【4.3.2.3】量化预测结果--分类变量--准确率,召回和F-措施
其目标是实现组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内的相似性越大,组间差别越大,聚类效果就越好。既然聚类是把一个包含若干文档的文档集合分成若干类,像上图如果聚类算法应该把文档集合分成3类,而不是2类或者5类,这就设计到一个如何评价聚类结果的问题。
分类器的分类情形
假如我们用NaiveBayes算法训练出一个系统,可以用来识别邮件是否为垃圾,对于一封邮件的识别,有如下4种情况:
邮件为垃圾,系统正确识别为垃圾 邮件为垃圾,系统错误识别为非垃圾 邮件不是垃圾,系统正确识别为非垃圾 邮件不是垃圾,系统错误识别为垃圾 如上的4种情形,如果用一个2X2的表格概括起来,就是大名鼎鼎的Confusion Matrix:
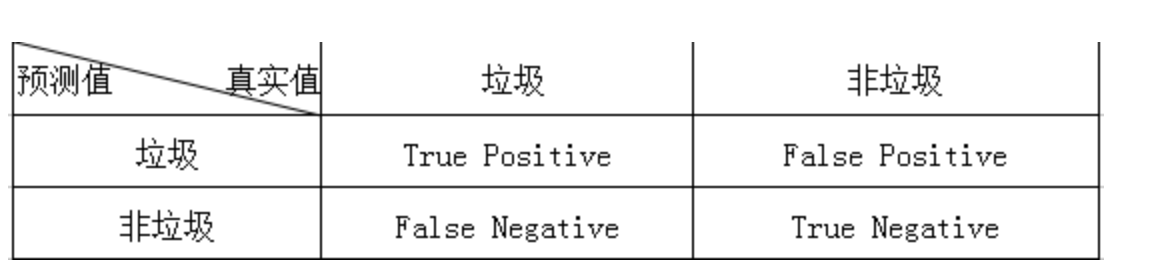
其中True和False是对于评价预测结果而言,也就是评价预测结果是正确的(True)还是错误的(False)。而Positive和Negative则是对分类器的预测结果而言,Positive为预测是垃圾,Negative是预测为非垃圾。为了表达方便,一般会以他们的缩写TP,FP,FN,TN代替。那么上面提到的邮件分类四种情形对应一下就变成如下:
- 邮件为垃圾,系统正确识别为垃圾(TP正确地预测为垃圾)
- 邮件不是垃圾,系统错误识别为垃圾(FP错误的预测为垃圾)
- 邮件不是垃圾,系统正确识别为非垃圾(TN正确地预测为非垃圾)
- 邮件为垃圾,系统错误识别为非垃圾(FN错误地预测为非垃圾)
一、灵敏度、特异性、精度、准确率
- 灵敏度(Sensitivity) : TP/(TP+FN)
- 也称为查全率(recall)
- 数据集共有13只爬行动物,其中10只被正确预测为爬行动物,灵敏度为10/13
- 特异度(Specificity): TN/(TN+FP)
- 数据集中有10只非爬行动物,其中8只被预测为非爬行动物,特异度为8/10
- 精度(Precision): TP/(TP+FP)
- 分类器预测了12只动物为爬行动物,其中10只确实是爬行动物,精度为10/12
- 准确率(Accuracy): (TP+TN)/(TP+TN+FN+FP)
- 数据集包含23只动物,其中18只预测为正确的分类,准确率为18/23
Accuracy为什么还不够?
