Linux【9】-进程管理7-2--集群管理--slurm
不开心呀,sge都没搞通,现在就要开始撸slurm了。没办法,谁叫我们要遇到问题,解决问题呢
一、概述
Slurm 是一个开源、容错、高可伸缩的集群管理和大型小型 Linux 集群作业调度系统。slurm不需要对操作系统内核进行修改,而是相对独立的。 作为集群工作负载管理器。slurm有三个关键功能:
- 首先,它在一段时间内为用户分配独占或者非独占的计算资源,以便他们能够执行工作任务
- 其次,它能提供一个框架,用于在分配的节点集上启动,执行,监视工作,通常是并行作业任务
- 最后,它通过管理挂起的工作队列,来仲裁资源争夺问题
构架
如下图所示,slurm构成有:
- 运行在每个计算节点上的slurmd守护进程
- 运行在管理节点上的中央slurmctld守护进程(可选的故障切换节点模式)
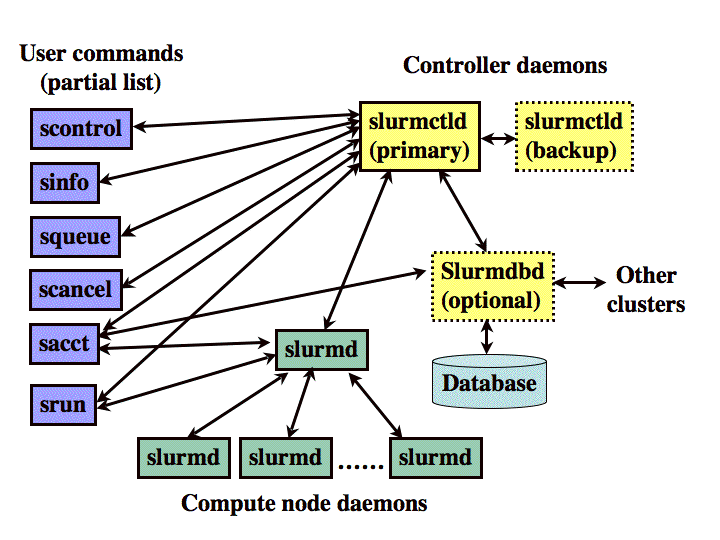
用户命令,包括:sacct,salloc,sattach,sbatch,sbcast,scancel,scontrol,sinfo,smap,squeue,srun,strigger,sviw,sreport等,均可以在集群的任何地方运行。
如下图所示,由这些 Slurm 守护程序管理的实体,包括:
- 计算资源node
- 计算资源组成的逻辑集partition
- 分配给用户指定的时间量的资源分配job
- 作业中的一组任务(有可能是并行任务)
这些分区可以被视为作业队列, 其中每一个都有各种约束, 如作业大小限制、工作时间限制、允许使用它的用户等。 按照优先级排序的作业,从队列中分配节点,直至该队列分资源,如节点,处理器,内存等耗尽。 一旦一个job分配了一组节点后, 用户就能够按照任何分配配置,以作业步骤形式启动并行工作。 例如, 可以启动一个作业步骤, 利用分配给作业的所有节点, 或者多个作业步骤可以独立地使用分配的一部分。
二、使用
2.1 查看节点与分区
2.1.1 管理分区与节点的状态 – sinfo
sinfo报告由 Slurm 管理的分区和节点的状态。它具有多种筛选、排序和格式设置选项。
[sam@hr-node34 test]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
compute* up infinite 1 down* hr-node37
compute* up infinite 2 idle hr-node[34,36]
更高级的用法:
sinfo -N -o "%8P %3N %.6D %.11T %12C %.8z %.6m %.8d %.6w %.8f %20E"

或者是
alias s='sinfo -N -o "%.8P %.8N %.5T %.13C %.8z %.6m %.8d %.6w %.8f %20E" && squeue -o " %.8i %.9P %.15j %.8u %.2t %.10M %.4C %.6D %R"'
State of the nodes. Possible states include: allocated, completing, down, drained, draining, fail, failing, future, idle, maint, mixed, perfctrs, power_down, power_up, reserved, and unknown plus Their abbreviated forms: alloc, comp, down, drain, drng, fail, failg, futr, idle, maint, mix, npc, pow_dn, pow_up, resv, and unk respectively. Note that the suffix “*” identifies nodes that are presently not responding.
