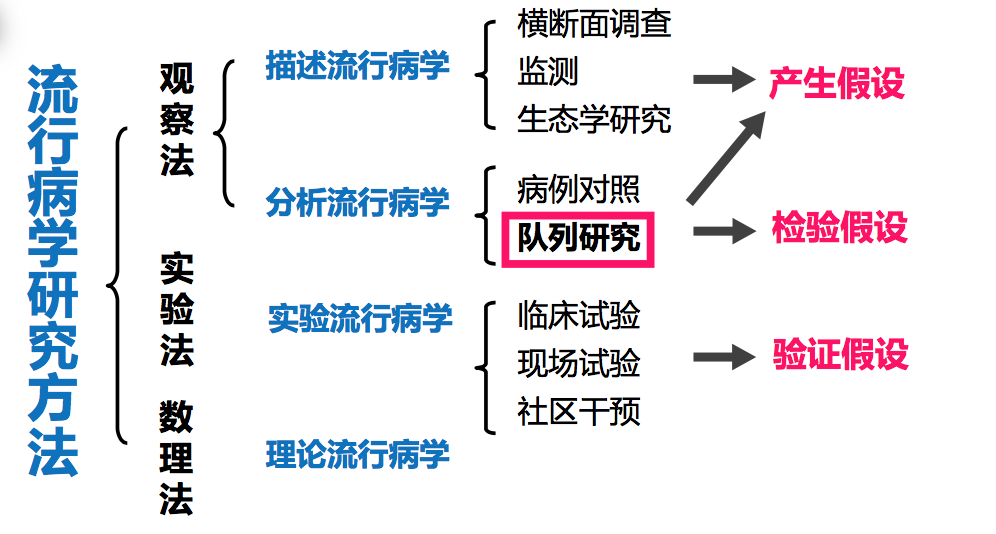
【4】队列研究
内容提要:
- 什么是队列?什么是队列研究?
- 为什么开展队列研究?
- 如何开展一项队列研究?
- 如何分析与评价队列研究的结果?
- 队列研究设计与实施中应注意的问题
- 归纳与总结
一、什么是队列?什么是队列研究?

多尔 (Richard Doll) 和希尔 (Austin Bradford Hill) 于1951-1976 开展研究

队列 (cohort):具有共同特征的一群人。 如吸烟、饮茶、素食、出生年代等。
队列研究 (cohort study):追踪随访队列人群,探讨因素与疾 病发生之间的关系。
二、为什么开展队列研究?
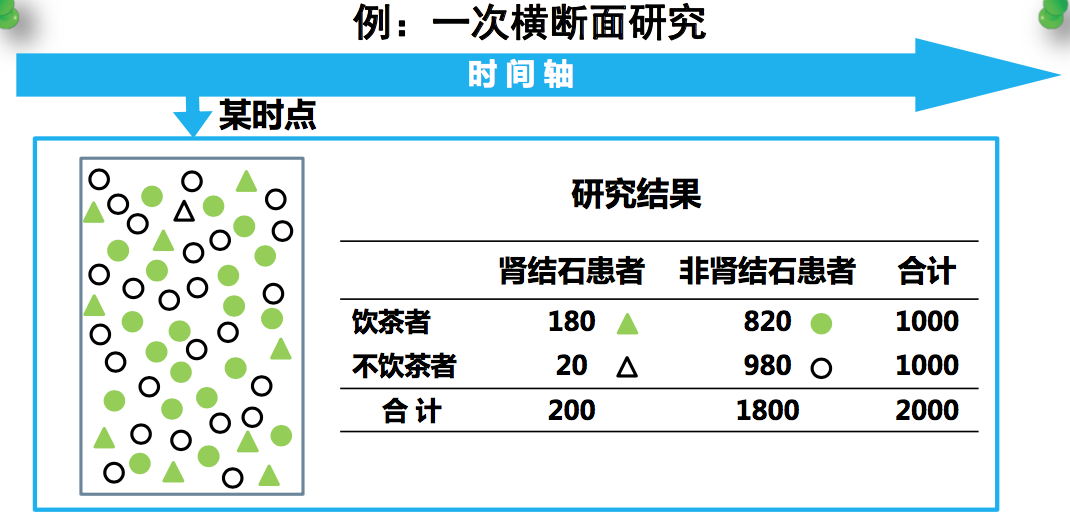
饮茶是不是跟肾结石有真正的因果关系?
