【2】监督学习--1--分类-决策树(DecisionTreeClassifier)
决策树是一种树形结构的分类器,通过顺序询问分类点的属性决定分类点最终的类别。通常 根据特征的信息增益或其他指标,构建一颗决策树。在分类时,只需要按照决策树中的结点依次 进行判断,即可得到样本所属类别。 例如,根据右图这个构造好的分类决策树,一个无房产,单身,年收入55K的人的会被归入 无法偿还信用卡这个类别。
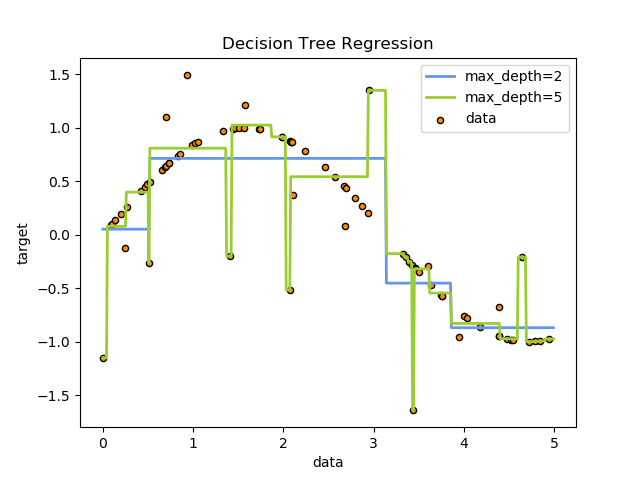
例如,在下面的示例中,决策树从数据中学习,以一组if-then-else决策规则近似正弦曲线。树越深,决策规则和训练模型越复杂。
决策树的一些优点是:
- 简单的理解和解释。树木可视化。
- 需要很少的数据准备。其他技术通常需要数据归一化,需要创建虚拟变量,并删除空值。请注意,此模块不支持缺失值。
- 使用树的成本(即,预测数据)在用于训练树的数据点的数量上是对数的。
- 能够处理数字和分类数据。其他技术通常专门用于分析只有一种变量类型的数据集。有关更多信息,请参阅算法。
- 能够处理多输出问题。
- 使用白盒模型。如果给定的情况在模型中可以观察到,那么条件的解释很容易用布尔逻辑来解释。相比之下,在黑盒子模型(例如,在人造神经网络中),结果可能更难解释。
- 可以使用统计测试验证模型。这样可以说明模型的可靠性。
- 即使其假设被数据生成的真实模型有些违反,表现良好。
决策树的缺点包括:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树。这被称为过拟合。修剪(不支持当前)的机制,设置叶节点所需的最小样本数或设置树的最大深度是避免此问题的必要条件。
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树生成。通过使用合奏中的决策树来减轻这个问题。
- 在最优性的几个方面甚至简单的概念中,学习最优决策树的问题已知是NP完整的。因此,实际的决策树学习算法基于启发式算法,例如在每个节点进行局部最优决策的贪心算法。这样的算法不能保证返回全局最优决策树。这可以通过在综合学习者中训练多个树木来缓解,其中特征和样本随机抽样取代。
- 有一些难以学习的概念,因为决策树不能很容易地表达它们,例如XOR,奇偶校验或复用器问题。
- 如果某些类占主导地位,决策树学习者会创造有偏见的树木。因此,建议在拟合之前平衡数据集与决策树。
一、sklearn中的决策树
在sklearn库中,可以使用sklearn.tree.DecisionTreeClassifier创 建一个决策树用于分类,其主要参数有:
- criterion :用于选择属性的准则,可以传入“gini”代表基尼 系数,或者“entropy”代表信息增益。
- max_features :表示在决策树结点进行分裂时,从多少个特征 中选择最优特征。可以设定固定数目、百分比或其他标准。它 的默认值是使用所有特征个数
二、决策树的使用
首先,我们导入 sklearn 内嵌的鸢尾花数据集:
>>> from sklearn.datasets import load_iris
接下来,我们使用 import 语句导入决策树分类器,同时导入计算交叉验 证值的函数 cross_val_score。
>>> from sklearn.tree import DecisionTreeClassifier
>>> from sklearn.model_selection import cross_val_score
我们使用默认参数,创建一颗基于基尼系数的决策树,并将该决策树分类 器赋值给变量 clf。
>>> clf = DecisionTreeClassifier()
将鸢尾花数据赋值给变量 iris。
>>> iris = load_iris()
这里我们将决策树分类器做为待评估的模型,iris.data鸢尾花数据做为特征, iris.target鸢尾花分类标签做为目标结果,通过设定cv为10,使用10折交叉验 证。得到最终的交叉验证得分。
>>> cross_val_score(clf, iris.data, iris.target, cv=10) ...
array([ 1. , 0.93..., 0.86..., 0.93..., 0.93...,
0.93..., 0.93..., 1. , 0.93..., 1. ])
以仿照之前 K近邻分类器的使用方法,利用 fit() 函数训练模型并使用 predict() 函数预测:
>>> clf.fit(X, y)
>>> clf.predict(x)
- 决策树本质上是寻找一种对特征空间上的划分,旨在构建一个训练数据拟合的 好,并且复杂度小的决策树。
- 在实际使用中,需要根据数据情况,调整DecisionTreeClassifier类中传入的 参数,比如选择合适的criterion,设置随机变量等。
模型的查看
方法一(未验证):
经过训练,我们可以使用导出器以Graphviz格式导出树export_graphviz 。以下是在整个虹膜数据集上训练的树的示例导出:
>>> with open("iris.dot", 'w') as f:
... f = tree.export_graphviz(clf, out_file=f)
然后我们可以使用的Graphviz的dot工具来创建一个PDF文件(或任何其他支持的文件类型):
dot -Tpdf iris.dot -o iris.pdf
方法二:
from sklearn import tree
import graphviz
dot_data = tree.export_graphviz(lin_reg_2,out_file =None)
graph = graphviz.Source(dot_data)
graph.render('pic/%s'% result_name)
报错:
OSError: [Errno 13] Permission denied
用sudo运行,结果还是报错:
graphviz.backend.ExecutableNotFound: failed to execute [‘dot’, ‘-Tpdf’, ‘-O’, ‘/data/user/sam/project/PFSC/data_analysis/1.2.build-linear-regression/pic/result/xxxx_c-2chain-30000-tree-mean.png’], make sure the Graphviz executables are on your systems' PATH
原来还得安装graphviz
sudo yum install graphviz
参考资料
