【2.3】charles抓包网页数据
最近跟几个小伙伴迷恋上了一部音频节目,所幸在网上找到了免费的网页资源(原谅贫苦工薪阶级找免费资源的习惯),但是一集集的打开很是麻烦,于是琢磨,能不能把资源都下下来。刚开始觉得应该是很简单的一个事情,无非就是爬虫获取音频的链接地址,然后下载即可,可是真的去做时候,发现还是很麻烦的,因为那个音频做了一些设置,只能用手机流浪器连续听,所以这就需要模拟一下手机浏览器。
先来科普一下什么叫抓包?
抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。
数据在网络上是以很小的称为帧(Frame)的单位传输的,帧由几部分组成,不同的部分执行不同的功能。帧通过特定的称为网络驱动程序的软件进行成型,然后通过网卡发送到网线上,通过网线到达它们的目的机器,在目的机器的一端执行相反的过程。接收端机器的以太网卡捕获到这些帧,并告诉操作系统帧已到达,然后对其进行存储。就是在这个传输和接收的过程中,嗅探器会带来安全方面的问题。
每一个在局域网(LAN)上的工作站都有其硬件地址,这些地址惟一地表示了网络上的机器(这一点与Internet地址系统比较相似)。当用户发送一个数据包时,如果为广播包,则可达到局域网中的所有机器,如果为单播包,则只能到达处于同一碰撞域中的机器。
在一般情况下,网络上所有的机器都可以“听”到通过的流量,但对不属于自己的数据包则不予响应(换句话说,工作站A不会捕获属于工作站B的数据,而是简单地忽略这些数据)。如果某个工作站的网络接口处于混杂模式,那么它就可以捕获网络上所有的数据包和帧。
一、charles简介
Charles其实是一款代理服务器,通过过将自己设置成系统(电脑或者浏览器)的网络访问代理服务器,然后截取请求和请求结果达到分析抓包的目的。该软件是用Java写的,能够在Windows,Mac,Linux上使用。安装Charles的时候要先装好Java环境。
安装
安装方法下载破解版,安装即可
安装包地址:https://pan.baidu.com/s/1caploU
破解补丁地址:https://pan.baidu.com/s/1hrRpzda
(1)按照步骤下载安装第一个安装包;
(2)将破解补丁包粘贴到charles的lib文件下,然后将原来的命名为charles的文件替换掉 即可
其他获取软件地址:
- 百度云盘链接:https://pan.baidu.com/s/1dG5QxZN 密码:dd5r
- 官方网址:https://www.charlesproxy.com/
- 破解jar包获取地址:https://www.zzzmode.com/mytools/charles/
注:
有的电脑,可能需要授权软件。具体操作顺序如下:
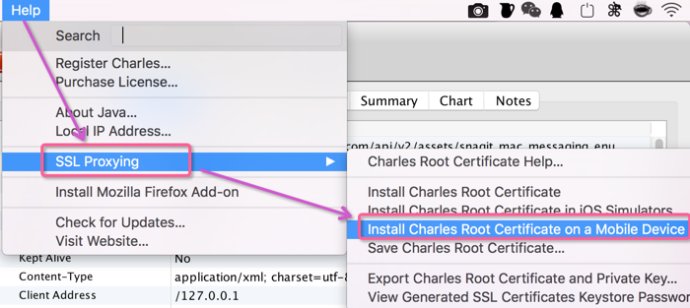
help – SSL Proxying – Install Chales Root Certificate – 之后会弹出钥匙串,如果没有弹出,请自行打开 Charles Proxy Custom Root Certificate ,系统默认是不信任 Charles 的证书的,此时对证书右键,在弹出的下拉菜单中选择『显示简介』,点击使用此证书时,把使用系统默认改为始终信任.
