【1.2.5】次数分布
一、 次数分布数列及其种类
1.1 次数分布数列的概念
次数分布是统计分组的重要形式。
- 在统计分组的基础上,把总体全部单位按组归类整理, 将其按一定顺序加以排列,形成总体中每一个单位在各组间的分布,称为次数分布。
- 分布在 各组中的总体单位数,叫做次数(frequency),亦称频数;
- 次数与总次数的比值,叫做比率, 亦称频率。
- 把各组的频数或频率按照一定的顺序排列而成的数列,称为次数分布数列,简称 分布数列。
次数分布数列是统计整理的结果,是进行统计描述和统计分析的重要方法。
1.2. 次数分布数列的种类
由于分组标志不同,次数分布数列可分为两种:
- 按照品质标志进行分组形成品质数列。 它用来反映不同属性的各组次数在总体中的分布状况,它由各组名称、各组频数或频率组成;
- 按照数量标志进行分组形成变量数列,它用来反映不同变量值的各组次数在总体中的分布状 况,它由各组变量值和各组次数组成。
二、品质数列的编制
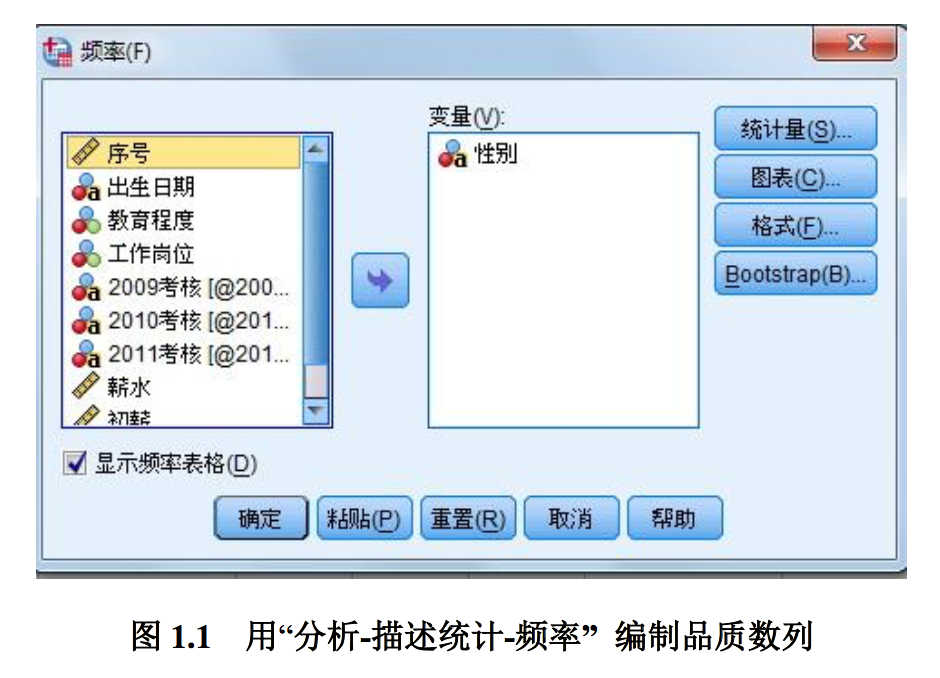
品质数列次数分布就是按品质标志分组所形成的次数分布。它有两个构成要素:一是组 的名称,二是各组的单位数。有时也会计算比率,以反映数据的结构。例如表 1.1 是根据数 据集 03 汇总出的一个品质数列的次数分布。

统计次数使用 COUNTIF 函数,格式为:COUNTIF(range, criteria)。就本题而言,统计 男性职工的函数为“=COUNTIF(B:B,“m”)”。
SPSS 解决方 案:
- 调入 SPSS 数据集 Data1_03
- 选择菜单“分析-描述统计-频率”,把“性别”移入“变量”框,见图 1.1, 按确定
三、 变量数列的编制
由于数列中每组变量值的多少及取值范围不同,变量分布数列可分为单项数列和组距数 列两种。
单项数列就是每一个组只有一个变量值的数列。它是按变量值大小顺序排列的。单项数 列是在变量值不多以及变量值变动幅度不大时运用,一般是有多少个不同的变量值就分为多 少个组。
组距数列是把变量的取值范围划分成若干区间,以一段变动区间为一个组的数列。即组 距数列中的每一个组是由一个变量值的区间表示。组距数列是在变量值个数较多、变量值变 动幅度较大时运用,它又分为等距数例和异距数列。
变量数列的编制,主要是组距数列的编制。在编制过程中,一定要处理好如下几个问题:
3.1. 组数与组距