在疾病还没发生的时候,将人群分为两组:
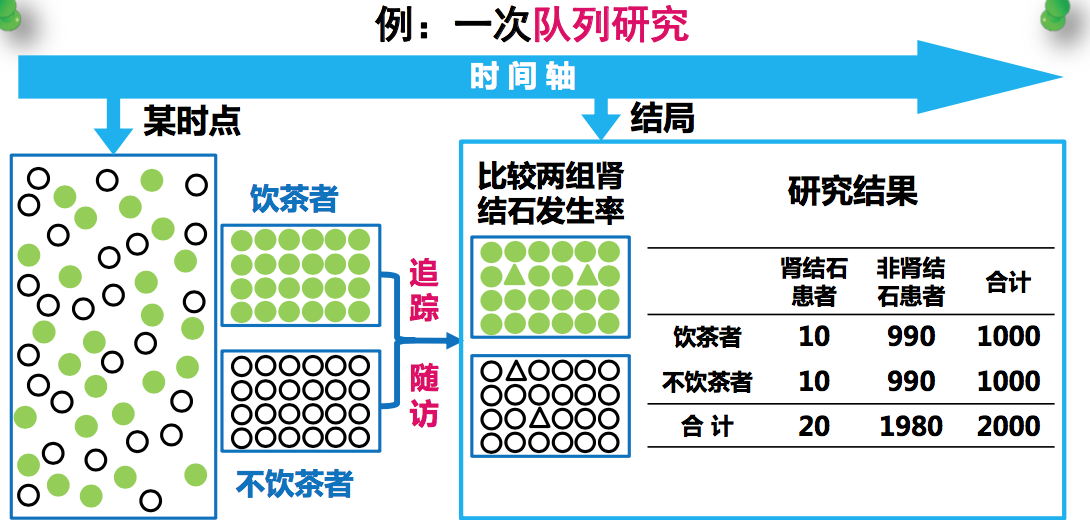
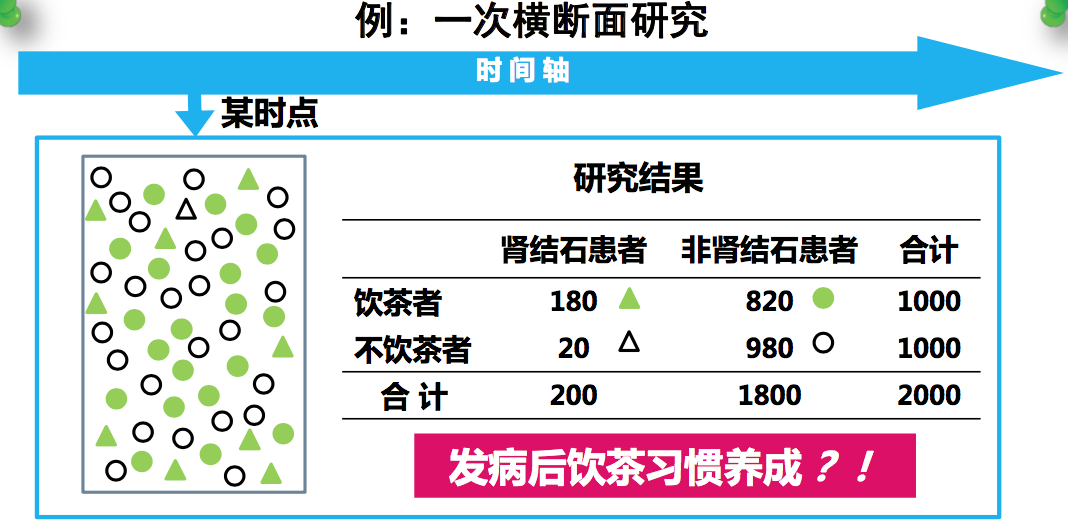
发病后饮茶习惯养成!