上面的Confusion Matrix只是对于一封邮件而言,那么对于多封邮件的预测结果情形,TP,FP,FN,TN则是各种情形的计数结果,假如我们有100封测试邮件,其中50封为垃圾50封为非垃圾,就可能会预测出TP=40封,TN=40封,FP = 10封,FN = 10封。那么用Accuracy来衡量的话,就会得到:
$$ Accuracy = \frac{TP+TN}{TP+TN+FN+FP} = 0.8$$
感觉没多大问题。上面的情形是我们假设预测结果中垃圾邮件和非垃圾邮件是比较均匀的,也就是数量是差不多的。但是真实情形有可能是100封测试邮件中,垃圾邮件为90封,非垃圾邮件为10封,这种也就是常常说的skewed distribution。那么如果有一个trivial分类器,他永远只输出垃圾,那么TP=98,TN=0,FN=0,FP=2,此时假如还是用Accuracy来评价的话,我们可以得到:
$$ Accuracy = \frac{TP+TN}{TP+TN+FN+FP} = 0.98$$
,结果出乎意料地好,如果我们只是用Accuracy作为唯一的判断标准,那么这样trivial的分类器定当入选,这就是经常被提到的Accuracy Paradox现象。我们发现Accuracy并不能很好体现TN=FN=0这种异常现象,所以我们有必要寻求其他Metric来更好的刻画Confusion Matrix所表达的内容。
Precision-Recall
上一小节我们通过Accuracy Paradox说明Accuracy作为唯一指标的不足,还有Accuracy有时并不能很好地刻画Confusion Matrix所表达的内容。这一小节我们将了解信息检索领域中研究者如何对Confusion Matrix进行拆解,得到了Precision-Recall,从而对质和量得以把控,还有如何组合Precision-Recall得到一个对Confusion Matrix的一个统一解释数字。
对于信息检索问题,我们更关注搜索到的内容与用户想要搜索的内容是否相关。如果有测试数据的话,我们是希望搜索引擎返回的内容与用户要找的越相关越好,另一方面我们想让搜索引擎返回越多的相关内容越好,所以就有了Precision和Recall这两个指标。这两个指标中文翻译很多,但是很难有直观地翻译道明其中奥妙,所以这里也不尝试翻译,大家心领神会吧。但是Precision和Recall的侧重点是不一样的:
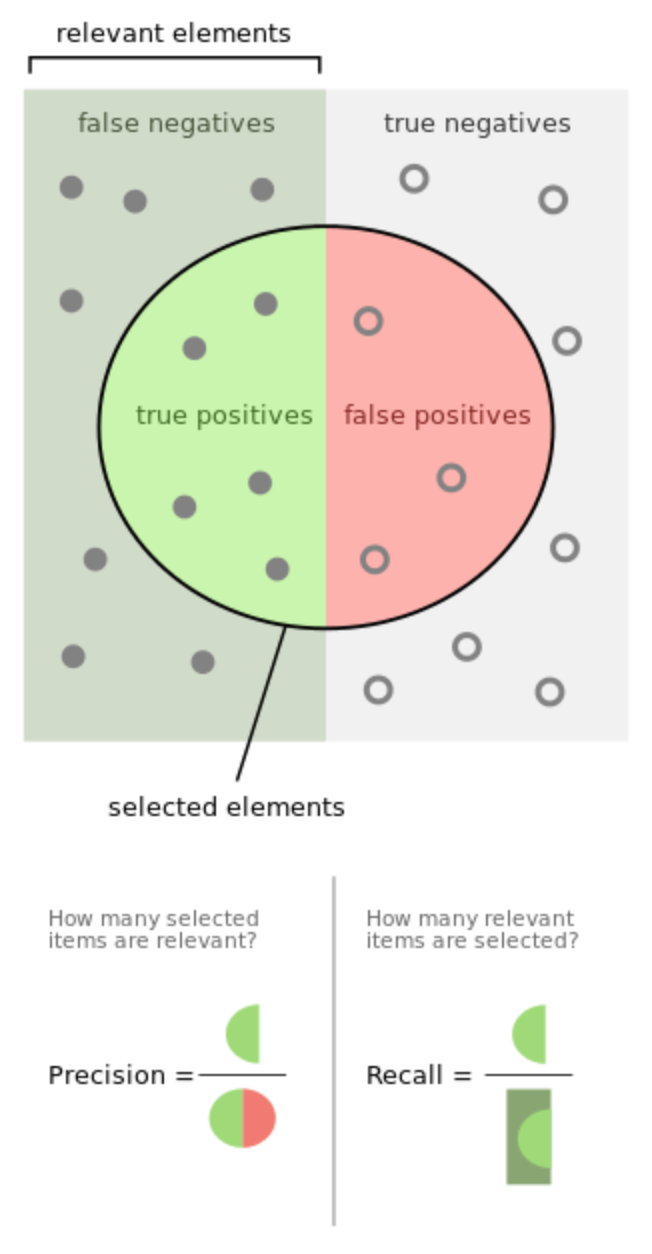
- Precision是返回的相关文献(TP)占总返回文献(TP+FP)的比例,所以Precision越大,返回的结果质量越高
- Recall是返回的相关文献(TP)占总相关文献(TP+FN)的比例,所以Recall越大,返回相关的文献就越多
一个是强调质量(返回结果只要给我相关的就好),一个是强调数量(返回相关的结果要尽可能越多越好)。按照上面的定义,我们根据Confusion Matrix可以给出Precision和Recall的数学形式:
$$ Precision = \frac{TP}{TP+FP} $$
$$ Recall = \frac{TP}{TP+FN} $$
对于生硬的数学形式,wiki上面有一幅插图很形象地表达了Precision和Recall的含义:
这两个指标哪个值高更好呢?在实际应用中,必须根据具体需求设定,举个例子,对于识别是否为超市会员和非会员的系统,我们当然希望Recall越高越好,虽然这样会混进一些非会员,但是对于超市来说并非损失,就给个折扣而已,还是赚钱。但是对于一个银行的门禁系统,肯定是要Precision越高越好,Recall可以不用那么严格,这样虽然会让你打卡打多几次,但是总比把一个外人放进来安全吧。所以根据实际业务需求,在Precision和Recall上做权衡是很有必要的。有的人说,我很懒,我不想自己手工做权衡,能不能综合Precision和Recall得到一个指标呢?答案是有的。
备注
对于非平衡的数据集,以上指标并不能很好的评估预测结果。 非平衡的数据集是指阳性数据在整个数据集中的比例很小。比如,数据集包含10只爬行动物,990只非爬行动物,此时,是否预测正确爬行动物对准确率影响不大。
