排序【0】--排序(梯度分析)
1 什么是梯度分析?
群落学物种组成数据的分析方法通常有两种:梯度分析(排序)和分类方法(聚类、TWINSPAN等)。这里的梯度分析是广义的梯度分析,泛指任何以揭示物种组成数据与实测或潜在的环境因子之间关系的方法。排序的过程是将样方或植物种排列在一定的空间,使得排序轴能够反映一定的生态梯度,从而,能够解释植被或植物种的分布与环境因子间的关系,也就是说排序是为了揭示植被-环境间的生态关系。因此,排序也叫梯度分析(gradient analysis)
2 为什么排序?
当考察植物或动物群落沿着一系列环境条件下的变化情况,我们经常发现在不同条件的群落不仅物种组成变化很大,而且这些变化往往具有连续性和可预测性。
通过排序分析,我们可以认识群落格局,也可以将排序轴跟我们已知的环境条件联系起来,看是否代表某一环境梯度。当然,也许我们必须用统计手段来检验排序轴到底是否真能代表环境因子的梯度。
3 专业术语
生态学原始数据一般由两个部分构成,一组是响应变量 (response variable,另外一组是解释变量(explanatory variables)。
(1)解释变量:相当于自变量,又称预测变量,经常分为主环境变量和协环境变量。
(2)响应变量:相当于因变量,又称物种数据。
(3)梯度分析:即通常所说的排序分析,是揭示物种组成数据与实测或潜在环境因子之间关系的方法的总称。包括约束性排序和非约束性排序
(4)约束性排序(直接排序):在特定的梯度上(环境轴)上探讨物种的变化情况。例如:RDA,CCA,DCCA等。
(5)非约束性排序(间接排序):寻求潜在的或在间接的环境梯度来解释物种数据的变化。
(6)偏分析:预先剔除物种变化中由协变量产生的效应,再通过排序揭示剩下物种变化的排序方法。
(7)混合排序分析:前面若干轴采用约束排序,而剩下的轴是非约束性排序的梯度分析方法。
(8)非约束性排序方法
主成分分析(Principal components analysis, PCA)
对应分析(Correspondence analysis, CA)
去趋势对应分析(Detrended Correspondence analysis, DCA)
主坐标分析(Principal coordinates analysis, PCO)
(9)约束性排序
冗余分析(Redundancy analysis, RDA)
典范对应分析(Canonical Correspondence analysis, CCA)
去趋势典范对应分析( Detrended Canonical Correspondence analysis, DCCA)
典型变量分析(Canonical variate analysis, CVA, db-RDA)
(10)物种响应环境梯度模型
线性响应模型经常可以通过传统的方法(最小二乘法)回归拟合。 但对于单峰响应模型,估计物种在环境梯度上最适值最简单的方法就是通过基于所有包含该物种的n个样方中环境因子值的加权平均得到。
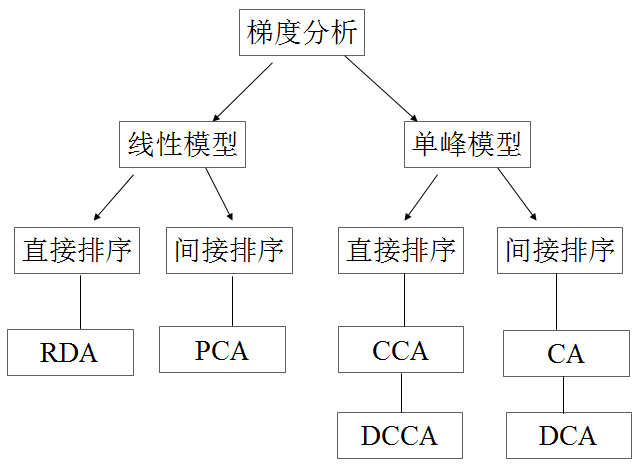
所有排序方法都是基于一定的模型之上,这种模型反映植物种和环境之间的关系以及在某一环境梯度上的种间关系。最常用的关系模型有两种:一种是线形模型(linear model),另一种是非线性模型(non-linear model)。
线性模型包括直线和曲线线性关系,其含义是某个植物种随着某一环境因子的变化而呈线性变化或叫线性反应(linear response)。这样的模型所反映的种间关系也是线性关系。大量的研究表明,植物种和环境间的关系多数情况下不是线性关系,而是非线性关系。非线性模型一般是指二次曲线模型,最著名的生态关系模型是高斯模型(Gaussian model)或叫高斯曲线(Gaussian curve)。高斯模型是正态曲线,含义是某个植物种的个体数随某个环境因子值的增加而增加。当环境因子增加到某一值时,植物种的个体数达到最大值,此时的环境因子值称为该种的最适值(optimum);随后当环境因子值继续增加时,种的个体数逐渐下降,最后消失。
在自然植物群落中,植物种和环境间的关系十分复杂,不可能完全符合高斯曲线。研究表明,即使是种数—环境关系不能与高斯曲线(正态曲线)完全吻合,但大多数种也表现为一个单峰曲线,即二次曲线模型。所以有人将植物种—环境关系模型统称为单峰模型。
重点与难点
(1) 决定排序的模型:单峰还是线性?