- MIXED : The node has some of its CPUs ALLOCATED while others are IDLE.
- DRAINED : The node is unavailable for use per system administrator request. See the update node command in the scontrol(1) man page or the slurm.conf(5) man page for more information.
- DRAINING: The node is currently executing a job, but will not be allocated to additional jobs. The node state will be changed to state DRAINED when the last job on it completes. Nodes enter this state per system administrator request. See the update node command in the scontrol(1) man page or the slurm.conf(5) man page for more information.
2.1.2 查看配置
scontrol show config
2.1.3 查看分区
[sam@hr-node34 test]$ scontrol show partition
PartitionName=compute
AllowGroups=ALL AllowAccounts=ALL AllowQos=ALL
AllocNodes=ALL Default=YES QoS=N/A
DefaultTime=NONE DisableRootJobs=NO ExclusiveUser=NO GraceTime=0 Hidden=NO
MaxNodes=UNLIMITED MaxTime=UNLIMITED MinNodes=1 LLN=NO MaxCPUsPerNode=UNLIMITED
Nodes=hr-node34,hr-node[36-37]
PriorityJobFactor=1 PriorityTier=1 RootOnly=NO ReqResv=NO OverSubscribe=YES:4 PreemptMode=OFF
State=UP TotalCPUs=98 TotalNodes=3 SelectTypeParameters=NONE
DefMemPerNode=UNLIMITED MaxMemPerNode=UNLIMITED
2.1.4 查看节点
通过 /etc/slurm/slurm.conf 查看主节点
ControlMachine=***
scontrol show node
NodeName=hr-node34 Arch=x86_64 CoresPerSocket=1
CPUAlloc=0 CPUErr=0 CPUTot=42 CPULoad=1.07
AvailableFeatures=(null)
ActiveFeatures=(null)
Gres=(null)
NodeAddr=hr-node34 NodeHostName=hr-node34 Version=16.05
OS=Linux RealMemory=128613 AllocMem=0 FreeMem=3898 Sockets=42 Boards=1
State=IDLE ThreadsPerCore=1 TmpDisk=2686479 Weight=1 Owner=N/A MCS_label=N/A
BootTime=2018-07-18T22:58:44 SlurmdStartTime=2018-07-19T00:38:04
CapWatts=n/a
CurrentWatts=0 LowestJoules=0 ConsumedJoules=0
ExtSensorsJoules=n/s ExtSensorsWatts=0 ExtSensorsTemp=n/s
2.1.5 查看作业
scontrol show jobs
scontrol show job jobid
2.1.6 管理的作业、分区和节点的状态信息–smap
smap报告由 Slurm 管理的作业、分区和节点的状态信息, 但以图形方式显示信息以反映网络拓扑。
2.2 作业管理
2.2.1 单个提交作业
# srun hostname
mycentos6x
# srun -N 3 -l hostname
: mycentos6x
: mycentos6x1
: mycentos6x2
# srun sleep 60 &
2.2.2 提交脚本
vim run.slurm
#!/bin/bash
#SBATCH -J test
#SBATCH -p compute
#SBATCH --cpus-per-task=4
#SBATCH --output=/mnt/nfs/sam/test
#SBATCH --error=/mnt/nfs/sam/test
time
echo 'wwww'
记得run.slurm需要可执行的权限
chmod 775 run.slurm
运行结果:
[sam@hr-node34 test]$ sbatch run.slurm
wwww
real 0m0.000s
user 0m0.000s
sys 0m0.000s
注:
- 指定运行节点: –nodelist=g03
- 更多参数说明:https://slurm.schedmd.com/sbatch.html ; https://ubccr.freshdesk.com/support/solutions/articles/5000688140-submitting-a-slurm-job-script
- 刚开始通过srun run.slurm,run.slurm定义的参数怎么都运行不起来
例二(run.slurm):
#!/bin/sh
#SBATCH --partition=gpu