易于判断暴露因素与结局出现的先后顺序
- 横断面研究难以确认因素与疾病之间的时序关系 公共卫生学院
- 队列研究是由因到果的研究
- 队列研究更科学合理,适用于探索和检验病因假设
队列研究的基本原理:
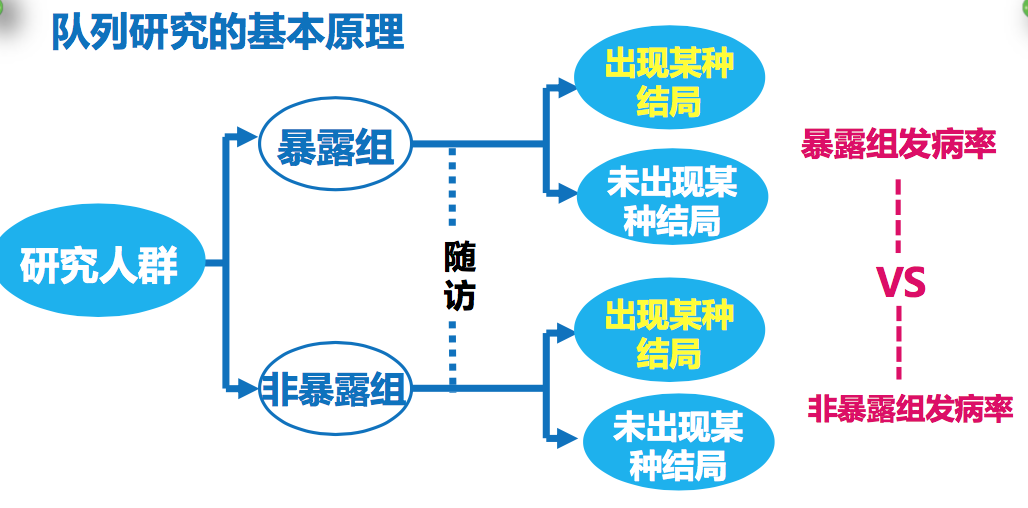
例:职业接触C𝑺𝟐 与冠心病关系的研究

队列研究的三种类型:


三、如何开展一项队列研究?
3.1 明确研究目的,确定暴露与结局
- 暴露(exposure)
- 结局(outcome) 主要结局、次要结局
定义及测量
3.2 研究地区及人群的选择:
- 可操作性好
- 研究开始时没有出现结局
- 在随访期内有可能出现研究结局
- 暴露及发病水平不能太低

样本量的确定:
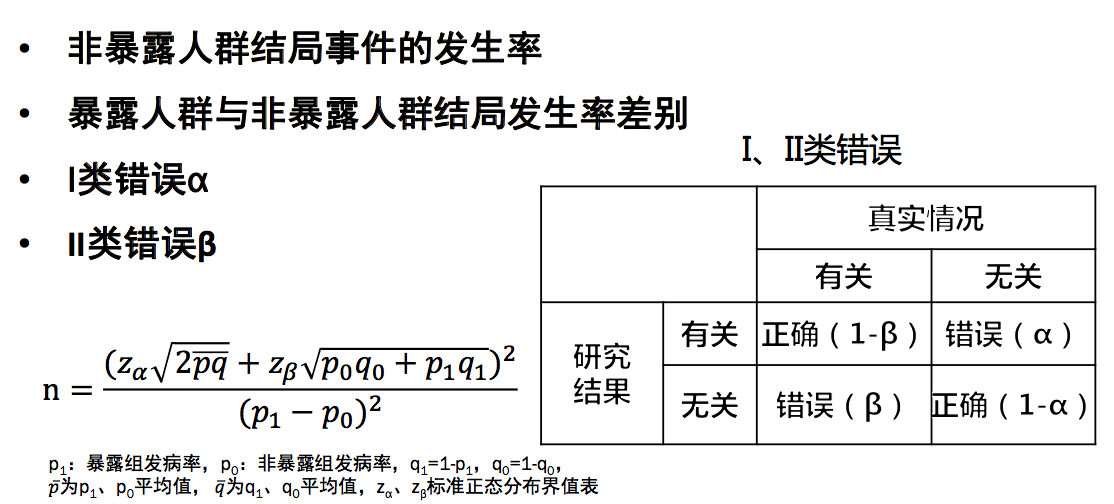

3.3 随访 (follow up) 科学计划、严格实施
- 随访方法:两组方法一致
- 随访内容:暴露,结局?