(2) PCA或RDA排序:中心化和标准化
(3) DCA排序:除趋势对应分析
(4) 排序得分(坐标)的尺度比例
scaling的选择:
- inner-sample distance (在R中,plot(X,scaling=2))
- inner-species distance (在R中,plot(X,scaling=1))
- synmmetic distance (在R中,plot(X,scaling=3)) 关注样方和物种的关系
这一步的目的是决定样方得分是如何尺度化?这一步操作的效应是样方和物种的得分范围相对于另一尺度而言,是扩大或者是缩小,对于特征值相似的轴,这一步的选择是不重要的。
对于名义环境变量定义的样方,样方尺度可以通过样方组间的距离解释样方组间的相似性。
对于数量型环境变量,物种尺度可以反映环境数据间的相关性。但是环境的效应大小最好通过样方尺度解释。
对于既有名义型环境变量又有数量型环境变量的数据,任何一种尺度都是合理的。
无论你选择何种尺度,排序图展示如下信息:物种的主要格局、物种和数量型环境变量间的关系以及对于名义型的环境变量,每个组中物种的平均值。
(1)在线性模型中,你需要决定物种的箭头所要表示的意义:物种的多度(多度大的箭头长)或者是要反映由物种多度转化的可比较尺度(所能解释的百分比)。
(2)如果你选择“divided by the standard deviation”, 物种箭头表示在排序空间内展示的物种变化量的比例,是个相对值;如果你选择“do not post-transform”,物种箭头表示的是物种在排序空间内的多度变化量,是个绝对值。
如何解释排序图呢?
这可以通过样方、物种、环境在每个轴上的得分间的关系实现。这有两种重要的相关关系:中心相关(centroid relations)和回归相关(regression relations),对应的法则叫做centroid principle 和 biplot rule。
(1)Centroid principle: 在默认的CA或CCA中,物种的得分是样方的加权平均。因此,在CA或CCA排序图中,物种的点在包含该物种的样方点的中央,这样包含该物种的样方点散步在该物种的周围,这种图就叫做joint plots。
(2) Regression rule: 在PCA或RDA中,物种的得分是物种数据对样方得分的回归,这样,物种得分就是一个斜率参数,连接原点与物种点,可以得到物种在每个轴拟合多度值的变化速率。将样方投射到物种线上,可以的得到每个样方中物种的拟合多度值。
(3)Distance rule: 距离规则是中心法则的扩展。距离规则说明靠近该物种的样方较远离该物种的样方包含该物种的可能性更大。样方中物种的多度的排序值可以通过样方和物种点间的距离获得。距离法则适用于长梯度的DCA排序(>3-4SD)。
线性排序图的解读
在线性排序图(PCA或RDA)中物种和数量型环境因子用箭头表示,定性环境因子和样方用符号表示(质心)。
在线性排序图中(如PCA排序图),如果我们从代表每个样方的点投影到某一物种的箭头,投影点的相对位置可以代表该物种这些样方中多度值排序情况。如果是在RDA图中,投影点代表的是拟合的多度值(即能够被排序模型所解释的部分,非观测值)的排序情况。在PCA图中,物种箭头的起始点的位置表示物种多度平均值位置,如果样方的投影点在箭头的反向延长线上,则表示该物种在此样方内多度小于平均值;反之,则大于平均值。
样方间关系:样方间的距离为欧几里得距离,长度越短表示差异越小,反之越大。
物种间关系:夹角的余弦值
物种与数量型环境变量间关系:夹角的余弦值
数量型环境变量间关系:尺度不同,意义不同。若为样方间距离尺度,环境箭头表示:Marginal effects of environmental variables on sample scores;若为物种相关性尺度,A和B之间夹角的余弦值表示二者的相关性