#SBATCH --nodes=1-1
#SBATCH --nodelist=g02
#SBATCH --cpus-per-task=30
#SBATCH --job-name="4c4k"
#SBATCH --output=slurm.out
#SBATCH --time=30000000:00:00
##SBATCH --mail-user=qxxn@sina.com
##SBATCH --mail-type=ALL
#ulimit -s unlimited
echo "SLURM_JOBID="$SLURM_JOBID
echo "SLURM_JOB_NODELIST"=$SLURM_JOB_NODELIST
echo "SLURM_NNODES"=$SLURM_NNODES
echo "SLURMTMPDIR="$SLURMTMPDIR
echo "working directory = "$SLURM_SUBMIT_DIR
ulimit -s unlimited
time /data/xxx.py 4C4K.fa 30
然后,通过 sbatch run.slurm运行即可
注:
-N, --nodes=<minnodes[-maxnodes]>
请求将最少的minnodes节点分配给此作业。也可以使用maxnodes指定最大节点数。如果仅指定了一个数字,则将其用作最小和最大节点数。分区的节点限制取代了作业的节点限制。如果作业的节点限制超出其关联分区所允许的范围,则作业将处于PENDING状态。这允许在分区限制改变时稍后可能执行。如果作业节点限制超过分区中配置的节点数,则作业将被拒绝。请注意,环境变量SLURM_JOB_NODES将设置为实际分配给作业的节点数。有关更多信息,请参阅ENVIRONMENT VARIABLES部分。如果未指定-N,则默认行为是分配足够的节点以满足-n和-c选项的要求。作业将在指定的范围内分配尽可能多的节点,而不会延迟作业的启动。节点计数规范可以包括数值后跟后缀“k”(将数值乘以1,024)或“m”(将数值乘以1,048,576)。
2.2.3 追踪任务
SLURM 提供了丰富的追踪任务的命令,例如 scontrol,sacct 等。这些 命令有助于查看正在运行或已完成的任务状态。当用户认为任务异常时,可使用这些 工具来追踪任务的信息。
对于正在运行或排队的任务,可以使用
$ scontrol show job JOBID
其中 JOBID 是正在运行的作业 ID,如果忘记 ID 可以使用,可以查看用户下的运行任务
squeue -u USERNAME
查看目前处于运行中的作业。
[liuhy@admin playground]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
140 cpu test liuhy R 0:01 1 comput1
[liuhy@admin playground]$ scontrol show job 140
JobId=140 JobName=test
UserId=liuhy(502) GroupId=users(100) MCS_label=N/A
Priority=283 Nice=0 Account=root QOS=normal
... (more information) ...
则会输出从 MM 月 DD 日起的所有历史作业。
$ sacct -S MMDD
默认情况会输出作业 ID,作业名,分区,账户,分配的 CPU,任务结束状态,返回码。 当然我们还可以使用 –format 参数来指定到底要输出那些指标。
[liuhy@admin playground]$ sacct --format=jobid,user,alloccpu,allocgres,state%15,exitcode
JobID User AllocCPUS AllocGRES State ExitCode
------------ --------- ---------- ------------ --------------- --------
104 liuhy 1 gpu:1 COMPLETED 0:0
104.extern 1 gpu:1 COMPLETED 0:0
105 liuhy 1 COMPLETED 0:0
105.extern 1 COMPLETED 0:0
108 liuhy 48 COMPLETED 0:0
108.extern 48 COMPLETED 0:0
126 liuhy 4 COMPLETED 0:0
126.extern 4 COMPLETED 0:0
140 liuhy 12 COMPLETED 0:0
140.batch 12 COMPLETED 0:0
140.extern 12 COMPLETED 0:0
141 liuhy 12 CANCELLED by 0 0:0
141.batch 12 CANCELLED 0:15
141.extern 12 COMPLETED 0:0
142 liuhy 1 FAILED 2:0
142.extern 1 COMPLETED 0:0
142.0 1 FAILED 2:0
在这里我们详细显示了作业 ID,用户,申请的 CPU,申请的 GPU,任务结束状态, 返回码,其中我们比较感兴趣的是任务结束状态。在这里我们看到,JOBID 为 141 的 作业的状态是 CANCELLED by 0,这里 0 表示系统的 root 用户。这条信息表示:我们 的任务被集群的超级管理员强制取消了!这就需要询问管理员具体的原因了。另外, JOBID 为 142 作业的状态是 FAILED,它的含义是我们的作业脚本中有命令异常退出, 这时候就需要检查我们的 SLURM 脚本的命令部分或者是查看运行环境了。
2.2.4 更新任务
有时我们很早就提交了任务,但是在任务开始前却发现作业的属性写错了(例如提交错 了分区,忘记申请 GPU 个数),取消了重新排队似乎很不划算。如果作业恰好没在运行 我们是可以通过 scontrol 命令来修改作业的属性。
使用以下命令可以修改 JOBID 任务的部分属性
scontrol update jobid=JOBID ...