组距数列是用变量值变动的一定范围代表一个组,每个组的最大值为组的上限,最小值 为组的下限。每个组的上限与下限间的距离称为组距。编制时,先要找全距(R),即全部变 量的最大值与最小值的距离;然后确定组数(m),实际工作中,主要凭经验确定,也可按不 同的组数进行试验,比较其次数分布表,看哪一个能够更好地显示出分组数据的特征,另外 有一个经验公式—“斯透奇斯规则”(Sturges' rule),m = 1 + 3.322 lgN,(N 为总次数)是帮 助确定组数的;组数与组距(i)的关系是:i=R/m,两者成反比变化。
根据各组距是否相等分等距数列和异距数列,编制何种应根据统计研究的目的来确定。 采用等距分组目的是为了直接比较各组次数分布或分析对比各组的指标;采用异距分组目的 是为了从数量上区分性质不同的总体。组距数列中还可以区分闭口数列与开口数列:闭口数 列是指首末两组的上、下限齐全的数列;开口数列是指首组组距缺下限或末组组距缺上限的 数列。
3.2. 组限和组中值
组限的表示方法,应根据所研究现象的性质而定,并要注意如下几点:
- 第一组(最小组)的下限不能大于最小变量值;最末一组(最大组)的上限不得小于最大变量值;这就 能够使同质的总体单位在同一组内,而使标志值在各组的变动,能够反映事物质的变化。
- 组限应是引起事物质变的数量界限,并有利于表现总体分布的规律性。
- 分组变量 可分为离散变量与连续变量,它们的组限表示方法也是不同的。在划分离散变量的组限时, 相邻组的组限可以间断,而在划分连续变量的组限时,相邻组的组限必须重叠,并在统计次 数时,一般应遵循“上组限不在内”的原则。这是因为,在对连续变量分组时,每一组的上限 同时又是下一组的下限,即相邻两组的上限与下限是用同一数值表示的。为了避免计算的混 乱,一般是把达到上限数值的单位数计入下一组内。
组数、组距、组限确定后,把全部的变量值归类列各组,并按顺序排列,就是所要编制 的变量数列了。
在统计分析中,通常会以组中值来代表各组标志值的平均水平,当各组标志值均匀分布 时,组中值所代表的各组标志值的水平,其代表性就高。组中值,就是组的上下限之间的中 点数值,计算公式:
- 闭口组的组中值=(上限+下限)/2
- 缺下限的开口组组中值=上限—邻组组距/2;
- 缺上限的开口组组中值=下限+邻组组距/2
【例 2.2】江浦县苗圃对 110 株树苗的高度进行测量(单位:厘米),数据如下,编制次 数分布表。(SPSS 数据文件编号:data2_02)