物种与名义环境变量间关系
如果排序图是以样方的距离为标准(Focus on sample distance),在排序图内样方点之间的距离远近(欧几里得距离)可以代表样方之间的相异程度
在线性排序图内,我们可以通过物种箭头之间的夹角来表示物种之间的相关性(见图10-3)。夹角越小,表示相关性越高,如果箭头同向,表示正相关;如果反向,表示负相关;如果夹角接近直角,表示相关性很小。用同样的规则,我们可以解读线性排序图内物种与数量型的环境因子关系(见图10-4)。比如,一个环境的因子的箭头方向与某一物种的箭头方向相同,可以预测该物种的多度是随着该环境因子的增加而递增。
在线性排序图内,从样方的点向数量环境因子的箭头做投影,投影点的位置可以近似表示该环境因子数值在这些样方内的排序。由于在进行排序模型拟合的时候,环境因子均已经标准化,所以环境因子箭头的起始点也可以认为是平均值的位点(数量型环境因子箭头之间的解读,跟物种箭头之间关系的解读是相似的(见图10-6)。但需要注意的是,这种关系不及直接拿环境因子作为原始数据进行PCA分析来得准确。也就是说,如果是简单考察环境因子之间的关系,可以直接将环境因子进行PCA分析。另外,在RDA排序图中,数量型的环境因子箭头的长短可以代表环境因子对于物种数据的影响程度(解释量)的大小,因为在环境因子进行分析之前,都已经被标准化。并且,约束排序图中环境因子的箭头长短不是来拟合环境因子在样方内值的排序,而是拟合环境因子与物种分布之间的关系。
单峰模型排序图的解读
单峰模型排序图和线性排序图的解读有很多相同的地方。但有几点的区别还是比较明显。最主要的不同的是,在线性排序图中,物种是用箭头表示,而在单峰模型排序图中,物种是用点表示。 还有另外一个重要的不同的是,在单峰排序图中,样方中的相异度(dissimilarity)是以卡方距离(chi-square)依据,也就是说,如果两个样方内各个物种的相对多度一样,那么这两个样方在图上的位置是一样的。
物种与样方间的关系:线段的长短代表了相应样方中目标物种的相对多度值高低,越短多度值越大,反之越小。(中心法则)
物种间关系:物种点间的距离为卡方距离,可以代表不同物种空间分布差异。
物种与数量型环境变量间关系:从物种点到数量型环境因子箭头的投影点的位置次序可以代表这些物种在该环境因子上的最适值。
物种与名义环境变量间关系:距离代表了该物种在相应类别中的出现的相对频率平均值的大小,距离越大,频率越小,反之越大。
样方和名义型环境变量间关系、名义型环境变量与数量型环境变量间关系、数量型环境变量间关系的解读同线性模型。
样方间关系因关注的尺度而异,若关注的尺度为样方间距离,样方间的距离为Turnover distance;若关注的是物种间距离尺度,则为卡方距离。
名义变量间的关系解读同样方间的关系,不同的尺度表示不同的距离。
推荐阅读
(1) Multivariate analysis of ecological data
(2) Multivariate analysis of ecological data using Canoco
(3) CANOCO Reference Manual and CanoDraw for Windows User’s Guide
(4)数量生态学.张金屯 著.
(6)http://regent.jcu.cz/maed/
参考资料
- 张金屯老师数量生态学专第9章讲排序http://pan.baidu.com/s/1c0vjs1U(超赞的一个关于排序的讲解)
- 基于CANOCO的数据分析(生态熊)http://pan.baidu.com/s/1kTp5vq3(超赞的一个讲解)
