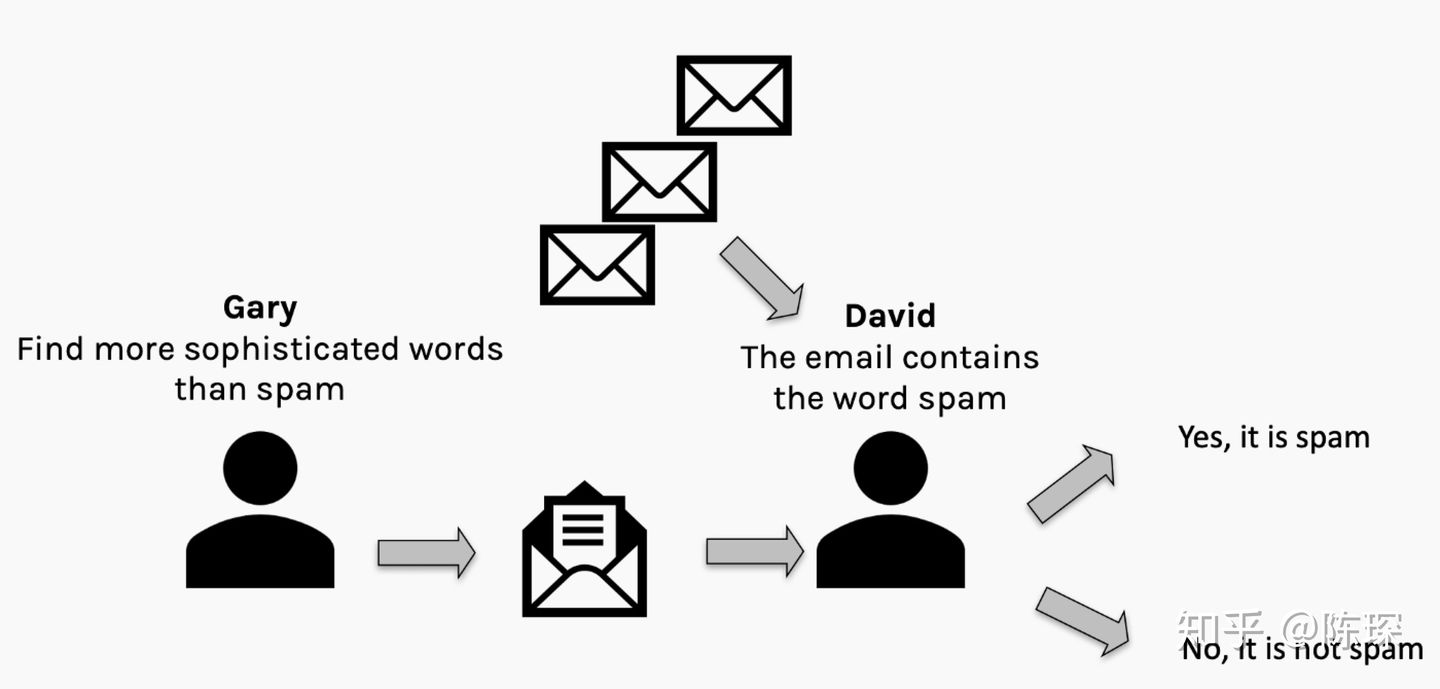
然后不断地重复这个过程,直到达到某种纳什均衡(当然,有可能最终导致模型崩溃,因为某一方找到了完美的伪装方法或者分辨垃圾邮件的方法)。
下面来详细看一下混淆矩阵的四个象限。
1.True Positive:邮件是Gary生成的垃圾邮件并且被David判定为垃圾邮件。 generator:被抓包,工作做的不够好,需要优化。 discriminator:当前不需要做什么。
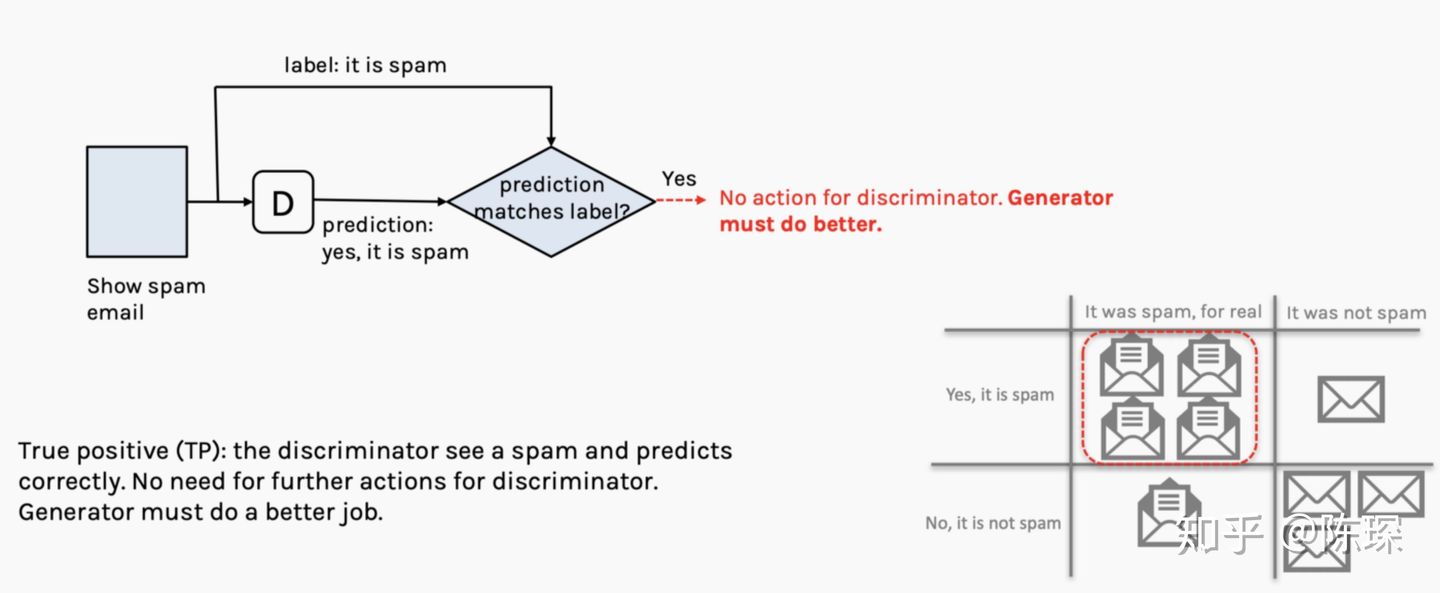
2.False Negative:邮件不是垃圾邮件,但是被David判定为垃圾邮件。 generator:当前不需要做什么。 discriminator:工作做的不够好,需要优化。
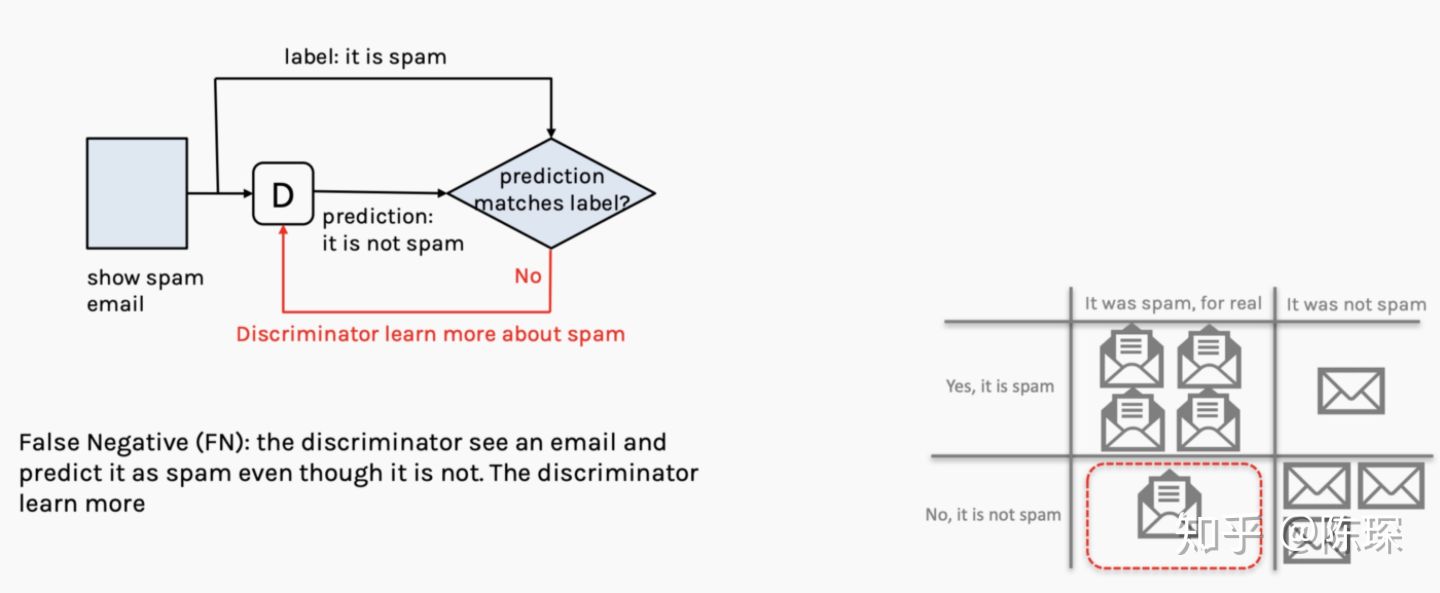
3.False Positive:邮件是垃圾邮件,但是被David判定为正常邮件。 generator:当前不需要做什么 discriminator:工作做的不够好,需要优化。
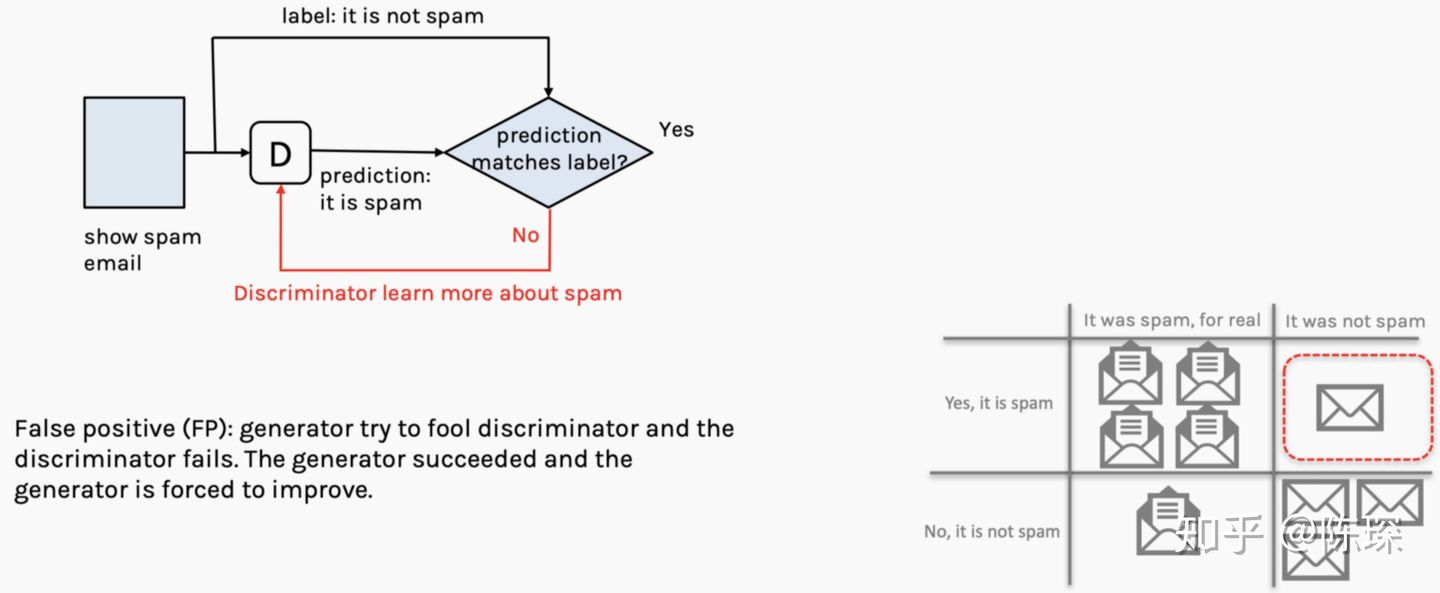
4.True Negative:邮件不是垃圾邮件,David也判定是正常邮件。 generator:当前不需要做什么 discriminator:当前不需要做什么
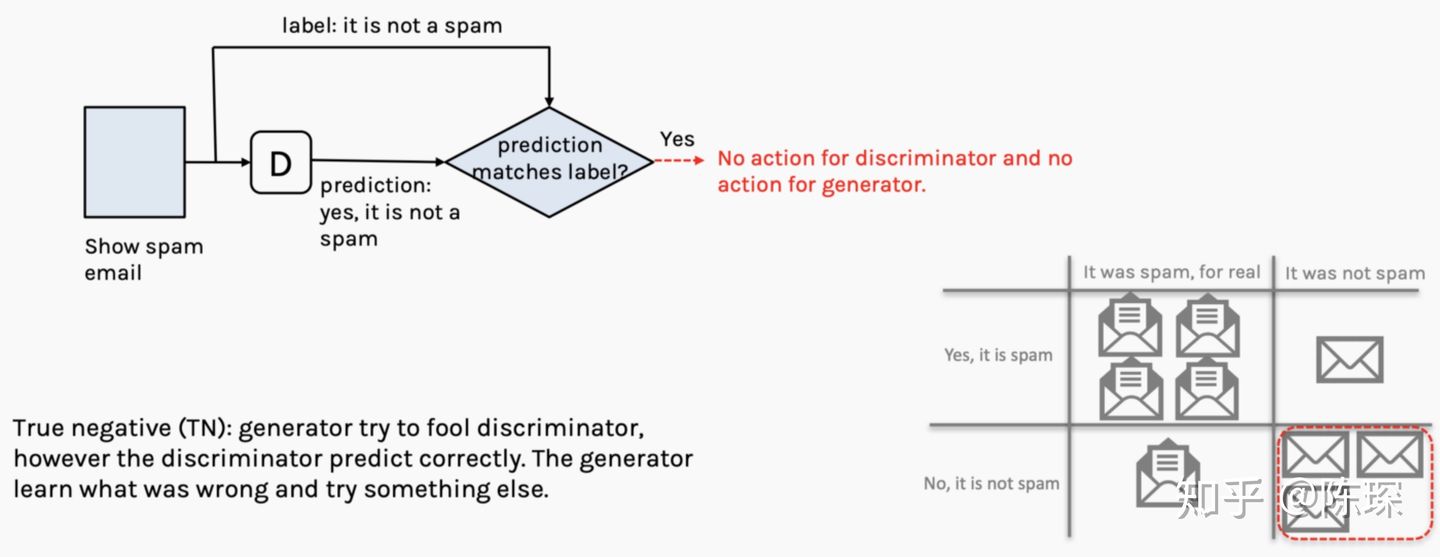
基于上面讨论,图示Network如何训练的:

训练的步骤包括:
- 取batch的训练集x,和随机生成noise z;
- 计算loss;
- 使用back propagation更新generator和discriminator;
我们已经分析好了,在True Positive,False Negative,False Positive情况下需要更新:
True Positive:意味着generator生成的fake数据被抓包,需要对generator进行优化。需要经过参数被固定的discriminator计算loss,更新generator的权重。注意一次只能对两个网络中的一个进行参数调整。
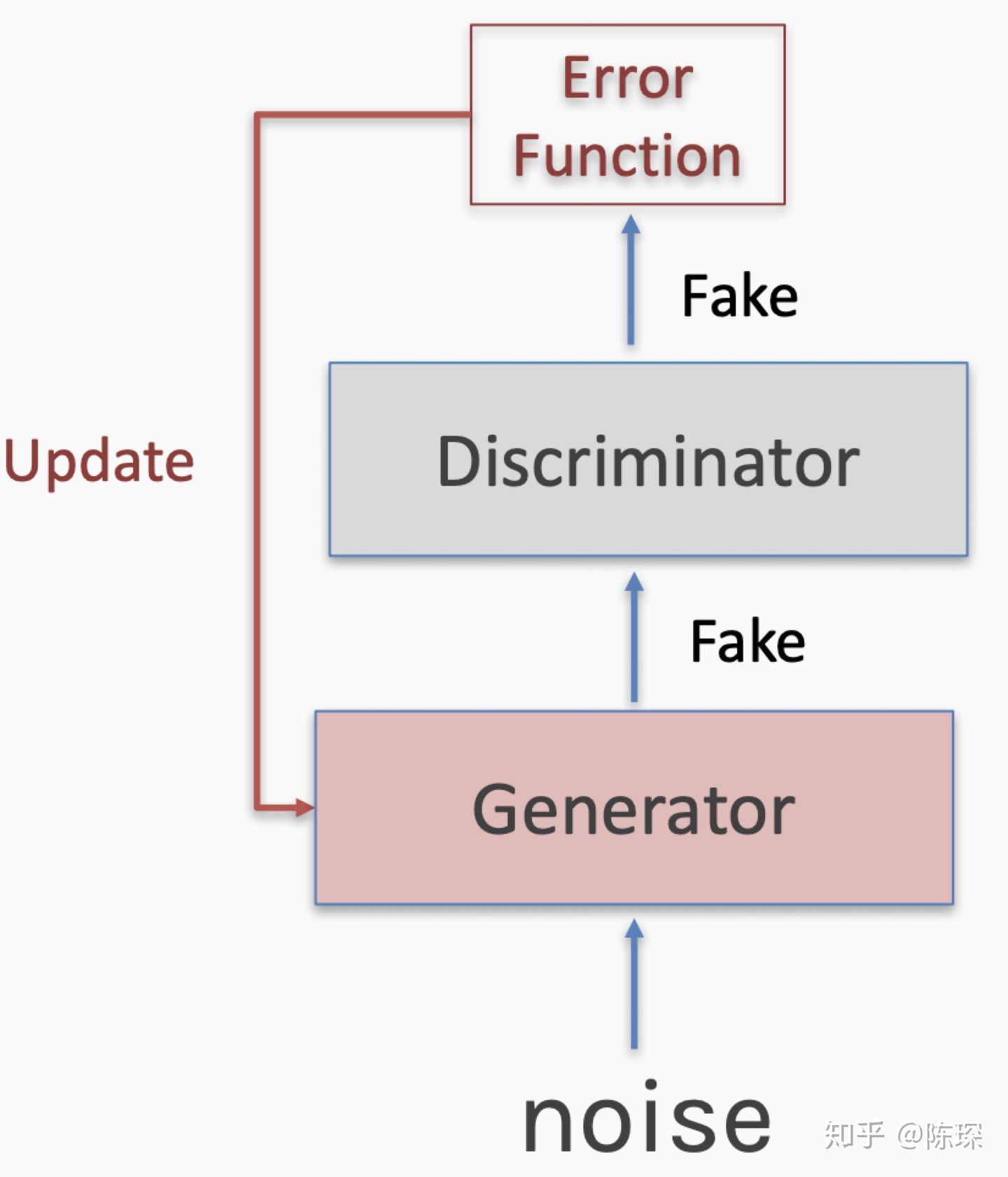
False Negative:意味着真的训练集被discriminator错认为fake数据。只更新discriminator的权重。

False Positive:generator生成的fake数据,被discriminator判定为真的训练集。只对discriminator进行更新。
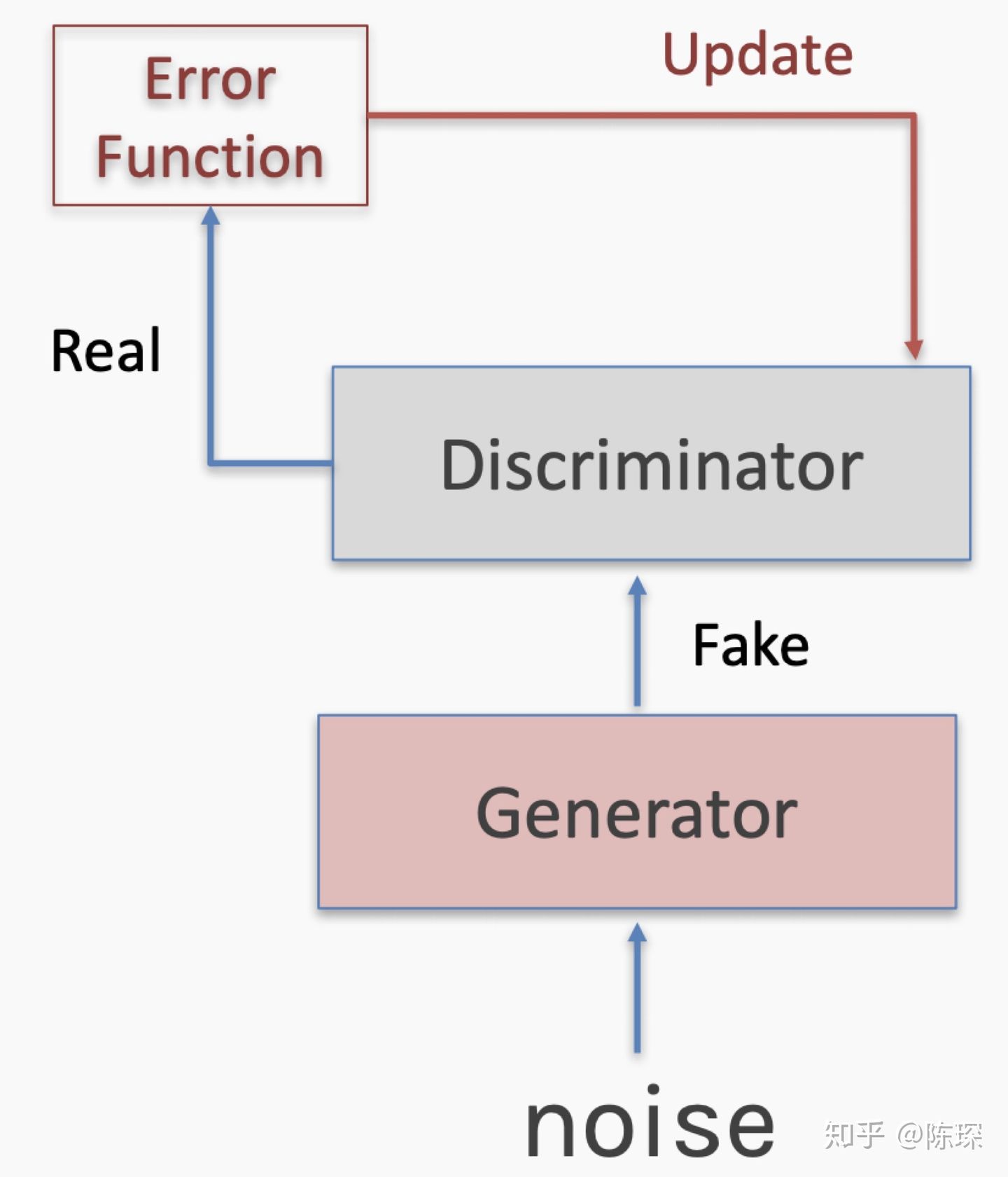
现在让我们用更数学的角度来解释一下:
我们有一个已知的real的分布,generator生成了一个fake的分布。因为这个两个分布不完全相同,所以他们之间存在KL-divergence,也就是损失函数不为0。
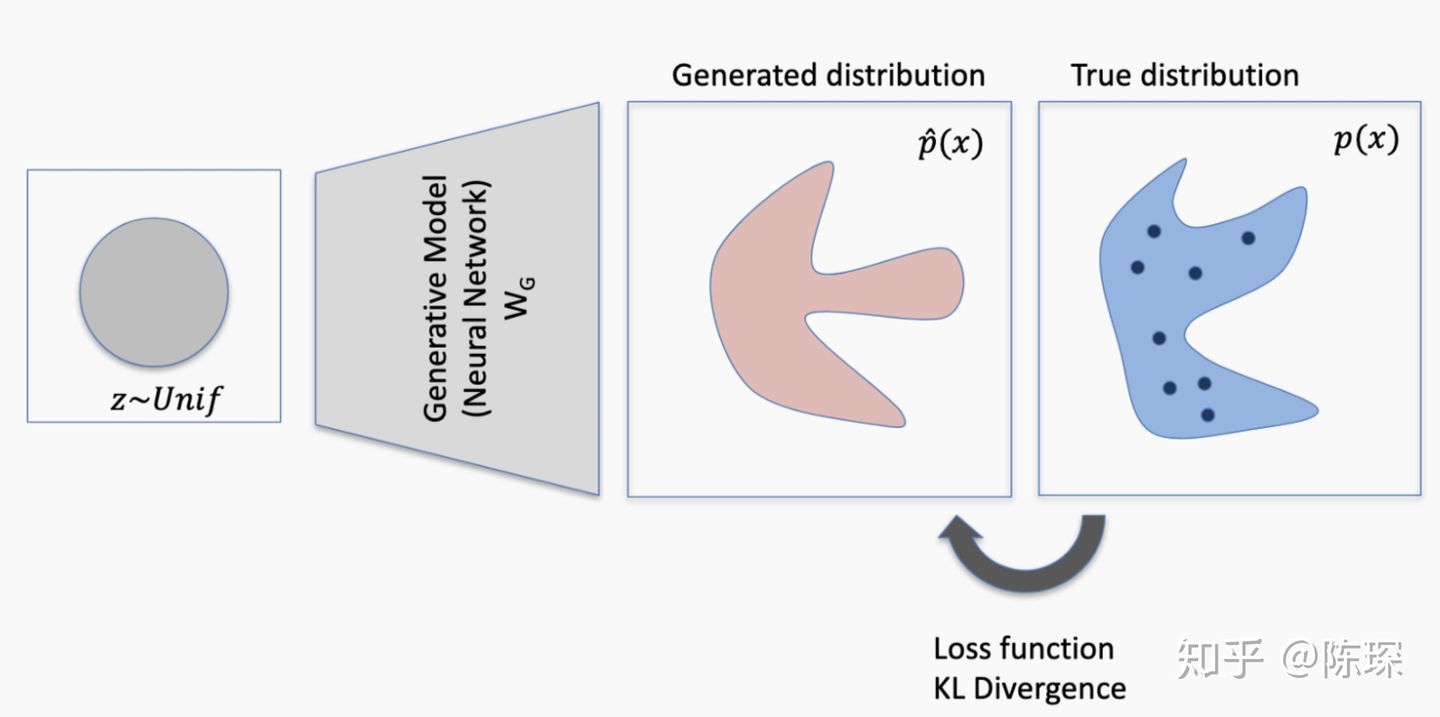
discriminator同时看到real的分布和fake的分布。如果discriminator能分清楚来自generator生成的与来自real分布的,就会生成loss并反向传播更新generator的权重。
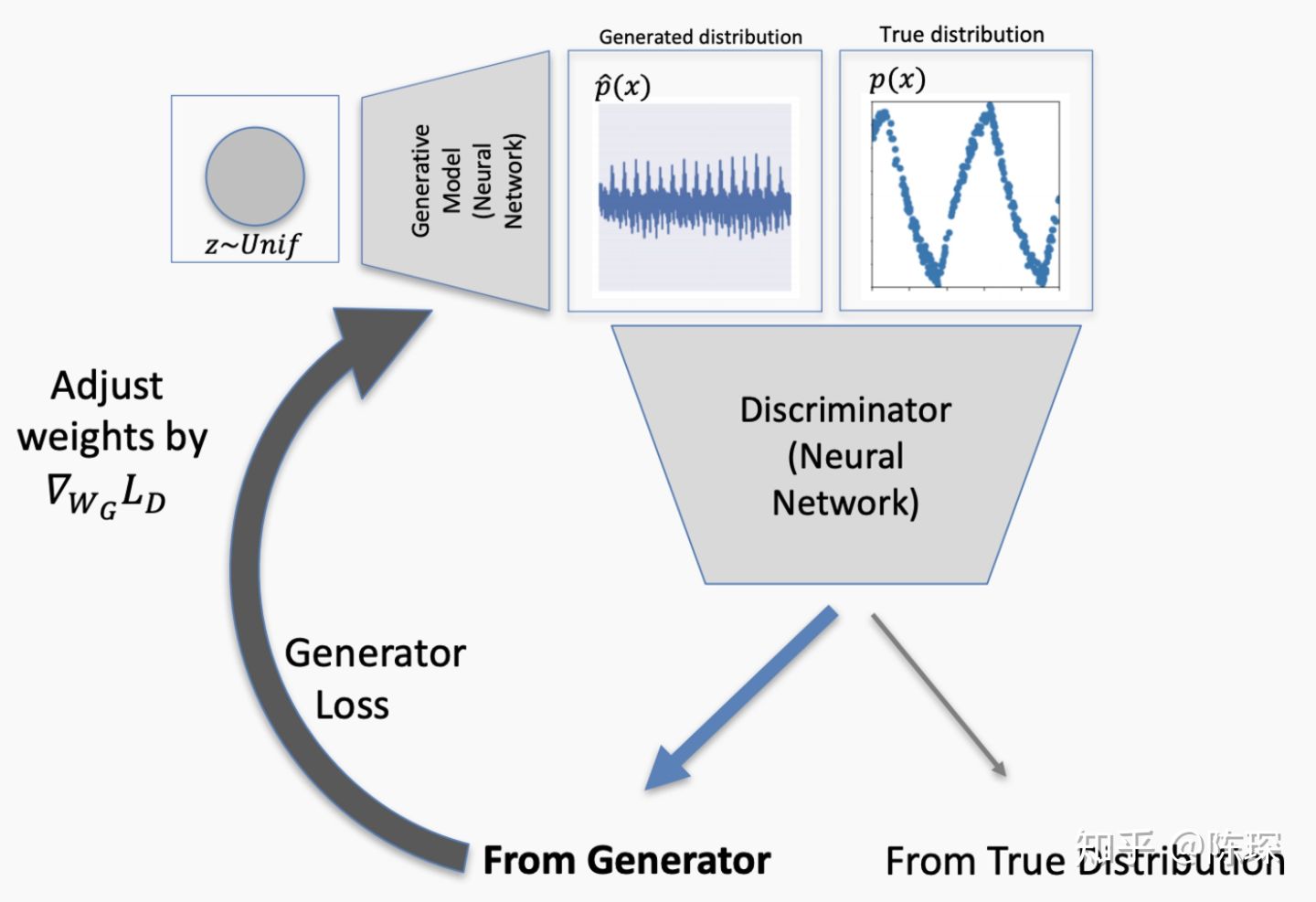
generator更新完成后,生成的fake数据更符合real的分布。
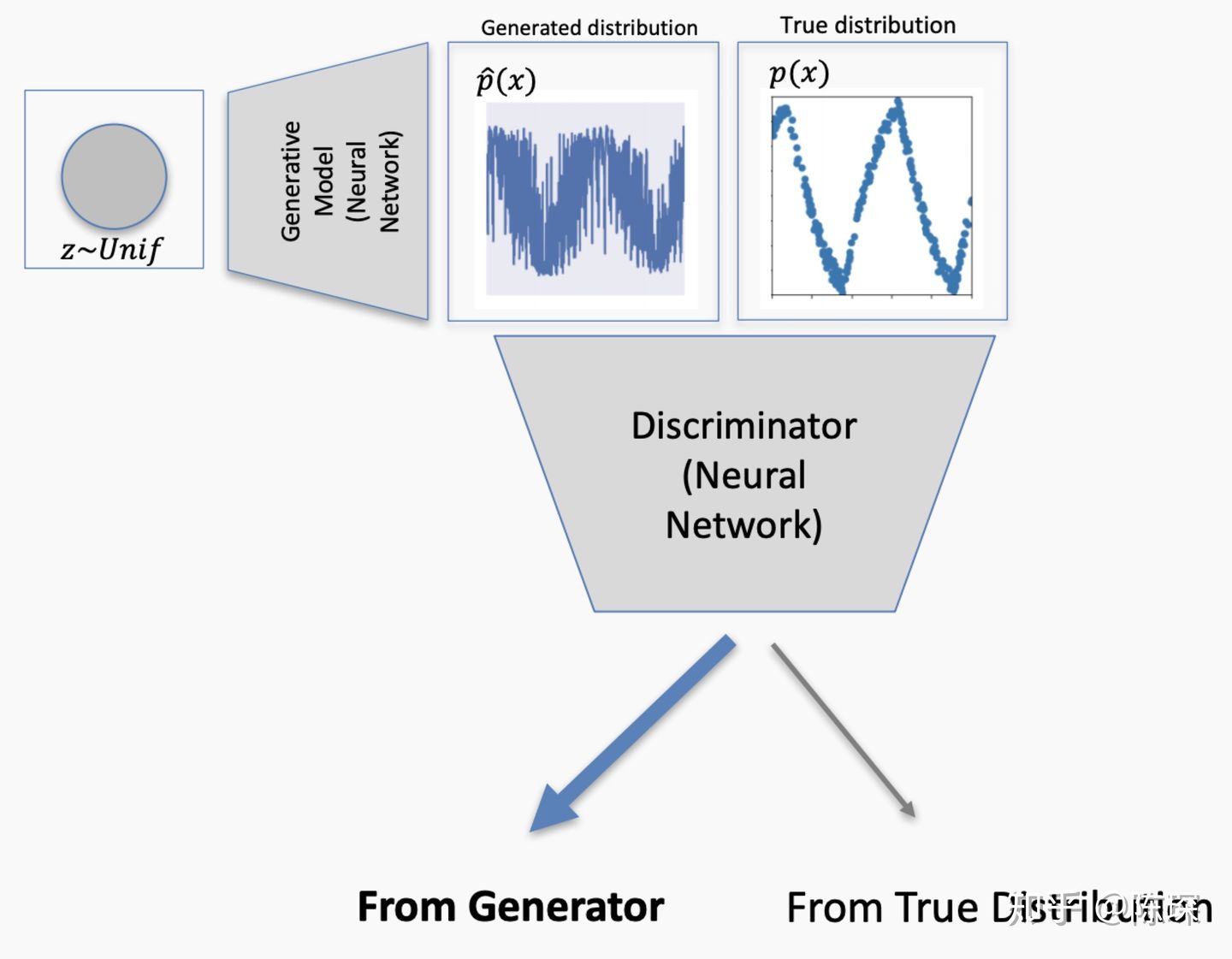
但是如果生成的data仍然不够接近real的分布,discriminator依然能识别出来了,因此再次对generator进行权重更新。
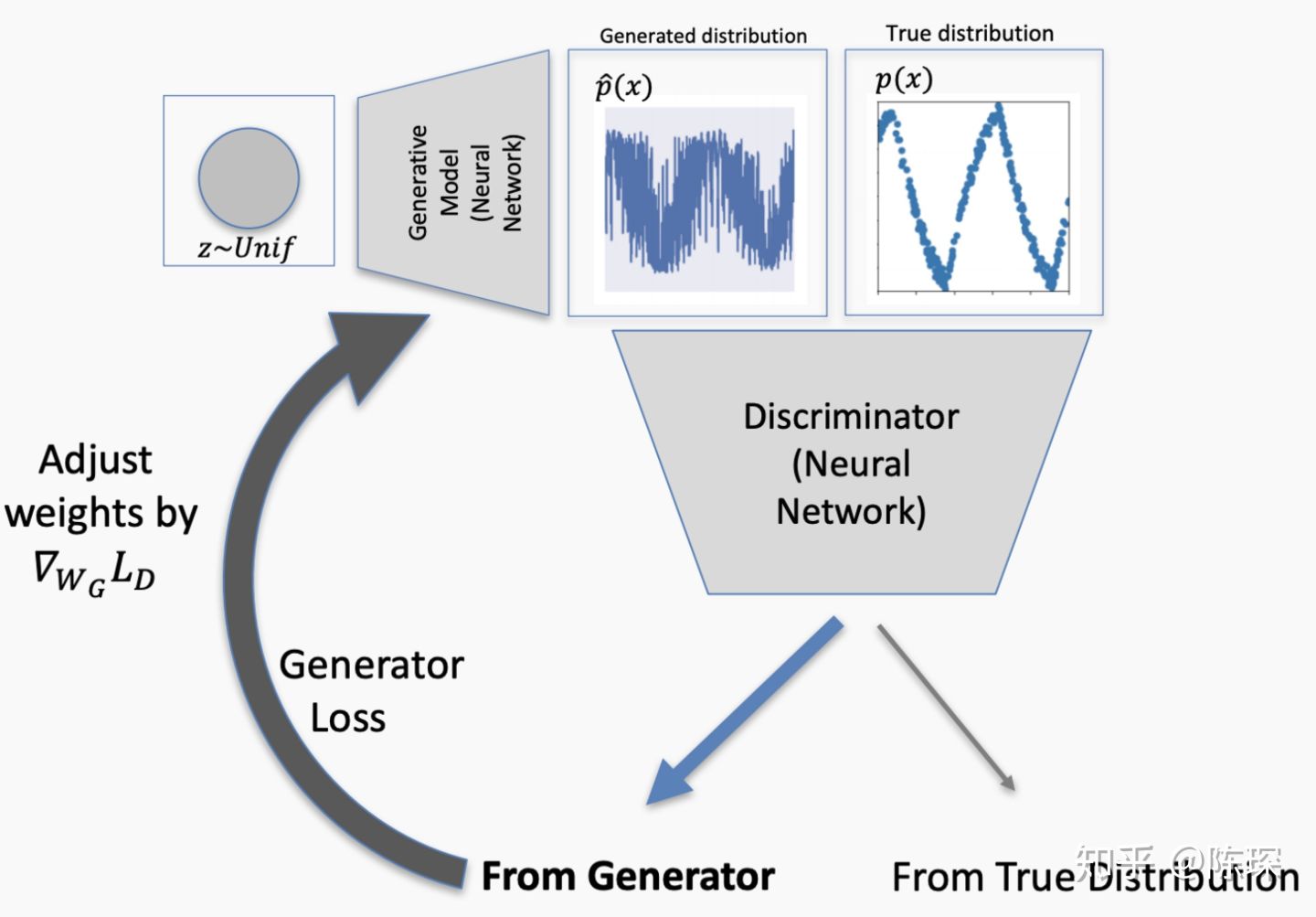