- 随访间隔:依疾病特点及可行性而定
- 研究对象观察终点:出现预期结局
- 研究终止时间:主要以潜隐期为依据
3.4 资料的整理与分析
队列研究结果整理
| - | 发生结局 | 未发生结局 | 合计 |
|---|---|---|---|
| 暴露组 | a | b | N1 |
| 非暴露组 | c | d | N2 |
| 合计 | a+c | b+d | N |
发病率:
Ie=a/N1
I =c/N2
四、队列研究结果的分析与评价
例1:发病率的计算
某队列起始观察为1000人,随访三年,每年随访一次, 三年发病30人。
发病率 = 30/1000 = 3%
累积发病率(cumulative incidence, CI): 观察人口比较稳定时,不论观察时间长短,以开始观察时 的人口数为分母,整个观察期内发病人数为分子。
失访 (loss to follow-up):
在随访过程中,某些选定的研究对象因为种种原因脱离了观察,研究者无法继续随访他们。
失访原因: 迁移、外出、不愿合作而退出、死于非终点疾病。
- 当观察的人口不稳定,观察对象进入研究的时间先后不一,以及各种原因造成失访,每个观察对象随访的时间不同,若用总人数为单位计算率是不合理的。
- 此时可用人时(person-time)为单位计算率,即以观 察人数乘以观察时间。用人时为单位计算的率称为发病密 度(incidence density, ID)。
- 时间单位可用年、月、日、时等,但最常用的是年, 即以人年(person-year)为单位计算发病率或死亡率。
例2:发病率的计算(有失访)
某队列起始观察为1000人,随访三年,每年随 访一次,三年发病30人。第1年失访80人,第2年失访70人,第3年失访 50人,共失访200人
方法1:忽略失访
发病密度 = 𝟑𝟎/(1000*3年) = 𝟏𝟎.𝟎/千人年
方法2:剔除失访对象
发病密度 = 𝟑𝟎/(800*3年) = 𝟏𝟐. 𝟓/千人年
方法3:考虑具体失访情况
发病密度 = 𝟑𝟎/2670人年 = 𝟏𝟏.2/千人年

为什么有除以2呢?–假设人是在年中的时候走掉了,认为这批人被随访了一半的时间,所以除以2。这么搞,靠谱不?
第3种方法更为合理:考虑具体失访情况,充分利用观察资料
比较两组结局发生率
暴露组发病率或发病密度 Ie、非暴露组发病率或发病密度 Io
统计学检验:U检验、卡方检验
判断实际人群中两组率是否有差别
相对危险度(risk ratio, RR) RR = Ie/Io
归因危险度百分比(AR%, 又称病因分值EF) AR% = (I𝒆−Io)/I𝒆
归因危险度(attributable risk, AR) AR = I𝒆 − Io
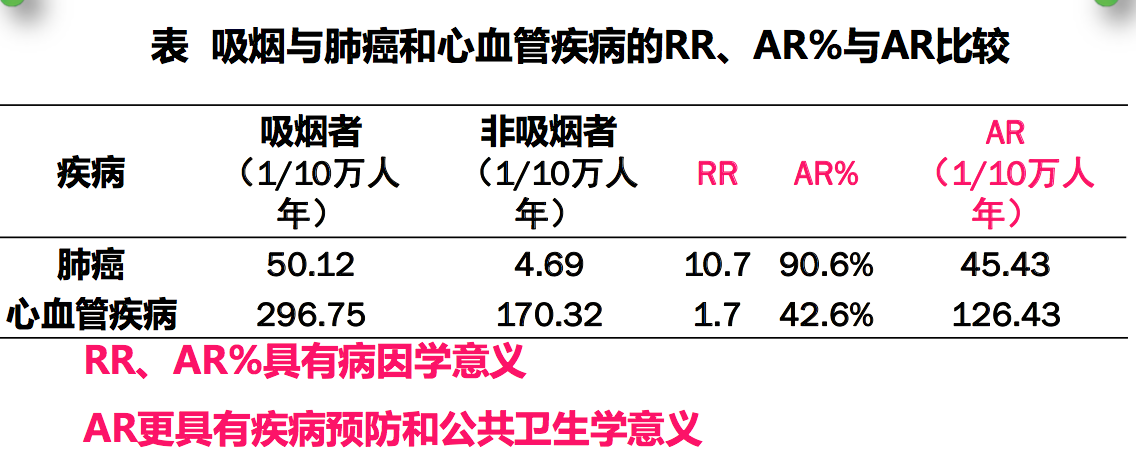
例,吸烟和肺癌研究结果:
吸烟组肺癌死亡率 Ie=0.90/千人年,不吸烟组肺癌死亡率 Io=0.07/千人年
相对危险度 RR = I𝒆/Io = 𝟎.𝟗𝟎/ 𝟎.𝟎𝟕= 𝟏𝟐. 𝟗
RR解释:暴露组发病或死亡的危险是对照组的多少倍
吸烟组因肺癌死亡的危险是对照组的12.9倍
- RR=1 两组的发病率或死亡率没有差别