由于可修改的属性非常多,我们可以借助 SLURM 自动补全功能来查看可修改的内容。 这只需要我们在输入完 JOBID 后空一格并敲两下
[liuhy@admin ~]$ scontrol update jobid=938 <TAB><TAB>
account=<account> mintmpdisknode=<megabytes> reqnodelist=<nodes>
conn-type=<type> name> reqsockets=<count>
contiguous=<yes|no> name=<name> reqthreads=<count>
dependency=<dependency_list> nice[=delta] requeue=<0|1>
eligibletime=yyyy-mm-dd nodelist=<nodes> reservationname=<name>
excnodelist=<nodes> numcpus=<min_count[-max_count] rotate=<yes|no>
features=<features> numnodes=<min_count[-max_count]> shared=<yes|no>
geometry=<geo> numtasks=<count> starttime=yyyy-mm-dd
gres=<list> or switches=<count>[@<max-time-to-wait>]
licenses=<name> partition=<name> timelimit=[d-]h:m:s
mincpusnode=<count> priority=<number> userid=<UID
minmemorycpu=<megabytes> qos=<name> wckey=<key>
minmemorynode=<megabytes> reqcores=<count>
例如我要更改当前的分区到 gpu,并且申请 1 块卡,可以输入
scontrol update jobid=938 partition=gpu gres=gpu:1
注意变更的时候仍然不能超过系统规定的上限。变更成功后,作业的优先级可能需要重新 来计算。
当任务已经开始运行时,一般不可以再变更申请资源,分区等参数。特别地,如果发现 自己低估了任务运行时间,用户不能使用 scontrol 命令延长任务最大时间。但是可以 根据需求减少任务的最大时间。若确实有延长任务时间的急切需求请联系管理员。
2.2.5 使用作业数组(Job Array)
很多时候我们需要运行一组作业,这些作业所需的资源和内容非常相似,只是一些参数 不相同。这个时候借助 Job Array 就可以很方便地批量提交这些作业。Job Array 中的 每一个作业在调度时视为独立的作业,仍然受到队列以及服务器的资源限制。
在 SLURM 脚本中使用 #SBATCH -a range 即可指定 Job Array 的数字范围,其中的 range 参数需要是连续或不连续的整数。下面几种指定方式都是合法的。
- SBATCH -a 0-9 作业编号范围是 0 到 9,均含边界。
- SBATCH -a 0,2,4 作业编号是 0,2,4。
- SBATCH -a 0-5:2 同上,作业编号为 0,2,4,这个写法的意义相当于 MATLAB 中 的 0:2:5,即间隔变成 2。
- SBATCH -a 0-9,20,40 混合指定也是可以的。
在脚本运行中,SLURM 使用环境变量来表示作业数组,具体为
- SLURM_ARRAY_JOB_ID 作业数组中第一个作业的 ID。
- SLURM_ARRAY_TASK_ID 该作业在数组中的索引。
- SLURM_ARRAY_TASK_COUNT 作业数组中作业总数。
- SLURM_ARRAY_TASK_MAX 作业数组中最后一个作业的索引。
- SLURM_ARRAY_TASK_MIN 作业数组中第一个作业的做引。
可用以上变量来区分不同组内的任务,以便于处理不同的输入参数。
对于每个数组内的作业,它的默认输出文件的命名方式为 slurm-JOBID_TASKID.out。
下面是一个很小的 SLURM 脚本例子,它使用 Job Array 来返回一些预设数组中的不同元素。 在实际应用中,这些不同的字符串或许就是程序所需输入的文件名。当然你也可以使用一 个脚本来包装你的程序,然后在这个脚本中获取这个环境变量。
array.slurm
#!/bin/bash
#SBATCH -J array
#SBATCH -p cpu
#SBATCH -N 1
#SBATCH --cpus-per-task=1
#SBATCH -t 5:00
#SBATCH -a 0-2
input=(foo bar baz)
echo "This is job #${SLURM_ARRAY_JOB_ID}, with parameter ${input[$SLURM_ARRAY_TASK_ID]}"
echo "There are ${SLURM_ARRAY_TASK_COUNT} task(s) in the array."