【解】
第一步,先将 110 个数据排序,找出最大值 154 和最小值 80, 这个数列的全距 R=154- 80=74 厘米。
第二步,根据斯透奇斯规则确定组数:m = 1 + 3.322×(lg110) = 7.78,再根据组数与组距 的关系确定组距:i= R/m = 74/7.78 =9.51(厘米)。根据以上的计算结果,组数定为 8 组; 组距定为 10 厘米。
在用经验公式计算 m 和 i 时,计算结果的取舍,不采用四舍五入法,而采用 舍去进一法,即:只要有小数,就把小数舍去,并在整数位上加 1。这种做法保证次数分布 表有足够宽的复盖区间。另外,一般说来组距宜于取整百整十,起始组的下限也宜于取整百 整十,这样看起来比较舒服。还有,有些数据本身是有特殊或固定的分组要求的,如学生成 绩如果出现“54-62”这样一组,则将不同性质的学生混在了一起,即在这组里有成绩不合格 的学生,又有成绩合格的学生,这样的分组肯定是错误的。
第三步,根据所定组数和组距确定组限。第一组下组限定为 80,第一组上组限则为 90 (即 80+10);第二组下组限就是第一组上组限,第二组上组限为 100;……;依此类推,第 八组下组限是 150,其上组限则为 160。这样共有 8 个下组限和 8 个上组限。由于有重合值, 故只有 9 个组限值。
第四步,进行归组,即将各个变量值归入相应的组中,比如 154 归入第八组(150-160); 133 归入第六组(130-140);……;依此类推。最后的结果用次数分布表显示,见表 1.2。
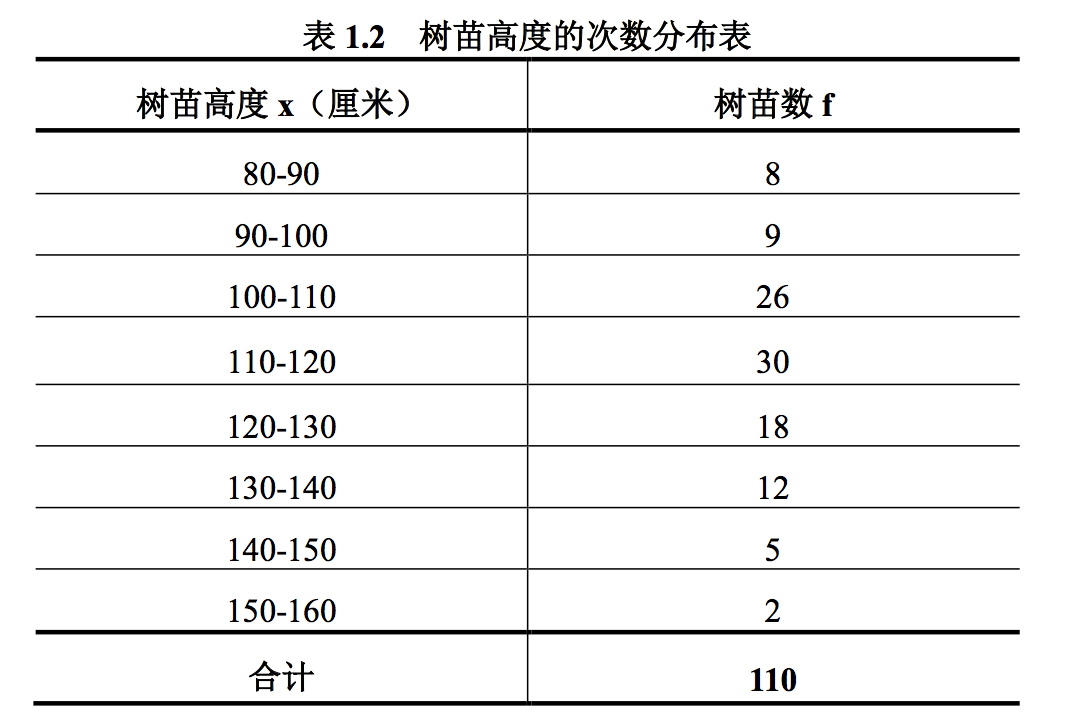
如果数据量很大,归组的工作会很烦人,Excel 中有“FREQENCY”函数,可以完成这一 任务。
FREQENCY 函数的格式为:=FREQUENCY(ARRAY, BINS) 其中 ARRAY 是指原始资 料的存放区域,BINS 是指统计分组的组上限构成的数值序列。图 1.2 是用 Excel 操作过程 与结果的部分截图。
Excel 解决方 案
- 输入原始资料,本例的资料存放在 A2:A111
- 计算基础数据,如 B、C 列,B 列是文字提示,C 列存放的是相应 公式和函数
- 输入分组标志,如本例的 D 列;列出各组的上限,如本例的 H3:H10
- 用鼠标选定函数返回值存放的区域,如本例应选 I3:I10
