【9.1.6】kpLogo--位置k聚体分析揭示了生物序列中隐藏的特异性
官网:http://kplogo.wi.mit.edu/submit.html?
当存在于大分子内的关键位置时,只有 1-4 个字母的基序可以发挥重要作用。由于现有的模体发现工具通常会遗漏这些特定位置的短模体,我们开发了k pLogo,这是一种基于概率的标志工具,用于从一组对齐序列中集成检测和可视化特定位置的超短模体。k pLogo 还克服了传统基序可视化工具在处理位置相关性和利用高通量分析中越来越多的排序或加权序列方面的局限性
一、简介
- 现有的motif-visualization工具,如WebLogo( 1 )、iceLogo( 2 )和pLogo( 3 ),通常以一组对齐的序列作为输入,计算每个字母在每个位置的权重(频率或统计显着性),并生成徽标图,其中字母高度相对于其权重进行缩放
- 由于每个位置都是单独考虑的,这些工具无法对多个位置之间的相互依赖性进行建模和可视化,因此无法解析相互重叠的主题
- 此外,这些工具平等地对待每个输入序列,因此不支持加权或排序的序列,这些序列越来越多地从高通量研究中获得,例如体外选择(4) 和大规模平行报告基因检测 ( 5 )。
k pLogo 将主题发现与可视化相结合。与其他生成序列标志的工具相比,k pLogo 在几个方面是独一无二的:
- 处理排序或加权序列
- 执行统计测试以发现短基序
- 不仅可视化单个字母,还使用k- mer 标志可视化短基序
- 在一次运行中绘制频率标志、信息内容标志、概率标志和k聚体标志
- 允许简并字母 (DNA/RNA) 和缺口图案
- 可以使用色盲友好颜色生成标志
二、算法
k pLogo 扩展了 pLogo(概率标志)的框架,它在两个方面缩放每个基序残基的高度以显示其富集的统计显着性 ( 3 )。
- 首先,为了支持排序和加权序列,k pLogo 分别使用 Mann-Whitney U检验和 Student t检验计算检验统计量及其相应的P值。
- 其次,除了在每个位置测试单个字母的统计显着性之外,k pLogo 还测试了从每个位置开始的所有短k聚体(默认k ≤ 4,允许退化字母)。为了可视化结果,kpLogo 生成一种称为k- mer 徽标的新型徽标图,其中在每个位置垂直绘制最重要的k- mer,并将总高度缩放为其P值(–log 10转换)或测试统计量,视情况而定.
虽然主要设计用于 DNA/RNA 序列分析,但k pLogo 也适用于蛋白质序列分析。
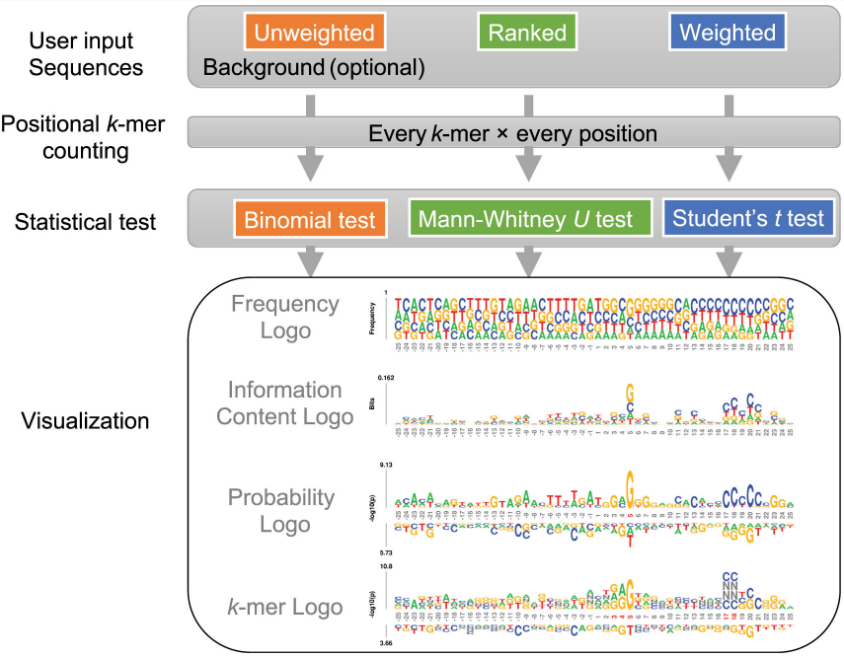
三、输出
3.1 频率标志 Frequency logo
在频率标识中,残基相对于它们在每个位置的频率进行缩放,然后彼此堆叠,频率更高的残基位于频率较低的残基之上。
3.2 信息内容标志 Information-content logo
与频率标志类似,在一个信息内容标志(常规序列标志,(conventional sequence logo)中,残基按频率缩放并堆叠,每个位置的总高度相对于信息内容进一步缩放,定义为
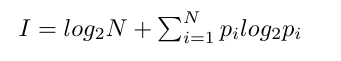
这里 N 是字母表中的残基数(在某个位置可能出现的所有可能的残基),pi 是该位置的残基 i 的频率。
3.3 概率标志 Probability logo
概率标识首先在 pLogo 中被提出并实现,用于未加权的序列,尤其是蛋白质序列。 kpLogo 将概念扩展到排序和加权序列。 在概率标志中,残基相对于每个位置的每个残基的统计显着性(-log10(P 值))进行缩放。 富集的残留物堆积在顶部,而耗尽的残留物堆积在底部。 重要位置的坐标为红色。
3.4 kmer logo
类似plogo,兼顾kmer信息
参考资料
- kpLogo: positional k-mer analysis reveals hidden specificity in biological sequences。 https://academic.oup.com/nar/article/45/W1/W534/3782598
- http://kplogo.wi.mit.edu/manual.html?#install-kpLogo-locally
这里是一个广告位,,感兴趣的都可以发邮件聊聊:tiehan@sina.cn
![]() 个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