二、F值评价法(F-Measure)
这是基于上述RI方法衍生出的一个方法,
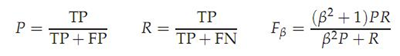
注:p是查全率,R是查准率,当β>1时查全率更有影响,当β<1时查准率更有影响,当β=1时退化为标准的F1,详细查阅机器学习P30
RI方法有个特点就是把准确率和召回率看得同等重要,事实上有时候我们可能需要某一特性更多一点,这时候就适合F值方法
对于想自动化权衡Precision和Recall的人,F Measure是他们的福音。首先介绍最简单也是最常用的合并Precision和Recall的方式——F1meaure或F1score,办法很简单,就像两个电阻并联求总电阻的形式相似,将Precision和Recall并联一下,就近似得到它们的加权平均:
$$ F1 = 2∗ \frac{Precision∗Recall}{Precision+Recall} $$
,这样的其实是均匀地加权平均,利用这个指标,我们回归到上面提到的Accuracy缺陷的例子,假如分类器一直输出为垃圾,对于有100封测试邮件其中垃圾为98封的测试集:TP=98,TN=0,FN=0,FP=2,那么
$$ Accuracy = \frac{TP+TN}{TP+TN+FN+FP} = 0.98$$
我们计算一下Precision和Recall,发现
$$ Precision = \frac{TP}{TP+FP} =0.98 $$
$$ Recall = \frac{TP}{TP+FN} = 1 $$
那么F1计算会得到:
$$ F1 = 2∗ \frac{Precision∗Recall}{Precision+Recall} = 2 * \frac{0.98*1}{1+0.98} = 0.989$$
。看来利用Precision-Recall或者是它们的组合F1都无法解决上面提到的skewed distribution问题(网上大量文章都是以Accuracy Paradox的问题引出Precision-Recall到F measure,让人以为F measure可以应对那种问题,其实不然)。但是我们通过拆分Confusion Matrix,再进行组合,可以使得我们更好得把握质和量,所以种种迹象都表面Precision-Recall和F measure比简单的Accuracy具有更细粒度的解释效果。
三、sklearn中的函数
几个功能可以让您分析准确度,召回率和F度量度:
| 函数 | 说明 |
|---|---|
| average_precision_score(y_true, y_score[, …]) | 从预测分数计算平均精度(AP) |
| f1_score(y_true, y_pred[, labels, …]) | 计算F1分数,也称为平衡F分数或F度量 |
| fbeta_score(y_true, y_pred, beta[, labels, …]) | 计算F-beta分数 |
| precision_recall_curve(y_true, probas_pred) | 计算不同概率阈值的精确回忆对 |
| precision_recall_fscore_support(y_true, y_pred) | 计算每个课程的精度,回忆,F度量和支持 |
| precision_score(y_true, y_pred[, labels, …]) | 计算精度 |
| recall_score(y_true, y_pred[, labels, …]) | 计算召回 |
请注意,该precision_recall_curve功能仅限于二进制的情况。该average_precision_score功能仅适用于二进制分类和多标签指示器格式。
二进制分类
以下是二进制分类中的一些小例子:
>>> from sklearn import metrics
>>> y_pred = [0, 1, 0, 0]
>>> y_true = [0, 1, 0, 1]
>>> metrics.precision_score(y_true, y_pred)
