【5.1】一种简化的分子语言--SMILES
一.什么是SMILES
SMILES,全称是Simplified Molecular Input Line Entry System,是一种用于输入和表示分子反应的线性符号,是一种ASCII编码,下面看一些例子:
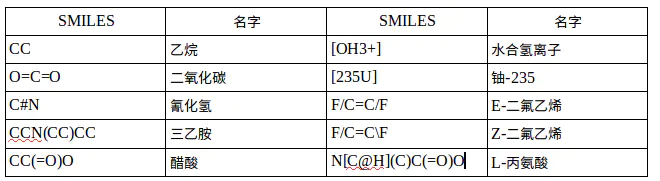

SMILES包含的信息可能与一些扩展的源数据表相同,SMILES更适用的主要原因是它是一种语言结构,而不是计算机数据结构。 SMILES是一种真正的语言,虽然只有简单的词汇(原子和键符号)和少数语法规则。 SMILES结构表示可以反过来用作其他语言词汇表中的“word”,用于存储化学信息(化学品信息)和化学信息。
二.SMILES的优点是啥
1. 唯一性 .SMILES强大的一点就是存在一种唯一的SMILES,使用标准的SMILES,分子的名字和结构是同义的,在唯一的SMILES里面,这也是通用的,世界上任何使用SMILES命名分子的人都会选择完全相同的名字
2. 节省空间. SMILES的另一个重要特性是,与大多数其他表示结构的方法相比,它能节省存储空间。SMILES占用的空间甚至比二进制表减少50%至70%,甚至是二进制连接表。 例如,23,137个结构的数据库,每个结构平均有20个原子,当用SMILES表示时,每个原子仅使用1.6个字节。 此外,SMILES的压缩非常有效。 通过Ziv-Lempel压缩(即每个原子0.42个字节),上面引用的相同数据库存储内存减少到其原始大小的27%。
三.SMILES有什么用
- 数据库关键字访问
- 研究人员化学信息的交流机制
- 化学数据输入
- 人工智能和化学专家的语言
四. SMILES规范
SMILES把分子结构表示为 任意的手性特征图,这本质上就是分子家描述分子结构的二维图片
- 仅仅描述分子图(即原子和键,没有手性或者同位素信息)的SMILES叫做一般SMILES.对于给定的结构,通常有很多一般SMILES表示方法;
- 规范化算法用于在所有有效可能性中生成一个特殊的通用SMILES,这个特殊的SMILES叫做唯一的SMILES;
- 用同位素和手性规格书写的SMILES叫做异构体SMILES;
- 唯一的异构体SMILES叫做绝对SMILES.
看下面的例子

五. 格式规则
SMILES 表示法由一系列不包含空格的字符组成。 可以省略氢原子(氢抑制图)或不省略氢原子(氢完全图)。 芳香结构可以直接指定或以Kekulé形式指定
有五种通用的SMILES编码规则,对应于原子,键,分支,闭环和断开的规范。 有关指定各种异构现象的规则不这一节范围
1. 原子
- 原子用它们的原子符号表示:这是SMILES中唯一需要使用的字母,每个非氢原子由其括在方括号[]中的原子符号独立指定
- B,C,N,O,P,S,F,Cl,Br和I,如果连接的氢原子数量和原子的最低正化合价相同,则[]可以省略 * 双字符符号的第二个字母必须以小写字母输入
- 芳香环中的原子由小写字母表示,脂肪族碳由大写字母C表示,芳族碳由小写字母c表示
以下原子符号是有效的SMILES符号:
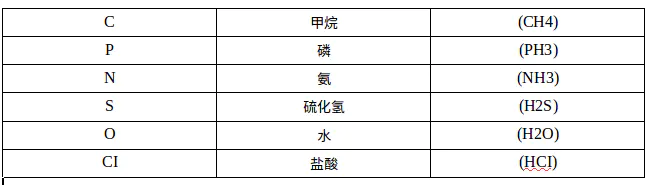
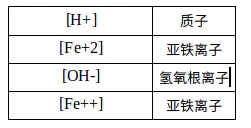
在括号内,必须始终指定连接的氢原子数量和原子当前的化合价。氢的数量用符号H表示,后跟可选数字。类似地,化合价由符号+或 - 之一表示,后跟可选数字。如果未指定,则对于括号内的原子,就假定连接的氢和电荷的数量为零。[Fe +++]形式的构造与[Fe + 3]形式同义。 例子是:
2. 键
* 单键,双键,三键和芳香键分别用符号 - ,=,#和:表示 * 假设相邻原子通过单键或芳香键相互连接(可以总是省略单键和芳键)