终于这次discriminator被骗过了,它认为generator生成的fake数据就是符合real分布的。这个就对应False Positive的情况,需要对discriminator进行更新。

Loss反向传播来更新discriminator的权重。
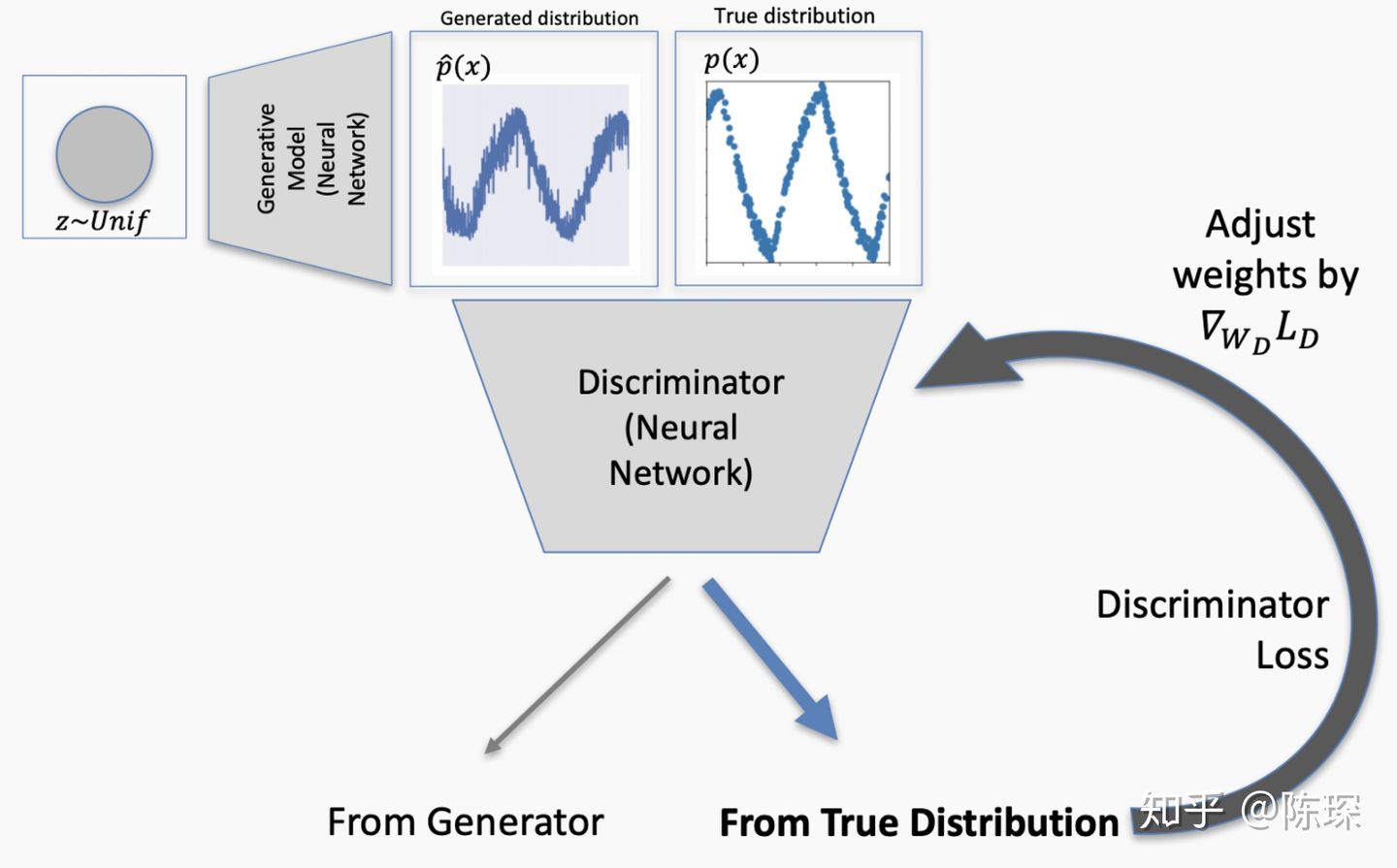
继续这个过程,直到generator生成的分布与real分布无法区分时,网络达到纳什均衡。
三、GAN的实际应用
(Conditional) Synthesis—条件生成最好玩的比如Text2Image、Image2Text。可以基于一段文字生成一张图片,比如这个Multi-Condition GAN(MA-GAN)的text-to-image的例子:
 详见 https://arxiv.org/pdf/1902.06068.pdf
详见 https://arxiv.org/pdf/1902.06068.pdf
Data Augmentation—数据增强 : GAN学习训练集样本的分布,然后进行采样生成新的样本,我们可以使用这些样本来增强训练集。一般我们都是通过对原训练集的图片进行旋转和扭曲来进行增强,这里GAN提供了一种新的方法。
Style Transfer和Manipulation-风格转换 将一张图片的style转移到另外一张图像上,这与neural style transfer非常类似。Neural Style Transfer可以认为是把Style Image的风格加入到Content Image里。因为只有一张Style Image,所以它其实学到的很难完全是Style的特征,因为一个画家的风格很难通过一幅作品就展现出来。GAN能够很好的从多个作品中学习到画家的真正风格特征。
第2/3列为neural style transfer的效果,第5列为cycleGAN:

可以看出对背景特别有效,比如对云的转换等:

GAN在动物和水果上的效果:

