【3.3.1】相似性-RDKit
1.相似性比较
分子指纹的应用之一就是比较分子间相似性。
相似度比较:DataStructs.FingerprintSimilarity(fp1, fp2, metric)
fp1, fp2:待比较的分子
metric:距离度量方法,默认为DataStructs.TanimotoSimilarity
>>> ms = [Chem.MolFromSmiles('CCOC'), Chem.MolFromSmiles('CCO')]
>>> fps = [Chem.RDKFingerprint(x) for x in ms]
>>> DataStructs.FingerprintSimilarity(mfp[0], mfp[1])
0.6
度量方法非常多,随便举几例:Tanimoto, Dice, Cosine, Sokal, Russel, Kulczynski, McConnaughey等,按需选择。
>>> metic_list = ['DataStructs.TanimotoSimilarity',
>>> 'DataStructs.DiceSimilarity',
>>> 'DataStructs.CosineSimilarity',
>>> 'DataStructs.SokalSimilarity',
>>> 'DataStructs.RusselSimilarity',
>>> 'DataStructs.KulczynskiSimilarity',
>>> 'DataStructs.McConnaugheySimilarity']
>>> for i in metic_list:
>>> print(DataStructs.FingerprintSimilarity(fps[0], fps[1], metric=eval(i)))
0.6
0.75
0.7745966692414834
0.42857142857142855
0.0029296875
0.8
0.6
以上方法也可以直接调用,以Tanimoto为例:DataStructs.TanimotoSimilarity(bv1, bv2)
bv1、bv2:两个分子指纹的bit vetor
>>> DataStructs.TanimotoSimilarity(fps[0], fps[1])
0.6
2.相似性地图
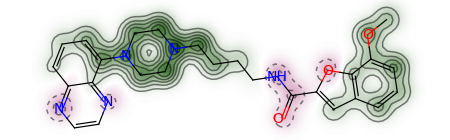
相似性地图是一种用来可视化分子中原子相似性程度的方法,具体可以参考rdkit中的rdkit.Chem.Draw.SimilarityMaps模块
先来初始化两个分
>>> mol = Chem.MolFromSmiles('COc1cccc2cc(C(=O)NCCCCN3CCN(c4cccc5nccnc54)CC3)oc21')
>>> refmol = Chem.MolFromSmiles('CCCN(CCCCN1CCN(c2ccccc2OC)CC1)Cc1ccc2ccccc2c1')
相似性地图模块支持三种分子指纹的比较和可视化:atom pairs、topological torsions和Morgan fingerprints。
使用atom pairs和topological torsions时,fpType可选值有:normal(默认值)、hashed、bit vector(bv)。 使用morgan指纹时,fpType可选值为:bv(默认值)和count(count vector) 该模块内的分子指纹方法也可以通过AllChem直接调用
>>> from rdkit.Chem.Draw import SimilarityMaps
>>> fp = SimilarityMaps.GetAPFingerprint(mol, fpType='normal')
>>> fp1 = AllChem.GetAtomPairFingerprint(mol)
>>> print(fp == fp1)
True
>>> fp = SimilarityMaps.GetTTFingerprint(mol, fpType='normal')
>>> fp1 = AllChem.GetTopologicalTorsionFingerprint(mol)
>>> print(fp == fp1)
True
>>> fp = SimilarityMaps.GetMorganFingerprint(mol, fpType='bv')
>>> fp1 = AllChem.GetMorganFingerprintAsBitVect(mol, 2)
>>> print(fp == fp1)