- 输入函数“=FREQUENCY(A2:A111,H3:H10)”
- 同时按下组合键“Ctrl+Shift+Enter”,计算机会将统计出的次数放在I3:I10 中
特别注意:FREQUENCY 函数在统计次数时,将与对应上限值一样大的数也统计在内。 以第一个上限为例,若 H3 中上限定为 90,当原始资料中恰有 90 时,则该“90”被计入这一 组,这样就和我们常说的“上限不包括原则”相违背,因而我们在 H 列所列的上限必须是一 个略小于 90 的数,如 89.5。
四、次数分布表
表 1.2 是一个最简单的次数分布表,我们还可以对简单表中的数据进行计算汇总,得到 一个内容更加丰富的次数分布表,见表 1.3。

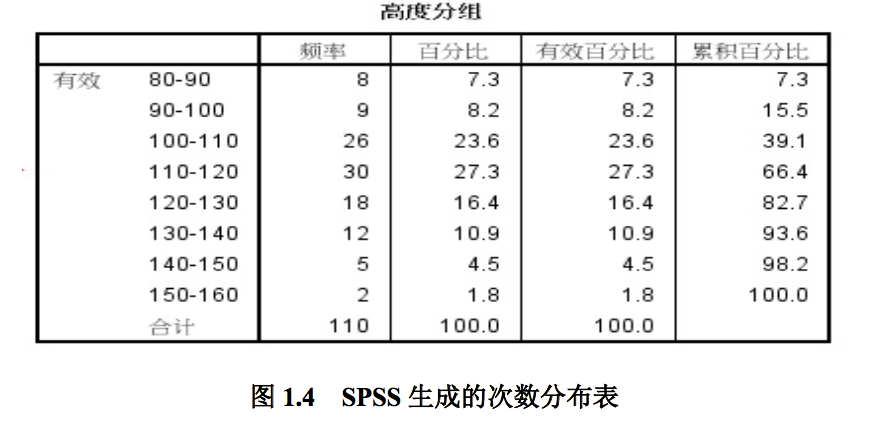
我们可以将各组的频数除以总次数,得到频率,用以代表各组占总次数的比率。如 30/110=27.3%,则表示树苗高度在 120-130 厘米之间的树苗占所有树苗的 27.3%。
向上累积有时又称“较小制累计”,它表示的是低于某分组上限的频数与频率,如树苗高 度在 120 厘米以下的树苗有 73 棵,占总数的 66.4%;向下累积有时又称“较大制累计”,它 表示的是高于某分组下限的频数与频率,如树苗高度在 110 以上的树苗有 67 棵,占总数的 60.9%。
SPSS 解决方案
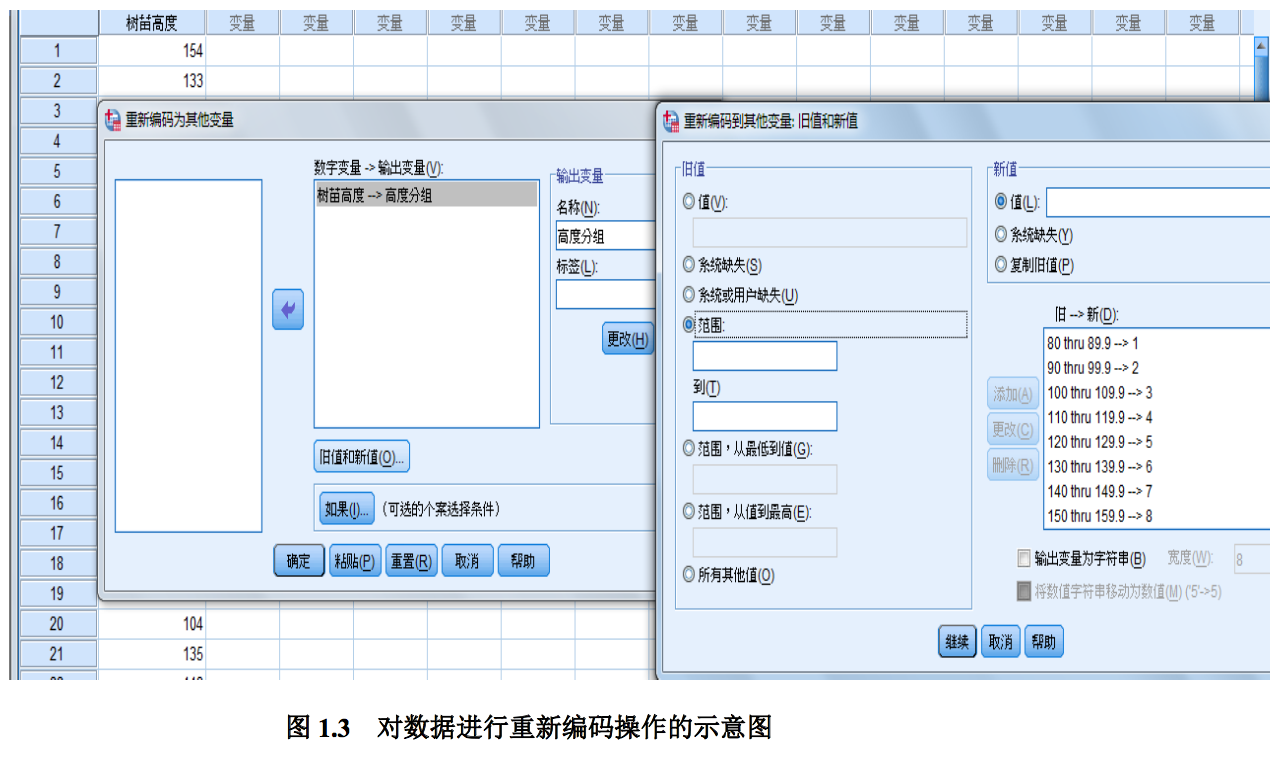
- 调入 SPSS 数据集 Data2_02,对原始数据“树苗高度”进行重新编 码,操作是:菜单“转换-重新编码为不同变量”,见图 1.3,执行后 生成新变量“高度分组”
- 对变量“高度分组”定义值,如 1 表示 80-90,……
- 菜单“分析-描述统计-频率”,把“高度分组”移入“变量”框,执行后 生成次数分布表,见图 1.4
教师:数据收集与整理是基础工作,怎样强调它的重要性都不过分。这好比做菜,没有好的食 材,高明厨师也难以成就美味佳肴。数据收集与整理也是艰巨工作,研究项目 70-80%的工作 量在于此。数据收集与整理还是一门艺术,如何从冷漠的被访者那里获得真实的数据,这可得 有真功夫。 可以参看有关市场调查的书籍,它会为你提供问卷设计等具体问题的详尽攻 略。 收集整理后的数据需要展现,手段就是表与图。不能小视,它可是你的“脸面”哦。
参考资料
- 《统计学》 南京财经大学 陈耀辉、王芳、王庚、韩中、张艳芳、黄莉芳