- RR>1 暴露组的发病率或死亡率高于非暴露组, 暴露因素为危险因素
- RR<1 暴露组的发病率或死亡率低于非暴露组, 暴露因素为保护因素
归因危险度百分比 AR% = (I𝒆−Io)/I𝒆 = (𝟎.𝟗𝟎−𝟎.𝟎𝟕)/𝟎.𝟗𝟎 = 𝟗𝟐. 𝟐%
解释:暴露组的发病或死亡归因于暴露的部分占全部发病或死亡的百分比
吸烟组的肺癌死亡有92.2%归因于吸烟
归因危险度 AR = I𝒆−Io= 𝟎.𝟗𝟎/千人年 − 𝟎.𝟎𝟕/千人年 = 𝟎.𝟖𝟑/千人年 𝒆𝟎
解释:暴露组人群与非暴露人群比较,所增加的疾病发生数量
如果暴露因素消除,就可减少这个数量的疾病发生更具有疾病预防和意义
队列研究结果在人群中的延伸指标
一般人群发病率 It、非暴露组发病率 Io
人群归因危险度百分比(PAR%,又叫人群病因分值PEF)
PAR% = (I𝒕−I𝟎)/I𝒕
人群归因危险度(population attributable risk,PAR) 𝐏AR =I𝒕−I𝟎
- PAR%:人群中某病可归于某暴露因素的病例占该病全部病例的比例
- PAR:如消除暴露后,人群中发病率或死亡率可能降低的程度
例,吸烟和肺癌研究结果:
人群肺癌死亡率 It=0.81/千人年,不吸烟组肺癌死亡率 Io=0.07/千人年
人群归因危险度百分比 𝐏AR% = (𝑰𝒕−𝑰𝟎)/𝑰𝒕 = (𝟎.𝟖𝟏−𝟎.𝟎𝟕)/𝟎.𝟖𝟏 = 𝟗𝟏.𝟒%
人群归因危险度 𝐏AR = 𝑰𝒕 − 𝑰𝟎 = 𝟎.𝟖𝟏/千人年 − 𝟎.𝟎𝟕/千人年 = 𝟎.𝟕𝟒/千人年
五、队列研究设计与实施中应注意的问题
5.1 研究对象选择
- 研究暴露明确
- 保证足够样本量,控制失访率
- 暴露组与非暴露组人群间可比
- 研究人群具有代表性
选择研究对象时应:
- 严格按规定的标准选择研究对象;
- 查明愿意加入和不愿意加入研究的两组人的差异;
- 尽可能提高研究对象的依从性;
- 预估失访率,扩大样本量。
5.2 暴露与结局的测量
尽量避免暴露、结局的错误分类
- 原因:使用的仪器不准确,检验技术不熟练,诊断标准定义不明确或掌握不当,询问技巧欠佳
- 错分种类: 随机错分、非随机错分
- 方法:做好质控、明确标准严格执行
5.3 资料的整理与分析
- 对于失访可能的影响应做细致的分析;
- 如果暴露队列与非暴露队列在一些因素上(如,性别、年龄构成等)不均衡,应采用分层分析的方法以予以控 制;
- 可在检验研究假设的同时,探索暴露因素与其它结局 的关系。
六、总结
队列研究的优点:
- 可直接获得发病率或死亡率,因而可以直接估计相 对危险度。
- 原因发生在前,结局发生在后,检验病因假说的能 力较强。
- 可了解疾病的自然史。
- 可以获得一种暴露与多种疾病结局的关系。
- 所收集的资料完整可靠,不存在回忆偏倚。
队列研究的缺点:
- 不太适于发病率很低的疾病的病因研究。
- 长时间的观察,导致失访难以避免。
- 研究费时间、费人力、花费高。
- 随着时间推移,未知因素的引入,可能影响研究结果。
- 研究的设计要求高,实施难度较大。
队列研究在病因探讨中具有重要的地位其基本原理并不复杂,但实际应用需考虑很多问题队列研究应用广泛,发展迅速
参考资料:
北京大学公共卫生学院 胡永华老师的 《流行病学绪论》 课件