。。。。
四、GAN的简单实现
下面是一个最简化的使用Keras实现的GAN,基于CelebA数据集。model的定义:
- 定义discriminator,然后compile;
- 定义generator,不进行compile;
- 定义一个model包含generator和discriminator,把discriminator设为not trainable,然后compile:

训练loop:
- 从训练集选择R张图像;
- 采样大小为N的随机噪声,输入generator产生F张fake的图像;
- 将R张训练集与F张fake图像和对应的label输入discriminator进行训练;
- 采样大小为N的随机噪声;
- 用train_on_batch,以目标label为1对generator进行训练更新。
Imports:
import keras
from keras.layers import *
from keras.datasets import cifar10
import glob, cv2, os
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from IPython.display import clear_output
Global Parameters:
优先在前面声明所有变量,比较清晰
SPATIAL_DIM = 64 # Spatial dimensions of the images.
LATENT_DIM = 100 # Dimensionality of the noise vector.
BATCH_SIZE = 32 # Batchsize to use for training.
DISC_UPDATES = 1 # Number of discriminator updates per training iteration.
GEN_UPDATES = 1 # Nmber of generator updates per training iteration.
FILTER_SIZE = 5 # Filter size to be applied throughout all convolutional layers.
NUM_LOAD = 10000 # Number of images to load from CelebA. Fit also according to the available memory on your machine.
NET_CAPACITY = 16 # General factor to globally change the number of convolutional filters.
PROGRESS_INTERVAL = 80 # Number of iterations after which current samples will be plotted.
ROOT_DIR = 'visualization' # Directory where generated samples should be saved to.
if not os.path.isdir(ROOT_DIR):
os.mkdir(ROOT_DIR)
数据预处理: 对所有训练的image做normalize处理
def plot_image(x):
plt.imshow(x * 0.5 + 0.5)
X = []
# Reference to CelebA dataset here. I recommend downloading from the Harvard 2019 ComputeFest GitHub page (there is also some good coding tutorials here)
faces = glob.glob('../Harvard/ComputeFest 2019/celeba/img_align_celeba/*.jpg')