二、使用
2.1 电脑端
电脑端的使用很简单,无非就是打开软件以后,再打开网页,就会在chales软件上看到对应的网页的各种信息,
比如我在流浪器中打开 ”百度” 的网页,就在charles中看到定的Header的信息
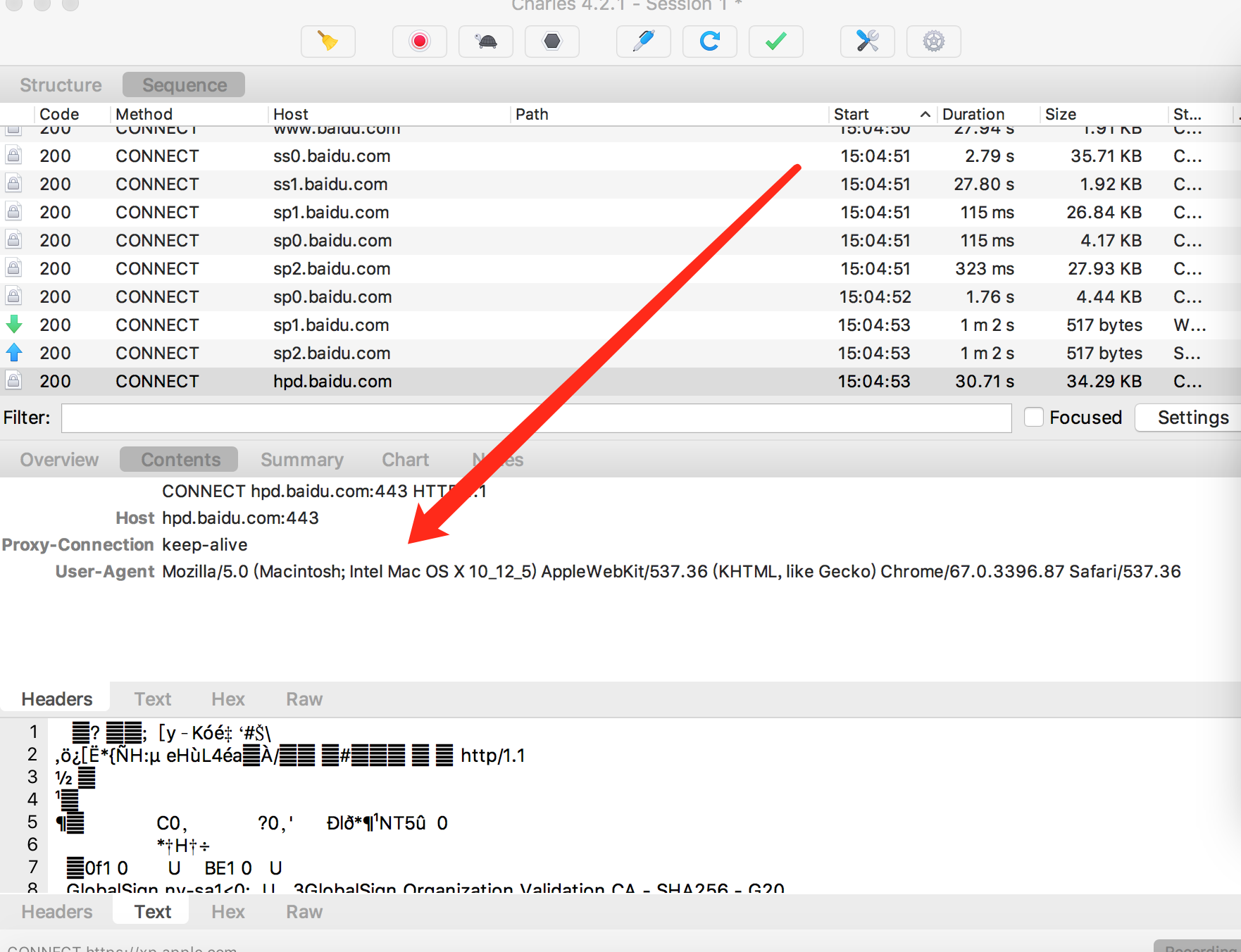
把header信息提出来,就可以模拟流浪器进行爬虫了。
2.2 手机端
选择在移动设备上安装 Charles 根证书:
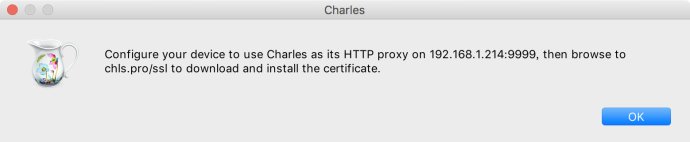
会弹出一个提示框,默认接口为8888,如下图:
进入手机设置界面(华为的手机的话,WLAN– 需要长按连接的wifi后,出现 “修改网络” – ”显示高级选项“–‘代理’ – ‘手动’– 输入上面的IP和端口):
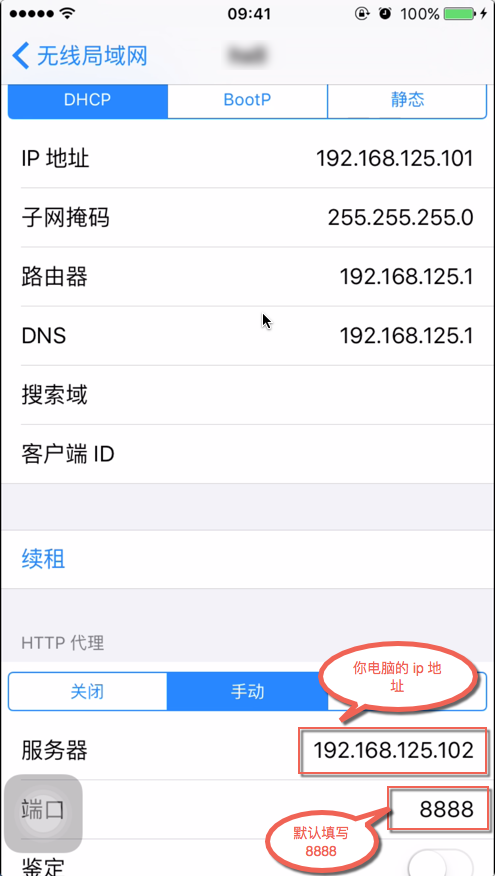
然后打开手机的浏览器,输入chls.pro/ssl,选择下载即可。
接着,就可以在手机上打开那个音频网站,对应的Header信息就会出现在charles中,提取出来,就可以伪装成流浪器进行爬虫咯。
三、python 爬虫代码
附上我爬虫的代码吧。。
#!coding:utf-8
import os
from bs4 import BeautifulSoup
import requests
import time
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
url = '音频网址'
def download(result_dir):
if not os.path.exists(result_dir) :
os.mkdir(result_dir)
for ii in range(236,400):
header = {
'Host':'**********免得告我侵权呀,不放这个链接了',
'Upgrade-Insecure-Requests': '1',
'User-Agent': '**********免得告我侵权呀,不放这个链接了',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': '**********免得告我侵权呀,不放这个链接了',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-Hans-CN,en-US;q=0.8',
'Cookie': '**********免得告我侵权呀,不放这个链接了",
}
download_link = '%s/%s.html' % (url,ii)
response = requests.get(download_link,headers = header)
demo = response.text
soup = BeautifulSoup(demo, 'html.parser')
one_audio = soup.find_all('audio')[0].find_all('source')[0]['src']
cmd = """wget -c -O %s/%s.m4a --user-agent="Mozilla/5.0 (Linux; U; Android 7.0; zh-CN; HUAWEI CAZ-AL10 Build/HUAWEICAZ-AL10) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.108 UCBrowser/12.1.1.991 Mobile Safari/537.36" %s """ % (
result_dir, ii, one_audio)
os.system(cmd)
print 'downloaded %s ' % (ii)
time.sleep(500)
小插曲:
本来模拟的是PC端的浏览器,可是爬取两集以后,就提示我用手机打开,没办法,只好又重新模拟手机浏览器
参考资料