echo " Max index is ${SLURM_ARRAY_TASK_MAX}"
echo " Min index is ${SLURM_ARRAY_TASK_MIN}"
sleep 5
提交以上脚本并使用 squeue 命令查看可以看到下面的结果:
[liuhy@admin playground]$ sbatch array.slurm
Submitted batch job 50
[liuhy@admin playground]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
50_0 cpu array liuhy R 0:01 1 comput1
50_1 cpu array liuhy R 0:01 1 comput1
50_2 cpu array liuhy R 0:01 1 comput1
2.2.6 取消作业 –scancel
scancel用于取消挂起或正在运行的作业或作业步骤。它还可用于向与正在运行的作业或作业步骤关联的所有进程发送任意信号。
scancel job_id
取消用户的作业
scancel -u 用户
如果想具有跟ctrl +c 一样的效果,需要将ctrl +c 的sig信息 SIGINT 传递进去
scancel -s SIGINT -f sbatch.sh
-s 用来传递SIGINT -b 信号传递到sbatch -f 信号不仅传递到sbatch ,还传递到sbatch中调用的脚本
更多参数参考:https://slurm.schedmd.com/scancel.html
批量取消任务:
squeue -u $USER | grep 197 | awk '{print $1}' | xargs -n 1 scancel
三、讨论
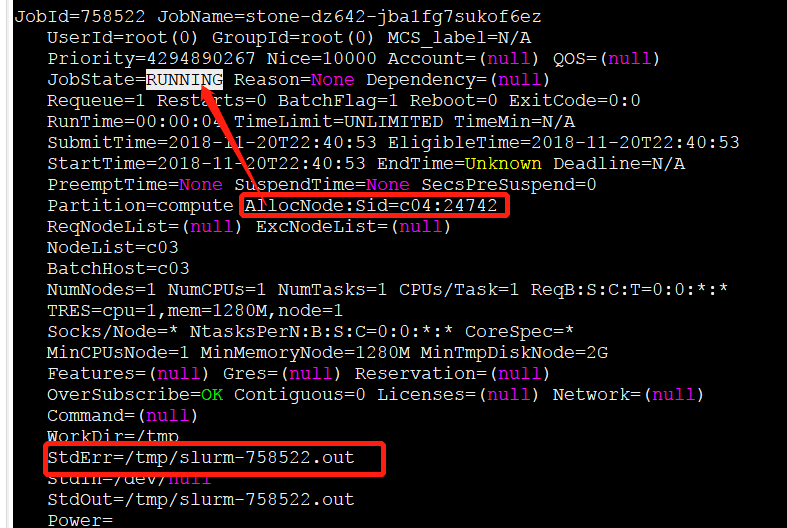
3.1 如何debug
$ scontrol show job JOBID
- allocnode是提交任务的节点
可以再通过 squeue 查看现行任务的状态
3.2 SLURM 节点状态总是drained问题
新装的 SLURM 集群在运行了一些作业并修改一些配置项目以后,用sinfo查看信息的时候看到部分节点状态总是 drained ,但是在这个节点上并没有作业在运行,重启 slurm 服务问题依旧,如下
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug* up infinite 1 drain mycentos6x
并且用 “scontrol show node”查看节点的时候看到 “Reason=Low RealMemory [root@2015-07-20T21:23:33]”,好像参数修改并没有生效
$ scontrol show node
NodeName=mycentos6x Arch=x86_64 CoresPerSocket=2
CPUAlloc=0 CPUErr=0 CPUTot=2 CPULoad=0.55 Features=(null)
Gres=(null)
NodeAddr=mycentos6x NodeHostName=mycentos6x Version=14.11
OS=Linux RealMemory=1000 AllocMem=0 Sockets=2 Boards=1
State=IDLE+DRAIN ThreadsPerCore=1 TmpDisk=0 Weight=1
BootTime=2015-07-21T09:19:03 SlurmdStartTime=2015-07-21T09:19:32
CurrentWatts=0 LowestJoules=0 ConsumedJoules=0
ExtSensorsJoules=n/s ExtSensorsWatts=0 ExtSensorsTemp=n/s
Reason=Low RealMemory [root@2015-07-20T21:23:33]
依次运行下面几个命令:
# scontrol update NodeName=<node> State=DOWN Reason=hung_completing
# /etc/init.d/slurm restart
# scontrol update NodeName=<node> State=RESUME
运行/etc/init.d/slurm restart的时候报错:
Restarting slurm (via systemctl): Job for slurm.service failed because a configured resource limit was exceeded. See “systemctl status slurm.service” and “journalctl -xe” for details.
