【1.1】k-mer基于de Bruijin graphs算法的序列组装
基因测序起始于1977年,Walter Gilbert 和Frederick Sanger发明第一台测序仪。1980年为此获得诺贝尔奖.。人们对测序就趋之若鹜。而随着2005年高通量测序的诞生,对序列的组装也提出了更高的要求。
基因就像一本天书,里面的字都是有A,T,C,G组成的。我们测序出来的大于几百bp的小的序列,我们叫做reads。我们测序的结果中有上百万条的reads,而这些reads的位置我们又不知道,我们只能根据他们重叠的部分来尽量还原他的原型。
**k-mer是指将reads分成包含k个碱基的字符串,一般长短为m的reads可以分成m-k+1个k-mers。**举个例子吧:为了简化,有这么个reads(当然实际比这个长):AACTGACTGA.如果k-mer的k为3的话,我们可以将其切割为AAC ACT CTG TGA GAC ACT CTG TGA。我们将这些k-mers放入计算机中拼接,假设第一个为TGA ,那么下一个应该为GA-,.……
TGA
GAC
ACT
CTG
TG ????
基于这样的思路,我们很快就发现了问题,下一个点可能有很多的选择,或者没有选择
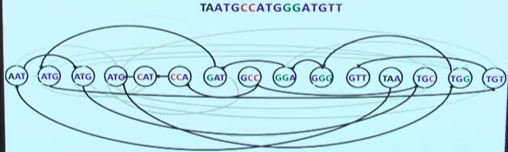
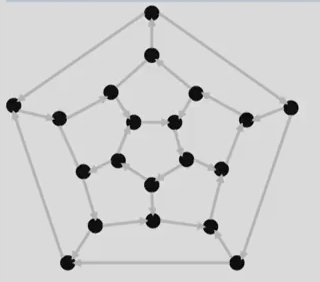
这是俄国一个我一个伟大的科学家William Hamilton的一个发明。
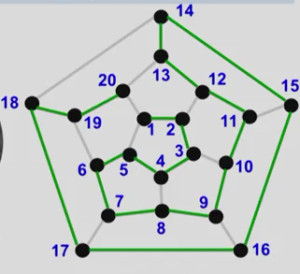
但是又提出了一个假设,如果有两条或多条的Hamiltonian path呢?如何才能知道其中的一条是DNA的序列呢
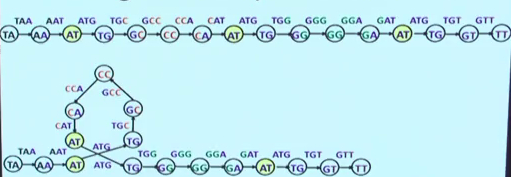
我们上面提到的是3个碱基为一个node,现在我们就只要其中的2个来作图,然后将作出的图中相同的node合并,
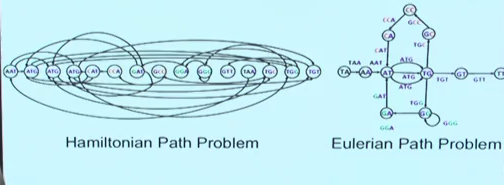
这是两种算法思想,在Eulerian Path Problem中,visit every edge of the graph exactly once.