for i, f in enumerate(faces):
img = cv2.imread(f)
img = cv2.resize(img, (SPATIAL_DIM, SPATIAL_DIM))
img = np.flip(img, axis=2)
img = img.astype(np.float32) / 127.5 - 1.0
X.append(img)
if i >= NUM_LOAD - 1:
break
X = np.array(X)
plot_image(X[4])
X.shape, X.min(), X.max()
定义架构:将block抽象单独定义出来能让代码更简洁。padding方法选择"same":
def add_encoder_block(x, filters, filter_size):
x = Conv2D(filters, filter_size, padding='same')(x)
x = BatchNormalization()(x)
x = Conv2D(filters, filter_size, padding='same', strides=2)(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.3)(x)
return x
使用encoder_block定义discriminator,循环使用encoder block,并不断增大filter size:
def build_discriminator(start_filters, spatial_dim, filter_size):
inp = Input(shape=(spatial_dim, spatial_dim, 3))
# Encoding blocks downsample the image.
x = add_encoder_block(inp, start_filters, filter_size)
x = add_encoder_block(x, start_filters * 2, filter_size)
x = add_encoder_block(x, start_filters * 4, filter_size)
x = add_encoder_block(x, start_filters * 8, filter_size)
x = GlobalAveragePooling2D()(x)
x = Dense(1, activation='sigmoid')(x)
return keras.Model(inputs=inp, outputs=x)下面定义decoder block,主要做反卷积:def add_decoder_block(x, filters, filter_size):
x = Deconvolution2D(filters, filter_size, strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.3)(x)
return x
下面定义generator,循环使用decoder block并不断降低filter size:
def build_generator(start_filters, filter_size, latent_dim): inp = Input(shape=(latent_dim,))
# Projection.
x = Dense(4 * 4 * (start_filters * 8), input_dim=latent_dim)(inp)
x = BatchNormalization()(x)
x = Reshape(target_shape=(4, 4, start_filters * 8))(x)
