【3.1.2.2】Pandas--合并excel的单元格
这个方法复杂,不见用这个方法。建议看前一篇博文。
具体用法:
#如果是已有dataframe
df = pd.DataFrame({'A': [1, 2, 2, 2, 3, 3], 'B': [1, 1, 1, 1, 1, 1], 'C': [1, 1, 1, 1, 1, 1], 'D': [1, 1, 1, 1, 1, 1]})
DF = My_DataFrame(df.to_dict('list'))
# 如果是新建dataframe
# DF = My_DataFrame({'A': [1, 2, 2, 2, 3, 3], 'B': [1, 1, 1, 1, 1, 1], 'C': [1, 1, 1, 1, 1, 1], 'D': [1, 1, 1, 1, 1, 1]})
DF.my_mergewr_excel('000_3.xlsx', ['A'], ['B', 'C'])
结果:
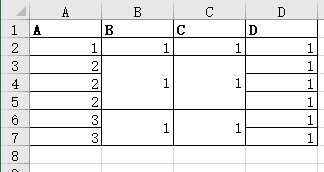
原理介绍:
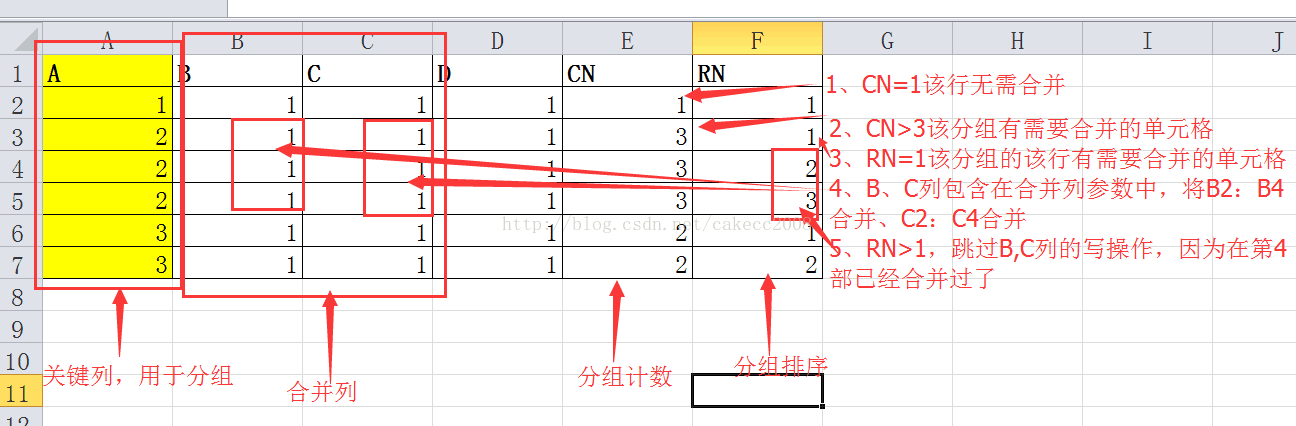
My_DataFrame函数:
# -*- coding: utf-8 -*-
import xlsxwriter
import pandas as pd
class My_DataFrame(pd.DataFrame):
def __init__(self, data=None, index=None, columns=None, dtype=None, copy=False):
pd.DataFrame.__init__(self, data, index, columns, dtype, copy)
def my_mergewr_excel(self, path, key_cols=[], merge_cols=[]):
# sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True):
self_copy = My_DataFrame(self, copy=True)
line_cn = self_copy.index.size
cols = list(self_copy.columns.values)
if all([v in cols for i, v in enumerate(key_cols)]) == False: # 校验key_cols中各元素 是否都包含与对象的列
print("key_cols is not completely include object's columns")
return False
if all([v in cols for i, v in enumerate(merge_cols)]) == False: # 校验merge_cols中各元素 是否都包含与对象的列
print("merge_cols is not completely include object's columns")
return False
wb2007 = xlsxwriter.Workbook(path)
worksheet2007 = wb2007.add_worksheet()
format_top = wb2007.add_format({'border': 1, 'bold': True, 'text_wrap': True})
format_other = wb2007.add_format({'border': 1, 'valign': 'vcenter'})
for i, value in enumerate(cols): # 写表头
# print(value)
worksheet2007.write(0, i, value, format_top)
# merge_cols=['B','A','C']
# key_cols=['A','B']
if key_cols == []: # 如果key_cols 参数不传值,则无需合并
self_copy['RN'] = 1
self_copy['CN'] = 1
else:
self_copy['RN'] = self_copy.groupby(key_cols, as_index=False).rank(method='first').ix[:,0] # 以key_cols作为是否合并的依据
self_copy['CN'] = self_copy.groupby(key_cols, as_index=False).rank(method='max').ix[:, 0]
# print(self)
for i in range(line_cn):
if self_copy.ix[i, 'CN'] > 1:
# print('该行有需要合并的单元格')
for j, col in enumerate(cols):
# print(self_copy.ix[i,col])
if col in (merge_cols): # 哪些列需要合并
if self_copy.ix[i, 'RN'] == 1: # 合并写第一个单元格,下一个第一个将不再写
worksheet2007.merge_range(i + 1, j, i + int(self_copy.ix[i, 'CN']), j, self_copy.ix[i, col],format_other) ##合并单元格,根据LINE_SET[7]判断需要合并几个
# worksheet2007.write(i+1,j,df.ix[i,col])
else:
pass
# worksheet2007.write(i+1,j,df.ix[i,j])
else:
worksheet2007.write(i + 1, j, self_copy.ix[i, col], format_other)
# print(',')
else:
# print('该行无需要合并的单元格')
for j, col in enumerate(cols):
# print(df.ix[i,col])
worksheet2007.write(i + 1, j, self_copy.ix[i, col], format_other)
wb2007.close()
self_copy.drop('CN', axis=1)
self_copy.drop('RN', axis=1)
参考资料
药企,独角兽,苏州。团队长期招人,感兴趣的都可以发邮件聊聊:tiehan@sina.cn
![]() 个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
个人公众号,比较懒,很少更新,可以在上面提问题,如果回复不及时,可发邮件给我: tiehan@sina.cn