而在Hamiltonian Path Problem,visit every node exactly once.第一种算法更好实现,所以我们接下来讲关于Eulerian Path Problem的de Bruijin graphs。
在实际组装基因的时候,我们知道的是reads和k-mers,通过这个我们来基于Eulerian Path Problem来构建de Bruijin graphs,然后找Eulerian Path。可是会有很多的de Bruijin graphs,或者一个de Bruijin graphs有几个Eulerian Path。为了减少contigs,发明了read pair sequencing
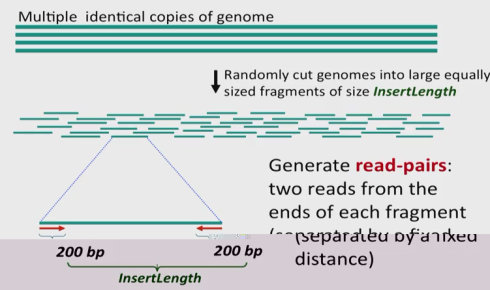
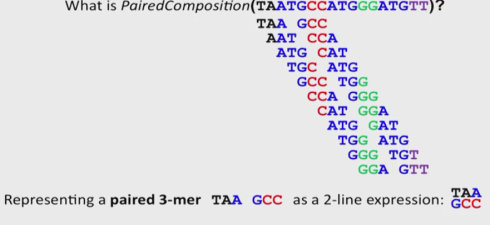
把很多拷贝的相同基因,尺寸随意剪切为大的相同大小InsertLength片段。产生read-pairs:两个reads来自每个片段的末尾。A paired k-mer就是两个k-mer距离相隔d,
根据我的实际使用经验,如果你的read足够长,覆盖度足够高,kmer设的越高越好。 但是实际情况是,测序的覆盖度经常不够,或者用早期的GA平台测出来read长度只有35bp,或者为了节省成本,在mate-pair library(长片段insert的文库,一般>2kb)测序时双端只有70bp,甚至40bp之类的,情况比较复杂。
一般来说,我尽量使用更高的kmer,如果我有100bp的pair-end,50bp的mate-pair,而且覆盖度挺高,我就用到kmer=45左右,如果mate-pair只有40bp,kmer=35左右。如果mate-pair更短,只有35bp,kmer值就再降一点。
一、k-mer
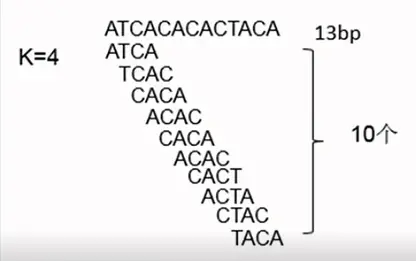
那么我们首先要看一下k-mer是什么。 它的定义是:是指将一条序列分成包含k个碱基的子字符串,如果reads长度为L,k-mer长度设为k,则产生的k-mers数目为:L-k+1,例如序列AACTGACT,设置k为3,则可以将其分割为AAC ACT CTG TGA GAC ACT共6个k-mers。其中k一定是奇数,如果是偶数遇到回文序列可能会产生完全相同的k-mers。
二、与k-mer相关的公式及意义
其中
k-mer(number)= Read_length - k-mer_size + 1
如果假设基因组大小为G,由于测序是随机的,read长度为L,n(base)和n(kmer)分别为测序的碱基和kmer个数,C(base)和C(kmer)分别为碱基和kmer的覆盖深度 那么有:
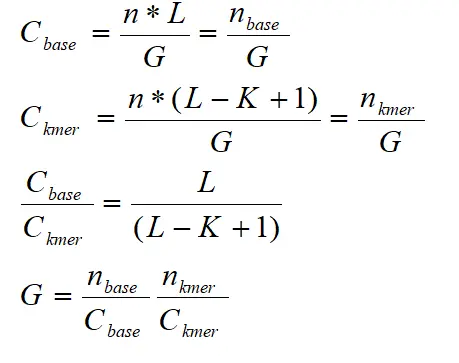
一般来说,k-mer的深度比碱基深度要低一些
三、k-mer杂合度
对于杂合基因组,来说k-mer可分为杂合k-mer和纯合k-mer,其中k为k-mer的个数,那么对有些位点来说,有2k个杂合k-mer覆盖,如图红色部分:

以此,我们定义α1/2为杂合k-mer种类数的百分比,n(kspecies)为所有k-mer种类数,那么杂合度计算如下:

4.k-mer分析常用软件
k-mer分析的常用软件有Jellyfish,GCE,GenomeScope 这样我们就可以看到一些kmer的分布,基因组大小和重复序列等一些指标
参考资料
