【4.2.2】回归评价指标MSE、RMSE、MAE、R-Squared
分类问题的评价指标是准确率,那么回归算法的评价指标就是MSE,RMSE,MAE、R-Squared。下面一一介绍
一、均方误差(MSE)
MSE (Mean Squared Error)叫做均方误差。看公式
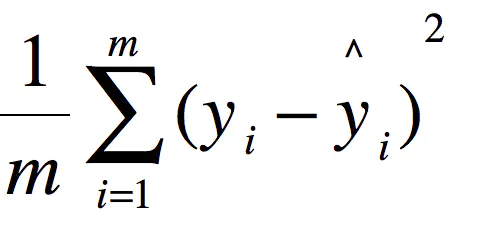
这里的y是测试集上的。
用 真实值-预测值 然后平方之后求和平均。
猛着看一下这个公式是不是觉得眼熟,这不就是线性回归的损失函数嘛!!! 对,在线性回归的时候我们的目的就是让这个损失函数最小。那么模型做出来了,我们把损失函数丢到测试集上去看看损失值不就好了嘛。简单直观暴力!
二、均方根误差(RMSE)
RMSE(Root Mean Squard Error)均方根误差。
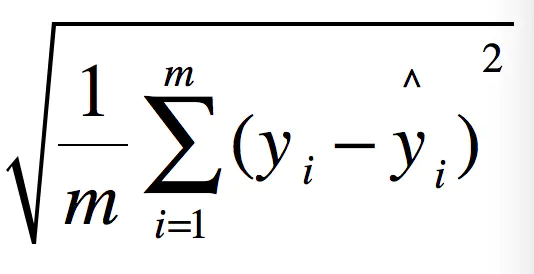
这不就是MSE开个根号么。有意义么?其实实质是一样的。只不过用于数据更好的描述。 例如:要做房价预测,每平方是万元(真贵),我们预测结果也是万元。那么差值的平方单位应该是 千万级别的。那我们不太好描述自己做的模型效果。怎么说呢?我们的模型误差是 多少千万?。。。。。。于是干脆就开个根号就好了。我们误差的结果就跟我们数据是一个级别的可,在描述模型的时候就说,我们模型的误差是多少万元。
三、MAE
MAE(平均绝对误差)

四、决定系数 R^2 (R Squared)
有人说相关系数(correlation coefficient,r )和决定系数(coefficient of determination,R 2 R^2R 2 ,读作R-Squared)都是评价两个变量相关性的指标,且相关系数的平方就是决定系数?这种说法对不对呢?请听下文分解!
4.1 协方差与相关系数
要说相关系数,我们先来聊聊协方差。协方差是计算两个随机变量X 和Y之间的相关性的指标,定义如下:
Cov(X,Y)=E[(X−EX)(Y−EY)]
但是协方差有一个确定:它的值会随着变量量纲的变化而变化(covariance is not scale invariant),所以,这才提出了相关系数的概念:
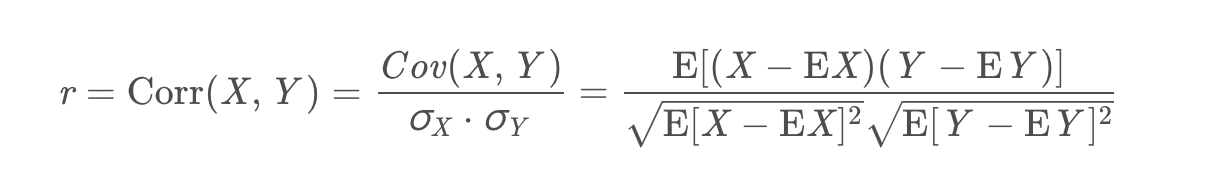
对于相关系数,我们需要注意:
- 相关系数是用于描述两个变量线性相关程度的,如果r>0,呈正相关;如果r=0,不相关;如果r<0,呈负相关。
- 如果我们将X − EX 和 Y−EY看成两个向量的话,那r 刚好表示的是这两个向量夹角的余弦值,这也就解释了为什么r 的值域是[-1, 1]。
- 相关系数对变量的平移和缩放(线性变换)保持不变(Correlation is invariant to scaling and shift,不知道中文该如何准确表达,?)。比如Corr(X,Y)=Corr(aX+b,Y)恒成立。
4.2 决定系数(R方)
下面来说决定系数,R方一般用在回归模型用用于评估预测值和实际值的符合程度,R方的定义如下:
决定系数(coefficient ofdetermination),有的教材上翻译为判定系数,也称为拟合优度。
决定系数反应了y的波动有多少百分比能被x的波动所描述,即表征依变数Y的变异中有多少百分比,可由控制的自变数X来解释.