1.0
>>> metrics.recall_score(y_true, y_pred)
0.5
>>> metrics.f1_score(y_true, y_pred)
0.66...
>>> metrics.fbeta_score(y_true, y_pred, beta=0.5)
0.83...
>>> metrics.fbeta_score(y_true, y_pred, beta=1)
0.66...
>>> metrics.fbeta_score(y_true, y_pred, beta=2)
0.55...
>>> metrics.precision_recall_fscore_support(y_true, y_pred, beta=0.5)
(array([ 0.66..., 1. ]), array([ 1. , 0.5]), array([ 0.71..., 0.83...]), array([2, 2]...))
>>> import numpy as np
>>> from sklearn.metrics import precision_recall_curve
>>> from sklearn.metrics import average_precision_score
>>> y_true = np.array([0, 0, 1, 1])
>>> y_scores = np.array([0.1, 0.4, 0.35, 0.8])
>>> precision, recall, threshold = precision_recall_curve(y_true, y_scores)
>>> precision
array([ 0.66..., 0.5 , 1. , 1. ])
>>> recall
array([ 1. , 0.5, 0.5, 0. ])
>>> threshold
array([ 0.35, 0.4 , 0.8 ])
>>> average_precision_score(y_true, y_scores) # 对上吗的precision求的平均值
0.79...
多类和多标签分类
>>> from sklearn import metrics
>>> y_true = [0, 1, 2, 0, 1, 2]
>>> y_pred = [0, 2, 1, 0, 0, 1]
>>> metrics.precision_score(y_true, y_pred, average='macro')
0.22...
>>> metrics.recall_score(y_true, y_pred, average='micro')
...
0.33...
>>> metrics.f1_score(y_true, y_pred, average='weighted')
0.26...
>>> metrics.fbeta_score(y_true, y_pred, average='macro', beta=0.5)
0.23...
>>> metrics.precision_recall_fscore_support(y_true, y_pred, beta=0.5, average=None)
...
(array([ 0.66..., 0. , 0. ]), array([ 1., 0., 0.]), array([ 0.71..., 0. , 0. ]), array([2, 2, 2]...))
对于使用“负面类”的多类分类,可以排除一些标签:
>>>
>>> metrics.recall_score(y_true, y_pred, labels=[1, 2], average='micro')
... # excluding 0, no labels were correctly recalled
0.0
类似地,数据样本中不存在的标签可以在宏平均中考虑。
>>> metrics.precision_score(y_true, y_pred, labels=[0, 1, 2, 3], average='macro')
...
0.166...
