【6.2.2】Faith Phylogenetic Diversity谱系多样性
生物多样性是复杂的,不同的角度看到的东西是不一样的。 为了量化这种特性,发明了各种测量和评估方法。 谱系多样性就是其中一种。其已经在保护生物学和群落生态研究中大量应用。
如谱系多样性指数(phylogenetic diversity,PD)在预测湿地群落对某入侵种的耐受度时要优于物种丰富度指数(species richness, SR)
- Phylogenetic diversity is a better predictor of wetland community resistance to Alternanthera philoxeroides invasion than species richness。 https://onlinelibrary.wiley.com/doi/abs/10.1111/plb.13101
- Simon Véron, Victor Saito, Nélida Padilla-García, Félix Forest, and Yves Bertheau, “The Use of Phylogenetic Diversity in Conservation Biology and Community Ecology: A Common Base but Different Approaches,” The Quarterly Review of Biology 94, no. 2 (June 2019): 123-148。 https://doi.org/10.1086/703580
一、什么是谱系多样性
一般地,生物多样性简单的讲来就是研究生物的数量和差异,不同生境的物种数量多少有没有差异,不同物种之间的数量组成差异大不大。这些都是关于物种丰富度(richness)以及均匀度的统计。
随着一个生境里面物种多度(abundance)的增加,丰富度和均匀度等传统的生物多样性指数通常也会随之增加。
比如生态学研究中经常用到的物种累积曲线,你会发现随着多度的增加物种的多样性(通常用丰富度richness来表示)也会增加。这个曲线你会发现一般都是不断增长的,不过是后来增长缓慢了,但是并没有停止增长。也就是说只要增加采样的个体,一般来说物种数量也会缓慢增长。后期的增加可能是那些不容易被发现的物种进入了统计,或者说随着你采集的样本数变多,越来越多的稀有种被发现了。
接下里让我们换个角度看问题:
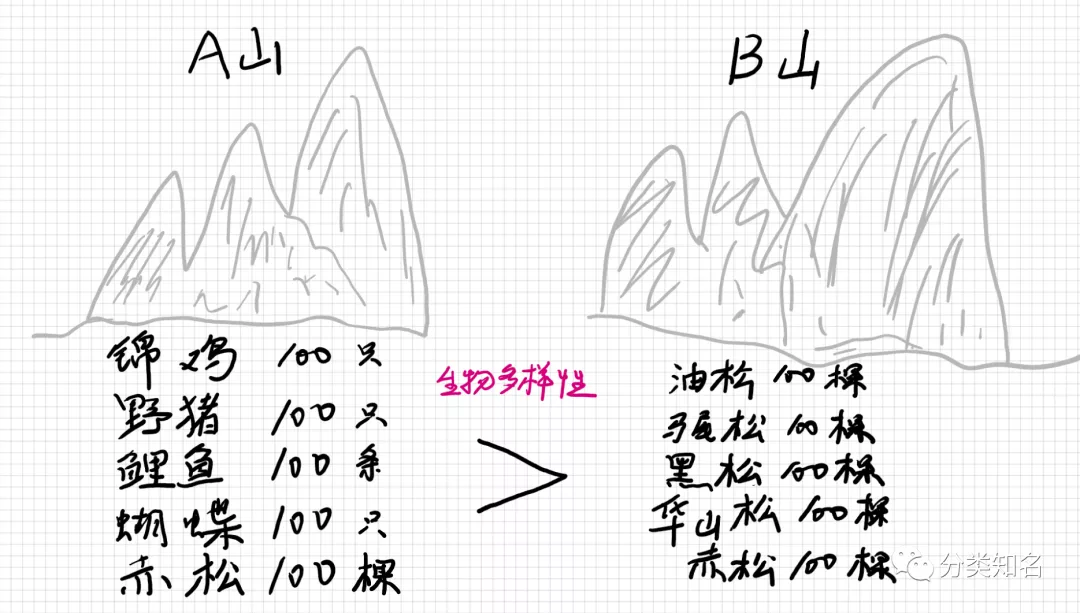
传统的生物多样性指数考虑的是物种的数量和组成差异,但是我们也很容易注意到物种和物种是不同的,有些物种的亲缘关系更近,有些则较远。
设想,A B两座山,都是500个生物。
- A山呢有锦鸡、野猪、鲤鱼、蝴蝶、赤松各100;
- B山头呢,油松、马尾松、黑松、华山松、赤松各100个。
下面我们用R中的BiodiversityR包来计算香浓多样性指数和均匀度指数来观察一下有无区别:
library("BiodiversityR")
# 根据上面的假设,制作AB两个山的多样性采样数据
Abio <- c(100, 100, 100, 100, 100)
dim(Abio) <- c(1, 5)
Abio <- as.data.frame(Abio)
names(Abio) <- c("锦鸡", "野猪","鲤鱼","蝴蝶","赤松")
Abio #A山
Bbio <- c(100, 100, 100, 100, 100)
dim(Bbio) <- c(1, 5)
Bbio <- as.data.frame(Bbio)
names(Bbio) <- c("油松", "马尾松","黑松","华山松","赤松")
Bbio #B山
多样性数据情况:

多样性指数计算
#香浓多样性指数
diversityresult(Abio, index="Shannon", method="pooled")
diversityresult(Bbio, index="Shannon", method="pooled")
#均匀度
diversityresult(Abio, index="Jevenness", method="pooled")
diversityresult(Bbio, index="Jevenness", method="pooled")

如上图,香浓多样性指数都是1.6094379,均匀度也都是最大值1。
可以发现,A山和B山的生物多样性指数完全没有差别!