表达式:R2=SSR/SST=1-SSE/SST
其中:SST=SSR+SSE,SST(total sum of squares)为总平方和,SSR(regression sum of squares)为回归平方和,SSE(error sum of squares) 为残差平方和。
注:(不同书命名不同)
- 回归平方和:SSR(Sum of Squares forregression) = ESS (explained sum of squares)
- 残差平方和:SSE(Sum of Squares for Error) = RSS(residual sum of squares)
- 总离差平方和:SST(Sum of Squares fortotal) = TSS(total sum of squares)
- SSE+SSR=SST RSS+ESS=TSS
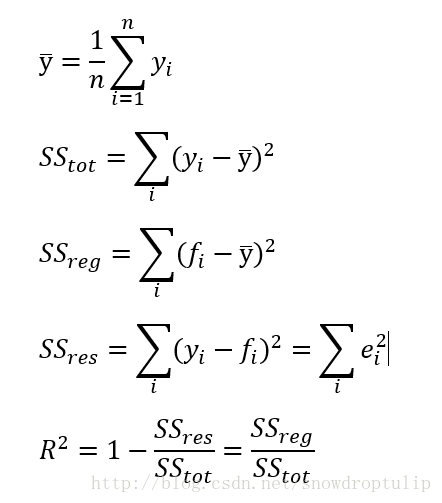
意义:拟合优度越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比高。观察点在回归直线附近越密集。 fi是预测值
取值范围:0-1.
4.3 举例
假设有10个点,如下图:
我们R来实现如何求线性方程和R2:
# 线性回归的方程
mylr = function(x,y){
plot(x,y)
x_mean = mean(x)
y_mean = mean(y)
xy_mean = mean(x*y)
xx_mean = mean(x*x)
yy_mean = mean(y*y)
m = (x_mean*y_mean - xy_mean)/(x_mean^2 - xx_mean)
b = y_mean - m*x_mean
f = m*x+b# 线性回归方程
lines(x,f)
sst = sum((y-y_mean)^2)
sse = sum((y-f)^2)
ssr = sum((f-y_mean)^2)
result = c(m,b,sst,sse,ssr)
names(result) = c('m','b','sst','sse','ssr')
return(result)
}
x = c(60,34,12,34,71,28,96,34,42,37)
y = c(301,169,47,178,365,126,491,157,202,184)
f = mylr(x,y)
f['m']
f['b']
f['sse']+f['ssr']
f['sst']
R2 = f['ssr']/f['sst']
最后方程为:f(x)=5.3x-15.5
R2为99.8,说明x对y的解释程度非常高。
五、代码
MSE
y_preditc=reg.predict(x_test) #reg是训练好的模型
mse_test=np.sum((y_preditc-y_test)**2)/len(y_test) #跟数学公式一样的
RMSE
rmse_test=mse_test ** 0.5
MAE
mae_test=np.sum(np.absolute(y_preditc-y_test))/len(y_test)
R Squared
1- mean_squared_error(y_test,y_preditc)/ np.var(y_test)
scikit-learn中的各种衡量指标
from sklearn.metrics import mean_squared_error #均方误差
from sklearn.metrics import mean_absolute_error #平方绝对误差
from sklearn.metrics import r2_score#R square
#调用
mean_squared_error(y_test,y_predict)
mean_absolute_error(y_test,y_predict)
r2_score(y_test,y_predict)
参考资料
- https://www.jianshu.com/p/9ee85fdad150
- https://theonegis.blog.csdn.net/article/details/85991138?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.no_search_link&utm_relevant_index=5
