【1.2】一致度、相似度和同源度
现在学会了序列比对,我们就可以先给这两条长度不同 的序列做全局比对,然后计算全局比对中一致字符的个数和相似字符的个数,再除以全局比 对的长度,就可以得到它们的一致度和相似度了。比如下面这两条序列:
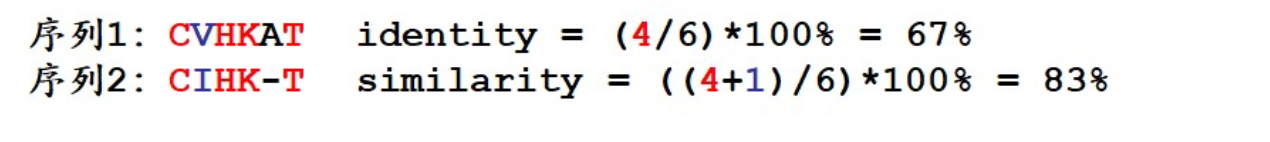
首先做出它们的全局比对,比对中一致字符的个数是 4 个,全局比对长度 6,一致度=67%。 相似字符个数 1,相似度就是(4+1)/6=83%。
由此,我们必须回过头来,把长度相同的两个序列计算一致度和相似度的方法重新规范 一下。尽管长度相同,但是做出的全局比对的长度并不一定等于序列的长度,比如下面这两 条序列:
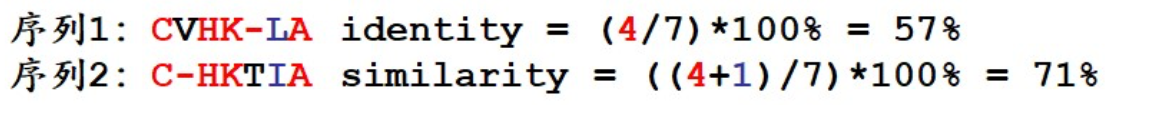
上下各加入一个空位,全局比对的长度就不等于序列的长度了。所以不管两条序列长度是否 相同,都要先对它们做全局比对。让两条序列先以最优的方式比对起来,再从全局比对中数 出一致字符和相似字符的个数,除以全局比对的长度,来得到它们的一致度和相似度。
Identity,Similarity,Homology
-
Identity: the occurrence of exactly the same nucleotide or amino acid in the same position in aligned sequences.(完全一致性)
-
Similarity: measure the sameness or difference of the sequences(相似程度)
-
Homology: is defined in terms of shared ancestors. Homologous sequences are often similar. Sequence regions that are homologous are also called conserved regions. (进化上的概念,同源有相同的祖先,同源序列大多保守)
Always compare Protein sequences if the query sequences。(最好是有蛋白序列的比对) encode proteins. Remember:
- Similarity does not imply homology!(相似不代表同源)
- Non-homology cannot from non-similarity.(但不同源肯定不会相似)
- Do not use the term “percent homology”.(不要用百分之多少同源性)
相似性和同源性
如上所述,数据库搜索的基础是序列的相似性比对,而寻找同源序列则是数据库搜索的主要目的之一。所谓同源序列,简单地说,是指从某一共同祖先经趋异进化而形成的不同序列。必须指出,相似性(similarity)和同源性(homology)是两个完全不同的概念。相似性是指序列比对过程中用来描述检测序列和目标序列之间相同DNA碱基或氨基酸残基顺序所占比例的高低。当相似程度高于50%时,比较容易推测检测序列和目标序列可能是同源序列;而当相似性程度低于20%时,就难以确定或者根本无法确定其是否具有同源性。总之,不能把相似性和同源性混为一谈。所谓“具有50%同源性”,或“这些序列高度同源”等说法,都是不确切的,应该避免使用。
相似性概念的含义比较广泛,除了上面提到的两个序列之间相同碱基或残基所占比例外,在蛋白质序列比对中,有时也指两个残基是否具有相似的特性,如侧链基团的大小、电荷性、亲疏水性等。在序列比对中经常需要使用的氨基酸残基相似性分数矩阵,也使用了相似性这一概念。此外,相似性概念还常常用于蛋白质空间结构和折叠方式的比较。
参考资料:
山东大学 生物信息学课题组荣誉出品 http://www.crc.sdu.edu.cn/bioinfo 巩晶老师课件
