【9.3.5.1】CWL入门--介绍
Questions :
- What are computational workflows, and why are they useful?
- What is Common Workflow Language?
- How are CWL workflows written?
- How do CWL workflows compare to shell workflows?
- What are the advantages of using CWL workflows?
Objectives:
- Recognise the advantages of using a computational workflow
- Understand why you might use CWL instead of a shell script
一、计算工作流
计算工作流是一个形式化的软件工具链,它明确定义了数据如何输入、数据如何在工具之间流动以及数据如何输出。计算工作流被广泛用于数据分析,并实现快速创新和决策。
计算工作流最重要的好处是,它们需要用户写下、完全形式化并自动化其数据流和过程。虽然这可能是一个挑战,但它可以实现更大的可重复性、可共享性和健壮性。
下图显示了虚拟工作流的图形表示。您可以看到左侧的输入,数据流动,由工具处理并传递到输出。
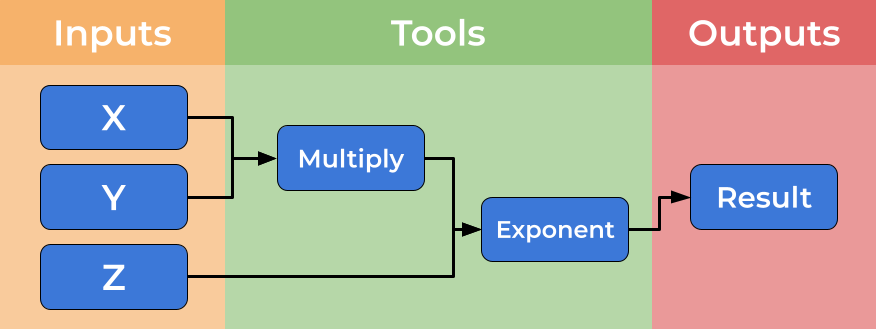
虽然您可以想象创建shell脚本(Bash或Make)来满足这一需求,但使用正式的工作流语言(如CWL)会带来一些进一步的好处,如引入抽象、提高可扩展性和可移植性。我们将在这里讨论其中的一些好处。
计算工作流明确地在用户的数据流和支撑工具链的计算细节之间创建了一个鸿沟,将这些元素放置在单独的文件中。数据流是由工作流描述的,其中工具是在高级别上描述的。工具实现由工具描述符指定,其中处理了工具使用的全部复杂性。下图显示了工具描述符如何支撑工作流步骤并隐藏复杂性。
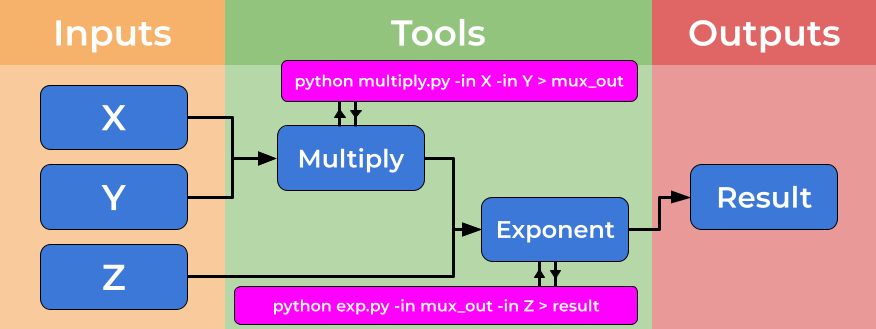
这种抽象允许使用可能由第三方共享的异构工具,并允许工作流用户连接和使用广泛的工具和技术,而不需要大量的计算经验。这种方法优势的一个例子是,工作流能够“在引擎盖下”使用(例如Docker)容器,而无需用户安装、下载或学习任何进一步的技术。
通过使工具描述符适应多个平台,这种抽象允许在不同的平台上使用相同的工作流,对工作流用户透明。这意味着用户可以在本地开发与云和HPC解决方案之间无缝切换。
计算工作流管理器进一步扩展了这种抽象,提供了用于管理数据和工具的高级工具,旨在帮助用户更轻松地设计和运行计算工作流。计算工作流引擎为启动工作流、指定和处理输入以及收集和导出输出提供了一个接口,它们还可以通过存储工作流的已完成步骤来帮助用户,允许工作流在中途恢复,或以最小的更改重新运行。
此外,计算工作流管理器帮助用户实现数据流的自动化、监控和来源跟踪。它们还可以帮助用户生成和理解工作流程中的报告和输出。
工作流的另一个优点是,通过以标准格式生成计算工作流,并以开放访问的方式发布它们(与任何数据一起发布),允许以更FAIR(可查找、可访问、可互操作和可重用)的方式共享数据流。
然而,随着工作流的普及,可用的不同工作流管理器的数量也在增加,每个管理器都有自己的语法或方法来描述工具和工作流,从而降低了这些工作流的可移植性和互操作性。通用工作流语言(CWL)标准已被开发来解决这些问题,并满足上述一般计算工作流的需求。
总之,计算工作流带来了许多好处,理想的计算工作流采用并提供了以下特性:
Handy Properties of Computational Workflows:
Composition & Abstraction
- Using the best code written by 3rd parties