但是直觉告诉我们,这两个山的多样性是有区别的!
- A:地上跑的,天上飞的,水里游的,还有大松树,好不热闹!
- B:只有一片树,还都是松科的。
B的多样性或者说是差异性显然要比A更低。为了刻画这种差异,谱系生物多样性的概念就引出来了。这个概念简单说来就是考虑了一个生境中不同的生物组分之间的亲缘关系。亲缘关系越复杂,指数越高,如A山;反之则指数低,如B山。
二、谱系多样性指数的计算
Picante: R tools for integrating phylogenies and ecology : https://academic.oup.com/bioinformatics/article/26/11/1463/203321
Picante是R中用于谱系多样性指数计算的软件包,目前该篇文章已经引用了多达2500多次了。
下面计算最早提出的一个谱系多样性指数Phylogenetic diversity (PD) index,该指数由 Faith (1992) 提出。 Faith D.P. (1992) Conservation evaluation and phylogenetic diversity. Biological Conservation, 61, 1-10.
2.1. 安装并加载包里提供的示例数据
install.packages('picante')
library(picante)
data(phylocom)
names(phylocom)
phy <- phylocom$phylo # "phylo" class
comm <- phylocom$sample # "matrix" class
phy包含32个tips的树文件;comm是包含25个物种6个样方的群落数据。

