Linux【2】-管理文件-7-正则表达
一、基本概念
1.1 什么是正则表达式
- 正则表达式就是为了处理大量的文本|字符串而定义的一套规则和方法
- 通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串。Linux正则表达式一般以行为单位处理。
通俗点说,就用一种简单的语法表达重复或者大量的有规律的橘子
1.2 为何使用正则表达式
linux运维工作,大量过滤日志工作,化繁为简。
简单,高效。
1.3 容易混淆的两个注意事项
- 正则表达式应用非常广泛,存在于各种语言中,php perl grep sed awk 支持。ls * 通配符
- 但现在学的是Linux中的正则表达式,最常应用正则表达式的命令是grep(egrep),sed,awk。
- 正则表达式和通配符有本质区别: 正则表达式用来找:【文件】内容,文本,字符串。一般只有三剑客支持;通配符用来找:文件名,普通命令都支持
1.4 正则表达式使用注意事项
- linux正则表达式以行为单位处理字符串
- 便于区别过滤出来的字符串,一定配合grep/egrep命令学习。
二、正则的使用
2.1 正则表达式的分类
POSIX规范将正则表达式的分为了两种:
- 基本正则表达式(BRE,basic regular expression)
- 高级功能:扩展正则表达式(ERE,extended regular expression)
BRE和ERE的区别仅仅是元字符的不同:
- BRE(基础正则表达式)只承认的元字符有^$.[]* 其他字符识别为普通字符:
\(\) - ERE(扩展正则表达式)则添加了(){}?+|等 只有在用反斜杠“”进行转义的情况下,字符(){}才会在BRE被* 当作元字符处理,而ERE中,任何元符号前面加上反斜杠反而会使其被当作普通字符来处理
2.2 如何区分通配符和正则表达式
- 不需要思考的判断方法:在三剑客awk,sed,grep,egrep都是正则,其他都是通配符
- 区别通配符和正则表达式最简单的方法:
- 文件目录名===>通配符
- )文件内容(字符串,文本【文件】内容)===>正则表达式
通配符和正则表达式都有“*”,“?”,“【】”,但是通配符的这些符号都能自身代表任意字符,而正则表达式的这些符号只能代表这些符号前面的字符
2.3 基本正则表达式
^word 用来搜索word开头的内容
tanqianshan[Downloads]$ cat tmp.tsv
abc
bc
tanqianshan[Downloads]$ grep "^a" tmp.tsv
abc
word$ 搜索word结果的内容
tanqianshan[Downloads]$ cat tmp.tsv
abc
bc
tanqianshan[Downloads]$ grep "c$" tmp.tsv
abc
bc
^$ 表示空行,不是空格
tanqianshan[Downloads]$ cat -n tmp.tsv
1 abc
2
3 bc
tanqianshan[Downloads]$ grep -n "^$" tmp.tsv
2:
. 代表且只能代表任意一个字符(不匹配空行)
tanqianshan[Downloads]$ cat tmp.tsv
abc
bc
tanqianshan[Downloads]$ grep ".b" tmp.tsv
abc
\ 转义字符,让有特殊含义的字符脱掉马甲,先出原型,如 \. 只表示小数点。
- 重复之前的字符或文本0个或多个,之前的文本或字符连续0次或多次
.* 任意多个字符
^.* 以任意多个字符串开头
[] 匹配字符集
$ echo -e "Call\nTall\nBall" | sed -n '/[CT]all/ p'
Call
Tall
[^] 排除字符集
$ echo -e "Call\nTall\nBall" | sed -n '/[^CT]all/ p'
Ball
[-]字符范围。
$ echo -e "Call\nTall\nBall" | sed -n '/[C-Z]all/ p'
Call
Tall
[abc] 匹配字符集合内的任意一个字符a或b或c,可以写成[a-c]
[a-z] 匹配所有小写字母;
[0-9] 0到9任意一个数
[^abc] 匹配不包含^后的任意字符a或b或c,是对[abc]的取反,且与^含义不同
a\{n,m\} 重复前面a字符n到m次(如果用egrep或sed -r可去掉斜线)
a\{n,\} 重复前面a字符至少n次,如果用egrep或sed -r可去掉斜线
a\{n\} 重复前面a字符n次,如果用egrep或sed -r可去掉斜线
| 或操作。
echo -e "str1\nstr2\nstr3\nstr4" | sed -n '/str\(1\|3\)/ p'
str1 str3
2.4 扩展正则表达式ERE
| 特殊字符 | 含义 |
|---|
- |重复前一个字符一次或一次以上,前一个字符连续一个或多个,把连续的文本/字符取出 ? |重复前面一个字符0次或1次(.是有且只有1个) 管道符| | 表示或者同时过滤多个字符 () | 分组过滤被括起来的东西表示一个整体(一个字符),后向引用
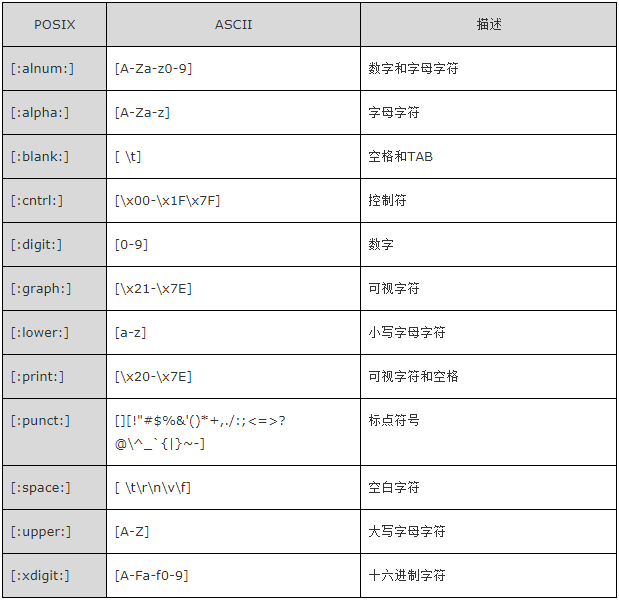
2.5 一些预定义的
2.6 元字符
元字符是一种Perl风格的正则表达式,只有一部分文本处理工具支持它,并不是所有的文本处理工具都支持
| 正则表达式 | 描述 | 示例 |
|---|---|---|
| \b | 单词边界 | \bcool\b匹配cool,不匹配coolant |
| \B | 非单词边界 | cool\B匹配coolant不匹配cool |
| \d | 单个数字字符 | b\db匹配b2b,不匹配bcb |
| \D | 单个非数字字符 | b\Db匹配bcb不匹配b2b |
| \w | 单个单词字符(字母,数字与_) | \w匹配1或a,不匹配& |
| \W | 单个非单词字符 | \W匹配&,不匹配1或a |
| \n | 换行符 | \n匹配一个新行 |
| \s | 单个空白字符 | x\sx匹配xx,不匹配xx |
| \S | 单个非空白字符 | x\S\x匹配xkx,不匹配xx |
| \r | 回车 | \r匹配回车 |
| \t | 横向制表符 | \t匹配一个横向制表符 |
| \v | 垂直制表符 | \v匹配一个垂直制表符 |
| \f | 换页符 | \f匹配一个换页符 |
参考资料
药企,独角兽,苏州。团队长期招人,感兴趣的都可以发邮件聊聊:tiehan@sina.cn
![]() 个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