- Handle heterogeneity
- Shield Complexity & incompatibility
- Shareable reusable, re-mixable methods
Sharing & Adaptability
- Shared method, publishable know-how
- BYOD / parameters
- Different implementations
- Changes in execution infrastructure
Automation
- Repetitive reproducible pipelines
- Simulation sweeps
- Manage data and control flow
- Optimised monitoring & recovery
- Automated deployment
Reporting & Accreditation
- Provenance logging & data lineage
- Auto-documentation
- Result comparison
Scalability & Infrastructure Access
- Accessing infrastructures, datasets and tools
- Optimised computation and data handling
- Parallelisation
- Secure sensitive data access & management
- Interoperating datasets & permission handling
Portability
- Dependency handling
- Containerisation & packaging
- Moving between on premise & cloud
二、通用工作流语言
CWL是一个自由开放的标准,用于描述基于命令行工具的工作流。这些标准提供了一组通用但精简的抽象,既可在实践中使用,也可在许多流行的工作流管理器中实现。CWL语言是声明性的,使计算工作流能够从不同的软件工具中构建,并通过命令行界面执行每个工具。
以前的研究人员可能会编写shell脚本来将这些命令行工具链接在一起。尽管这些脚本可能提供了访问工具的直接方法,但编写和维护它们需要对将要使用的系统有特定的了解。Shell脚本不容易移植,因此研究人员很容易花更多的时间来维护脚本,而不是进行研究。CWL的目的是减少研究人员使用这些工具的障碍。
CWL工作流是在YAML的一个子集中编写的,其语法不限制为工具或工作流提供的细节量。执行模型是显式的,工具运行时环境的所有必需元素都必须由CWL工具描述作者指定。除了这些基本需求之外,他们还可以在工具描述中添加提示或需求,帮助指导用户(和工作流引擎)了解工具需要什么资源。
CWL标准明确支持使用软件容器技术,有助于确保工具的执行是可复制的。数据位置是明确定义的,每个工具调用的工作目录都是分开的。这些标准确保了工具和工作流的可移植性,允许相同的工作流在本地计算机上或HPC或云环境中运行,只需最少的更改。
三、RNA测序示例
在本教程中,以生物信息学RNA测序分析为例。然而,本教程并不需要具体的知识。RNA测序是一种使用下一代测序来检测样本中RNA的数量和序列的技术。对RNA读数进行分析,以测量样品中不同RNA分子的相对数量。这种分析是差异基因表达。
过程如下所示:
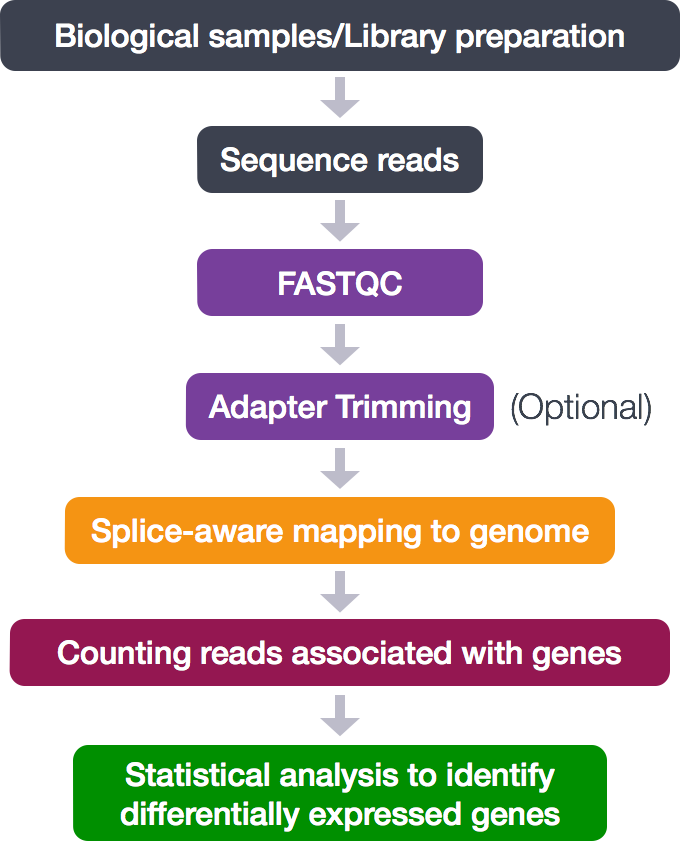
在本教程中,将只执行中间的分析步骤。适配器修剪被跳过。将执行以下步骤:
- 质量控制(FASTQC)
- 对齐(映射)
- 计数与基因相关的读数
该分析所需的不同工具已经可用。在本教程中,将设置一个工作流来连接这些工具并生成所需的输出文件。
参考资料