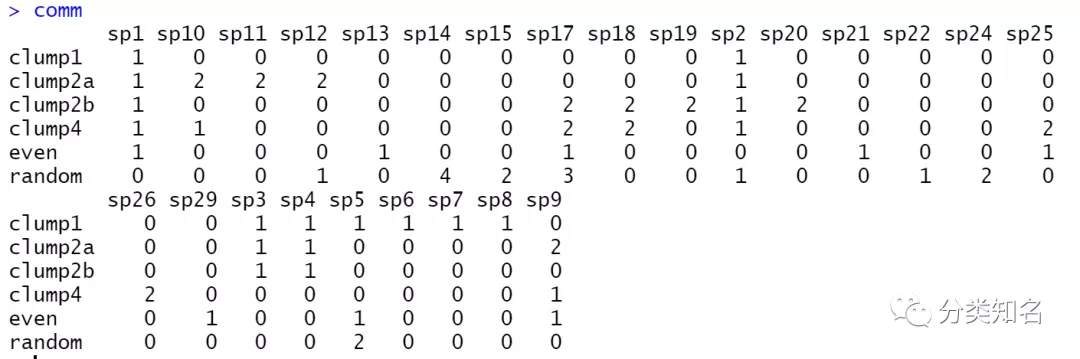
2.2 可视化数据
#对群落的每个样方里出现的物种以红点画在系统树上
par(mfrow = c(2, 3))
for (i in row.names(comm)) {
plot(phy, show.tip.label = T, main = i)
tiplabels(tip = which(phy$tip.label %in% names(which(comm[i, ] >
0))), pch=19, cex = 1, col='red')
}
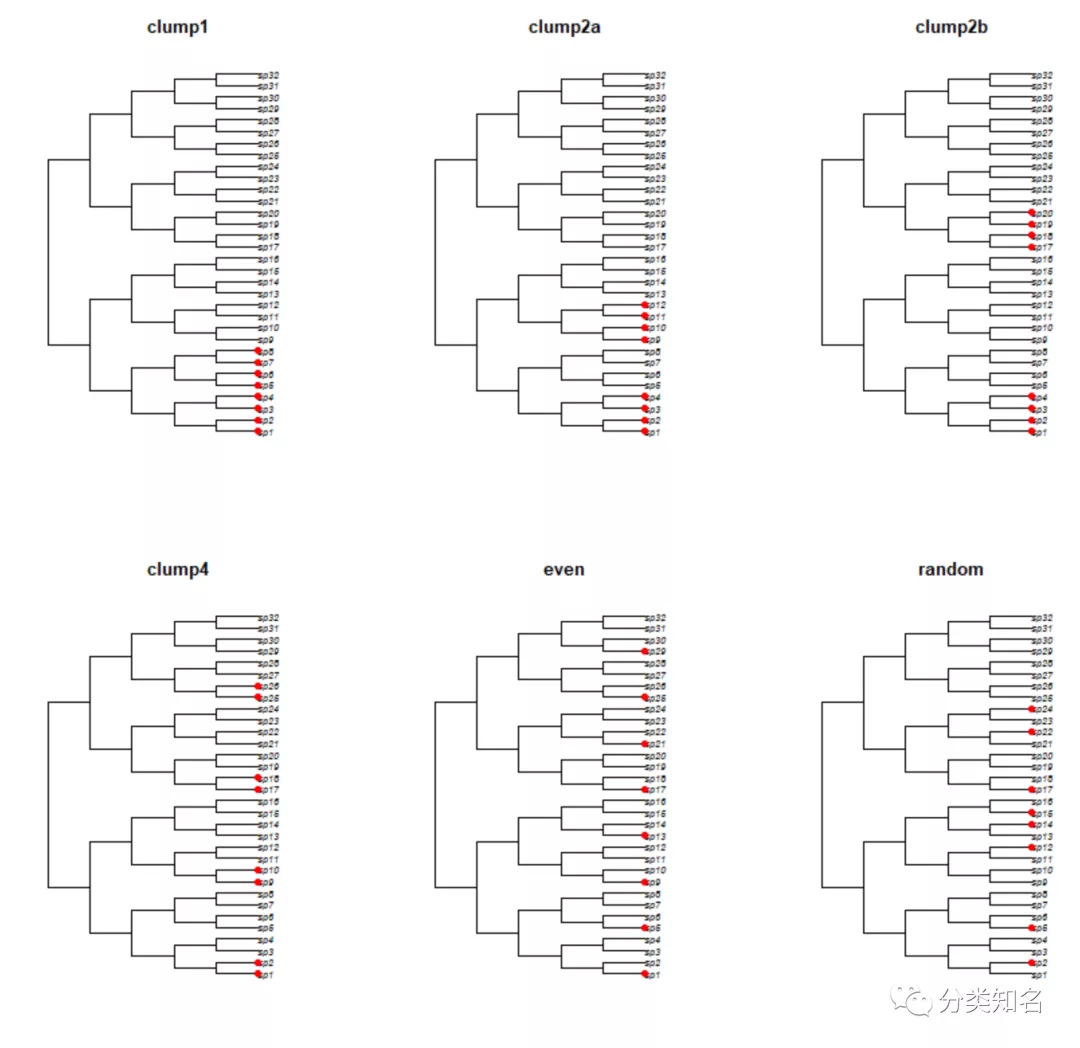
6个样方的物种分别标记在系统树上
上图可以看到,这6个样方里,哪些样方里的物种在系统树上更加散布,哪些更为集中。那些更加散布的样方里,系统发育信号显然更多些。
2.3. 计算PD
谱系多样性(Phylogenetic diversity,PD)定义为在系统发育树上跨越给定的一组分类群所经过的所有系统发育分支的最小总长度(Faith,1992)。
Phylogenetic diversity (PD) index proposed by Faith (1992). Faith’s PD is defined as the total branch length spanned by the tree including all species in a local community.
pd.result <- pd(comm, phy, include.root = TRUE)
pd.result

结果返回PD值和SR(物种丰富度)。如上,物种丰富度一样都是8个,但是PD值最高的是even样方,与可视化图上的直观结论是一致的。
参考资料