对于线性结构,SMILES和传统的图解符号相比,只是省略了H和单键,例如6-羟基-1,4-己二烯可有许多同等有效的SMILES代表,包括以下三 种:

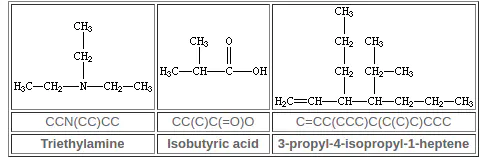
3. 分支
带有分支的原子写在左侧,通过()指定,可以堆叠,分支上的元素写在右侧
4. 闭环
通过在每个环中断开一个键来表示环状结构。 该键以任何顺序编号,在每个闭环时紧跟原子符号后用数字表示开环(或闭环)键。这就让一个连接起来的非循环图使用上述三个规则写为非循环结构。 环己烷是一个典型的例子:
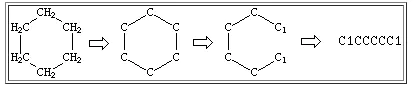
通常同一个闭环有不同的有效SMILES

如果需要,表示环闭合的数字可以重复使用。例如,数字1在规范中使用了两次:
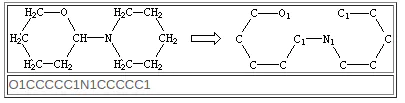
5. 断开结构
* 断开的化合物被写成由.分隔的单独结构,列出离子或配体的顺序是任意的。
- 如果需要,可以将一种离子的SMILES嵌入另一种离子中
如苯酚钠的实例所示
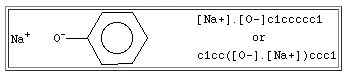
由点 . 分隔的相邻原子意味着原子彼此不键合
六. 异构体SMILES
这里介绍用于指定同位素的SMILES规则,关于双键的配置和手性。 术语异构体SMILES统称为使用这些规则编写的SMILES。SMILES异构体规则允许为任何结构完全指定手性,因此,SMILES中的所有异构体规范规则都是可选的。 缺少任何属性的规范意味着未指定该属性的值。
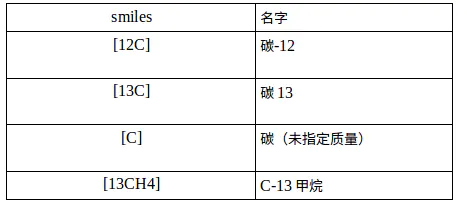
1. 同位素规则
同位素规范是指在原子符号前面用一个数字表示所需的原子质量的数目。原子质量只能在括号内指定。例如:
2. 围绕双重建的配置
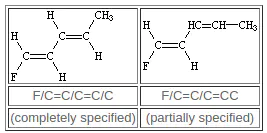
双键周围的配置由/和 \ 指定,它们是“方向键”,可以被认为是单键或芳香键(例如默认键)的种类。 这些符号表示连接原子之间的相对方向性,并且只有当它们出现在两个双键连接的原子上时才有意义。 例如,以下SMILES均适用于E-和Z-1,2-二氟乙烯:

SMILES手性惯例与其他手段(如CIP)之间的一个重要区别是SMILES使用局部手性表示(与绝对手性相反),下面举例说明:
### 3. 四面体中心周围的配置
SMilES使用基于局部手性的非常普遍的手性规范。取代使用基于规则的编号方案来排序手性中心的邻近原子,取向基于邻居在SMILES字符串中出现的顺序
最简单和最常见的手性是四面体,四个相邻原子在一个中心原子上均匀排列,称为“手性中心”。如果所有四个邻居以不同的方式彼此不同,则该结构的镜像将不相同。这两个镜像被称为“对映体”,是一个四面体中心的唯一的两种形式。如果两个(或多个)四个邻居彼此相同,则中心原子将不是手性的(它的镜像可以叠加在空间中)。
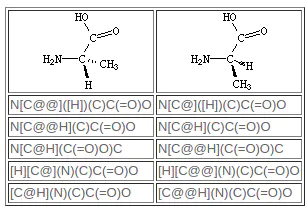
在SMILES中,四面体中心可以用一个简化的手性规范(@或@@)来表示,这是一个原子属性,它遵循手性原子的原子符号。如果手性规范不存在于手性原子中,则其手性不指定。例如:

从氨基N到手性C(如SMIELS所写),其他三个邻居按照它们写在顶部SMILES中的顺序逆时针出现,NC@(F)C(=O)O(甲基-C,F,羧基-C),在底部顺时针, NC@@(C)C(=O)O。 符号“@”表示以下邻居是逆时针列出的 “@@”表示邻居是顺时针列出的(反时针方向)。
如果中心碳不是SMILES中的第一个原子并且具有附着的隐含氢(它可以具有至多一个并且仍然是手性的),则隐含的氢被认为是跟随的三个 邻居的第一个邻近原子。 四面体规范。 如果中心碳首先出现在SMILES中,则隐含的氢被认为是“来自”原子。 氢可以总是明确写出(如[H]),在这种情况下,它们被视为与任何其他原子一样。 在每种情况下,隐含的顺序与SMILES中的顺序完全相同。 一些有效的丙氨酸SMILES是:
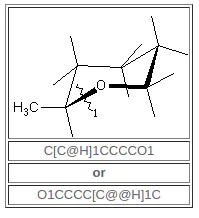
环闭合键的手性顺序由环闭合数字出现在手性原子上的词汇顺序暗示(不是“取代基”原子的词汇顺序)。
七. SMILES公约
除上述规则外,SMILES中普遍使用少量约定。这里简要讨论
1. 氢
在为大多数有机结构编写SMILES时,通常不需要指定氢原子。 氢的存在可以通过三种方式指定:
* 对于没有括号指定的原子,从正常的价假设。
- 在括号内,通过提供的氢计数明确计数;如果未指定,则为零。
- 作为显式原子……[H]原子。
“有机”和“无机”SMILES命名法之间没有区别。 可以指定任何SMILES中任何原子的连接氢的数量。 例如,丙烷可以作为[CH3] [CH2] [CH3]而不是CCC输入。
有四种情况需要明确氢气规范的规范:
- 带电的氢,即质子,[H +]
- 与其他氢连接的氢,例如分子氢,[H] [H]
- 氢连接到除另一个原子以外的氢
- 同位素氢规格,例如 在重水中,[2H] O [2H]
2. 芳香性
SMILES算法使用Hueckel规则的扩展版本来识别芳香分子和离子。为了具有芳香性,环中的所有原子必须是sp2杂化的,并且可用的“过量”p电子的数量必须满足Hueckel的4N + 2标准。例如,苯写成c1ccccc1,但C1 = CC = CC = C1 - 环己三烯(Kekulé形式)的条目导致芳香性的检测并导致内部结构转换为芳香族表示。相反,c1ccc1和c1ccccccc1的条目将产生环丁二烯和环辛四烯的正确抗芳香结构,C1 = CC = C1和C1 = CC = CC = CC = C1。在这种情况下,SMILES系统寻找一种结构,该结构保留隐含的sp2杂交,隐含的氢计数和指定的正式电荷(如果有的话)。但是,某些输入可能不仅是不正确的,而且也是不可能的,例如c1cccc1。这里c1cccc1不能转化为C1 = CCC = C1,因为其中一个碳原子是sp3,带有两个连接的氢。在这种结构中,不能进行交替的单键和双键分配。 SMILES系统会将此标记为“不可能”的输入。请注意,以下列表中的原子只能被视为芳香族:C,N,O,P,S,As,Se和*(通配符)。此外,环外双键不会破坏芳香性。
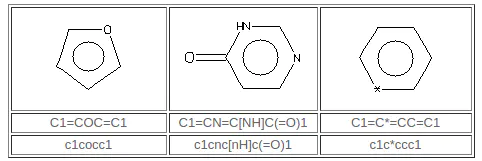
重要的是要记住,SMILES芳香性检测算法的目的仅仅是为了化学信息表示!
3. 绑定约定
SMILES没有规定应该使用哪种化合价来模拟分子结构。 事实上,使用SMILES的一个优点是它能够描述相同结构的各种价模型。 可以连接原子并根据需要显示电荷分离。 例如,硝基甲烷可以在SMILES中表示为CN(= O)= O或电荷分离C [N +](= O)[O-](我们倾向于使用前者用于数据库工作,因为它保持对称性)。 两者都是“正确的”,因为它们代表了物质的不同的,有用的模型。 一般来说,当对称性不成问题时,大多数化学家更喜欢电荷分离结构,如果它们可以避免代表处于不寻常价态的原子,例如,重氮甲烷写成C = [N +] = [N-]而不是C = [N] =[N]。
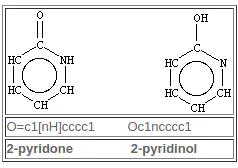
4. 互变异构体
在SMILES中明确指定了互变异构结构。 没有“互变异构键”,“移动氢”,也没有“移动电荷”规范。 选择一种或所有互变异构结构留给使用者并且很大程度上取决于应用。 给定一种互变异构形式,如果需要,大多数化学信息系统将报告所有已知互变异构体的数据。 SMILES的作用是确切地指定请求哪种互变异构形式,以及哪些有数据。 一个简单的例子,有两种可能的互变异构形式,如下所示:
参考资料