没有搭理这个报错,继续下一步的命令,之后再查看状态
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug* up infinite 1 idle mycentos6x
3.3 修改GPU数
vim /etc/slurm/slurm.conf
GresTypes=gpu
NodeName=c01 CPUs=62
NodeName=c02 CPUs=62
NodeName=c03 CPUs=22
NodeName=c04 CPUs=42
NodeName=g02 CPUs=30 Gres=gpu:8
NodeName=g03 CPUs=70 Gres=gpu:16
NodeName=pp CPUs=8
然后将C04(主节点)上的slurm.conf同步到其他服务器
scp root@C04:/etc/slurm/slurm.conf root@C02:/etc/slurm/slurm.conf
scp root@C04:/etc/slurm/slurm.conf root@C03:/etc/slurm/slurm.conf
scp root@C04:/etc/slurm/slurm.conf root@G02:/etc/slurm/slurm.conf
scp root@C04:/etc/slurm/slurm.conf root@G03:/etc/slurm/slurm.conf
scp root@C04:/etc/slurm/slurm.conf root@C01:/etc/slurm/slurm.conf
scp root@C04:/etc/slurm/slurm.conf root@pp:/etc/slurm/slurm.conf
然后,重启slurm服务
#每个机器上重启slurmd
systemctl restart slurmd
#主节点上:
systemctl restart slurmctld
3.3 优先某个任务的级别
你看一下queue里排在最前面的job的priority
scontrol show job $jobid
把你要改的job的priority改成比那个值大 但是比4294967295小的数字
scontrol update jobid=$id priority=$higher_num
3.4 给slurm传递参数
[sam@c04 tce]$ sbatch --export=All,qq='1' test_slurm.sh
[sam@c04 tce]$ cat test_slurm.sh
#!/bin/sh
#SBATCH --partition=cpu
#SBATCH --nodes=1-1
#SBATCH --nodelist=c02
#SBATCH --cpus-per-task=50
#SBATCH --job-name="tce"
#SBATCH --output=test.out
#SBATCH --time=30000000:00:00
##SBATCH --mail-user=email
##SBATCH --mail-type=ALL
ulimit -s unlimited
echo 'test'
echo $qq
echo $qq > ${qq}.txt
四、报错
报错1:
[root@c04 tmp]# srun slurm.test
slurmstepd: error: execve(): slurm.test: Permission denied
srun: error: c03: task 0: Exited with exit code 13
报错原因:
slurm.test没有执行权限
解决办法:
chmod 775 slurm.test
报错2
一个节点一个任务
每个节点,都进行修改
vim /etc/slurm/slurm.conf
DefMemPerCPU=1024
JobAcctGatherParams=NoOverMemoryKill
每个机器上重启slurmd
systemctl restart slurmd
主节点上:
systemctl restart slurmctld
报错:
exceeded job memory limit
slurm.conf中,添加上下面一句,即可
JobAcctGatherParams=NoOverMemoryKill
报错3
sinfo: error: slurm_receive_msg: Zero Bytes were transmitted or received slurm_load_partitions: Zero Bytes were transmitted or received
解决办法:
#查看时间
date
##手动修改时间
date -s 15:26:45
##查看修改的时间
date
##时间生效
hwclock -w
参考资料