# Decoding blocks upsample the image.
x = add_decoder_block(x, start_filters * 4, filter_size)
x = add_decoder_block(x, start_filters * 2, filter_size)
x = add_decoder_block(x, start_filters, filter_size)
x = add_decoder_block(x, start_filters, filter_size)
x = Conv2D(3, kernel_size=5, padding='same', activation='tanh')(x)
return keras.Model(inputs=inp, outputs=x)
训练:构建网络和训练流程 构建GAN时,定义discriminator为not trainable是非常重要的。因为我们不能同时训练两个网络,就像我们不能校正多个同时变化的东西。所以在训练某一个网络时,需要保持其他部分是固定不变的。
def construct_models(verbose=False):
# 1. Build discriminator.
discriminator = build_discriminator(NET_CAPACITY, SPATIAL_DIM, FILTER_SIZE)
discriminator.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Adam(lr=0.0002), metrics=['mae'])
# 2. Build generator.
generator = build_generator(NET_CAPACITY, FILTER_SIZE, LATENT_DIM)
# 3. Build full GAN setup by stacking generator and discriminator.
gan = keras.Sequential()
gan.add(generator)
gan.add(discriminator)
::discriminator.trainable = False:: # Fix the discriminator part in the full setup.
gan.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Adam(lr=0.0002), metrics=['mae'])
if verbose: # Print model summaries for debugging purposes.
generator.summary()
discriminator.summary()
gan.summary()
return generator, discriminator, gan
模型训练:
def run_training(start_it=0,num_epochs=1000):
# Save configuration file with global parameters
config_name = 'gan_cap' + str(NET_CAPACITY) + '_batch' + str(BATCH_SIZE) + '_filt' + str(FILTER_SIZE) + '_disc' + str(DISC_UPDATES) + '_gen' + str(GEN_UPDATES)
folder = os.path.join(ROOT_DIR, config_name)
if not os.path.isdir(folder):
os.mkdir(folder)
# Initiate loop variables
avg_loss_discriminator = []
avg_loss_generator = []
total_it = start_it
# Start of training loop
for epoch in range(num_epochs):
loss_discriminator = []
loss_generator = []
for it in range(200):
# Update discriminator.
for i in range(DISC_UPDATES):
# Fetch real examples (you could sample unique entries, too).
imgs_real = X[np.random.randint(0, X.shape[0], size=BATCH_SIZE)]
# Generate fake examples.
noise = np.random.randn(BATCH_SIZE, LATENT_DIM)
imgs_fake = generator.predict(noise)
d_loss_real = ::discriminator.train_on_batch::(imgs_real, np.ones([BATCH_SIZE]))[1]
d_loss_fake = ::discriminator.train_on_batch::(imgs_fake, np.zeros([BATCH_SIZE]))[1]
# Progress visualizations.
if total_it % PROGRESS_INTERVAL == 0:
plt.figure(figsize=(5,2))
# We sample separate images.
num_vis = min(BATCH_SIZE, 8)
imgs_real = X[np.random.randint(0, X.shape[0], size=num_vis)]
noise = np.random.randn(num_vis, LATENT_DIM)
imgs_fake = generator.predict(noise)
for obj_plot in [imgs_fake, imgs_real]:
plt.figure(figsize=(num_vis * 3, 3))
for b in range(num_vis):
disc_score = float(discriminator.predict(np.expand_dims(obj_plot[b], axis=0))[0])
plt.subplot(1, num_vis, b + 1)
plt.title(str(round(disc_score, 3)))
plot_image(obj_plot[b])
if obj_plot is imgs_fake:
plt.savefig(os.path.join(folder, str(total_it).zfill(10) + '.jpg'), format='jpg', bbox_inches='tight')
plt.show()
# update generator.
loss = 0
y = np.ones([BATCH_SIZE, 1])
for j in range(GEN_UPDATES):
noise = np.random.randn(BATCH_SIZE, LATENT_DIM)
loss += ::gan.train_on_batch::(noise, y)[1]
loss_discriminator.append((d_loss_real + d_loss_fake) / 2.)
loss_generator.append(loss / GEN_UPDATES)
total_it += 1
# Progress visualization.
clear_output(True)
print('Epoch', epoch)
avg_loss_discriminator.append(np.mean(loss_discriminator))
avg_loss_generator.append(np.mean(loss_generator))
plt.plot(range(len(avg_loss_discriminator)), avg_loss_discriminator)
plt.plot(range(len(avg_loss_generator)), avg_loss_generator)
plt.legend(['discriminator loss', 'generator loss'])
plt.show()
跑模型:
generator, discriminator, gan = construct_models(verbose=True)
run_training()
训练结果:
NUM_SAMPLES = 7
plt.figure(figsize=(NUM_SAMPLES * 3, 3))
for i in range(NUM_SAMPLES):
noise = np.random.randn(1, LATENT_DIM)
pred_raw = generator.predict(noise)[0]
pred = pred_raw * 0.5 + 0.5
plt.subplot(1, NUM_SAMPLES, i + 1)
plt.imshow(pred)
plt.show()
结果,这里重点毕竟不在效果:

结尾顺带说一下GAN如何进行Evaluation的:
GAN的评估仍然是非常定性的,一个generator看起来怎样才是好呢?
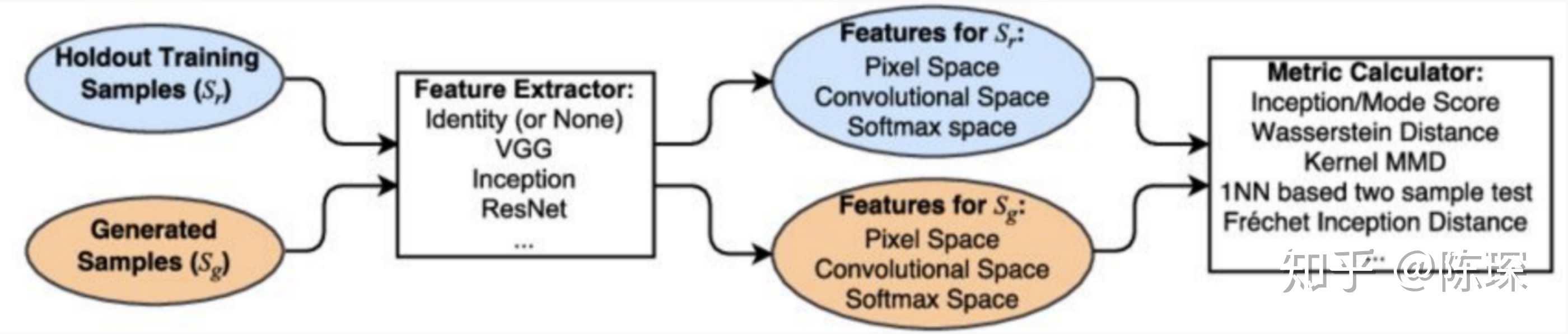
对此目前没有明确的答案,有特定领域的特色。强分类模型通常用于判断生成的样本的质量。两个常见的分数是inception score和TSTR score(Train on Synthetic, Test on Real)。 具体详见有GAN的各种Metrics的tensorflow实现。
参考资料