True
生成相似性地图:GetSimilarityMapForFingerprint(refMol, probeMol, fpFunction, metric, …) refMol:参照分子 probeMol:探针分子 fpFunction:指定所用的分子指纹方法 metric:相似性度量方法(默认为DataStructs.DiceSimilarity)
>>> fig, maxweight = SimilarityMaps.GetSimilarityMapForFingerprint(refmol, mol, SimilarityMaps.GetMorganFingerprint)
3.相似性应用——构建多样化分子库
有时会遇到这种任务,需要从整个分子库中,挑出一个子集,使子集的多样性最高,或者能最大程度地代表原始分子库的化学空间。Rdkit在rdkit.SimDivFilters模块中提供了一系列的方法用来处理这种需求,最有效的是MaxMin算法,有文章报道该方法优于k-means。使用MaxMin算法从N个分子的库中挑选k个分子作为子集的大致流程如下:
- 选择一个种子化合物用于初始化子集,并设置x=1。
- 遍历分子库中剩余的N-x个分子,计算它与子集x中每个分子的相异性(可以认为是“1-相似度”),并取x个相异性值中最小的一个作为最终相异值(该值反应了库中分子与子集中最相似分子的相异性)。
- 选择分子库中最终相异值最大的化合物(MaxMin名称的由来),将其加入到子集中,并更新x += 1,重复步骤2,直到x==k。
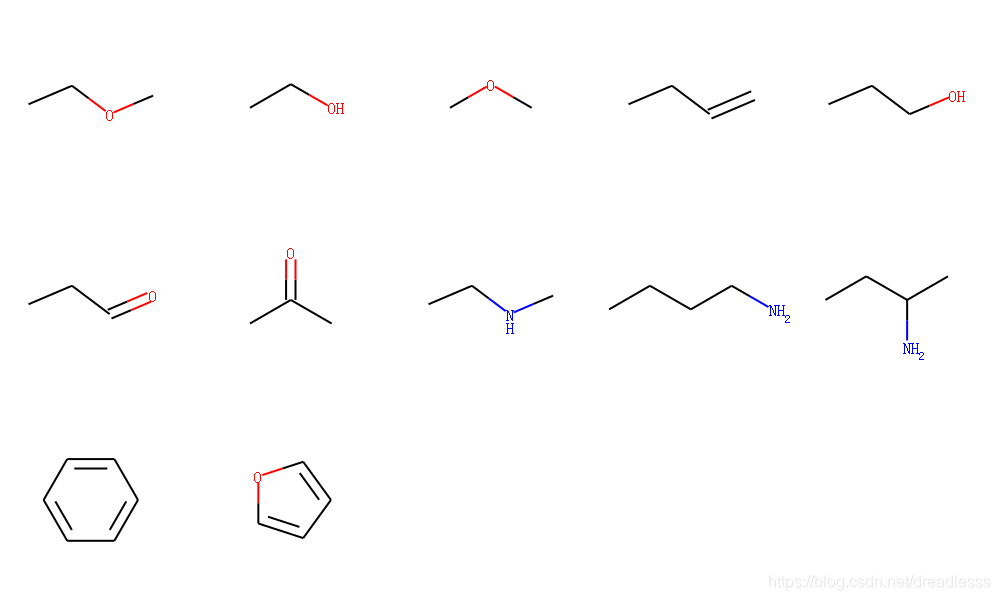
示例:
>>> from rdkit.SimDivFilters.rdSimDivPickers import >>> >>> MaxMinPicker
>>> ms = [Chem.MolFromSmiles('CCOC'),
>>> Chem.MolFromSmiles('CCO'),
>>> Chem.MolFromSmiles('COC'),
>>> Chem.MolFromSmiles('CCC=C'),
>>> Chem.MolFromSmiles('CCCO'),
>>> Chem.MolFromSmiles('CCC=O'),
>>> Chem.MolFromSmiles('CC(=O)C'),
>>> Chem.MolFromSmiles('CCNC'),
>>> Chem.MolFromSmiles('CCCCN'),
>>> Chem.MolFromSmiles('CCC(N)C'),
>>> Chem.MolFromSmiles('c1ccccc1'),
>>> Chem.MolFromSmiles('c1cocc1'),]
>>> fps = [AllChem.GetMorganFingerprint(x, 2) for x in ms]
>>> Draw.MolsToGridImage(ms, molsPerRow=5)
该算法需要先定义一种相异性度量方法,用于比较分子间的距离,以DiceSimilarity为例
>>> def distij(i, j, fps=fps):
>>> return 1-DataStructs.TanimotoSimilarity(fps[i],fps[j])
再创建一个picker对象:MaxMinPicker() 挑选分子:picker.LazyPick(distFunc, poolSize, pickSize, firstPicks, seed, …) distFunc:相异性度量函数,该函数可以接收两个索引,并返回相应的距离。 poolSize:总分子数量 pickSize:要挑出的分子数量 firstPicks:第一个初始化的分子 seed:随机种子
>>> picker = MaxMinPicker()
>>> pickIndices = picker.LazyPick(distij, len(ms), 4, seed=1)
>>> picks = [ms[x] for x in pickIndices]
>>> Draw.MolsToGridImage(picks, molsPerRow=4)
顺便介绍下k-means基于聚类构建多样性分子库的方法,大致流程如下:
- 初始化k个类别的代表(k为用户提供),并计算类的质心centroids
- 遍历分子库中的每个分子,计算该分子与各个类的代表间的距离,并划分到距离最近的类中
- 更新各个类别的代表,如果类别没有收敛,则重复步骤2
- 从分好的各个类别中,选取若干分子组成最终的子集。
参考资料
