【1.2.4】人类基因命名规则(HUGO Gene Nomenclature Committee,HGNC)
人类基因的命名主要包括基因名称和基因符号等内容。 根据国际人类基因命名委员会(HUGO Gene Nomenclature Committee,HGNC) 颁 布 的 最 新 版 本 指 南 (2002),我刊确定了基因全称命名和基因符号命名的普遍规则。
这里的HUGO的全称为 : Human Genome Organisation
一、人类基因命名委员会-HGNC
人类中大多数基因的命名,是由HGNC(HUGO Gene Nomenclature Committee,人类基因命名委员会)来完成的。
-
HGNC(HUGO Gene Nomenclature Committee)即人类基因命名委员会,是由美国国家人类基因组研究所(NHGRI)和英国惠康信托基金(Wellcome Trust)共同出资成立的非盈利机构。
-
早在二十世纪60年代的时候,科学家们就意识到基因规范命名的重要性。于是1979年,在爱丁堡的人类基因组会议(HGM)上,Phyllis J. McAlpine博士所组成的命名委员会首次提出了人类基因命名规范。2007年9月,HGNC搬迁到欧洲生物信息学研究所(EBI)。目前,HGNC可以说是国际上非常权威的人类基因命名组织了
-
目前,HGNC已经批准了超过41500个Gene Symbol ,其中超过19190个基因属于蛋白质编码基因,超过 7300个基因属于非编码RNA的基因,同时HGNC还为假基因以及基因组特征命名。HGNC也允许个人在遵循命名规范的前提下,向他们提交Gene Symbol的命名。
我们在NCBI gene 数据库中搜索tp53,看到
- Official Symbol : TP53 provided by HGNC
- Official Full Name tumor protein p53 provided by HGNC
- Primary source HGNC: HGNC:11998
他们是什么含义呢?
- HUGO Gene Symbol:HUGO Gene Symbol(也叫做HGNC Symbol,即基因符号)是HGNC组织对基因进行命名描述的一个缩写标识符(如:TP53),这些基因符号都是唯一的。
- Gene Name:Gene Name是经过HGNC批准的全基因名称;对应于上面批准的符号(Gene Symbol)。例如TP53对应的Gene Name就是:tumor protein p53 。
- HGNC ID:HGNC ID是HGNC数据库分配的基因编号,每一个标准的Symbol都有对应的HGNC ID 。我们可以用这个编号,在HGNC数据库中搜索相关的基因。例如:HGNC:11998
有时候HGNC会对一些已经命名过的基因进行重新审查和重新命名,以确保新的基因命名在描述基因功能方面更加的准确。当一个基因被HGNC分配了新的Gene Symbol时,它之前的命名,会被当作同义词继续使用,所以一般建议使用HGNC ID而不是HGNC Symbol来作为我们处理数据中的唯一标识符。
同时,需要明确的是,因为HGNC只对人类基因进行命名,而且并不是所有的基因都有Official Symbol。所以如果基因缺少HGNC提供的Gene Symbol ,Entrez Gene数据库中的Official symbol就会变成Gene Symbol,并且Gene Symbol的编号会变成LOC前缀+Entrez ID,例如:LOC4333818

关于基因命名的组织委员会:
除了人类之外,对于一些典型的模式物种而言,也有相关的命名委员会。小鼠(mouse)的基因命名是来源于MGNC(可访问MGI数据库),大鼠(rat)基因命名来源于RGNC(可访问RGD数据库),斑马鱼的基因命名来源于ZFIN。还有一些其它物种的基因命名,基本就来源于NCBI的Gene数据库和Uniprot数据库。如果有些基因这些数据库里都没有命名,那么一般会直接从一些典型的模式物种(例如小鼠,斑马鱼等)的同源基因命名中引进。
二、基本原则
人类基因的命名应该遵循 6 个基本原则:
- 每一个基 因的符号具有唯一性;
- 基因符号是基因名称的缩写,一 般不超过 6 个字母;
- 基因符号应由拉丁字母或其与阿拉 伯数字组合而成;
- 基因符号不应含标点符号;
- 基因符 号不应以 G 为末端;
- 基因符号不涉及其他种属。
基因全称命名规则:
- 名字的开头应用小写字母,但 有三个例外,即用人名表示疾病、表型或者是首字母的缩 写;
- 如果存在别名,应该包括在这个名字里面,并加括 号;
- 若为其他种属的名称,必须写在最后,加括号标注。
基因符号命名规则:
- 人类基因符号为大写拉丁字母 或其与阿拉伯数字的组合(除 C#、ORF# 符号外)。 不用 罗马数字(过去用的罗马数字要改为对等的阿拉伯数字 );
- 基因符号在书写时应用斜体。 但在目录中例外;
- 希 腊字母不用作基因符号。 所有过去用的希腊字母应转换 为拉丁字母;
- 前缀为希腊字母的基因名称应转换为对 等的拉丁字母并放在基因符号的末端,具有类似性质的 基因可按字母顺序排列;
- 不使用标点符号(除 HIJA 免 疫球蛋白和 T 细胞受体基因符号可用分字号外);
- 基 因符号通常不表示选择性转录物,但当一组具有多个小 编码序列形成多种不同的大的基因产物时,这些小的编 码序列可用不同符号表示;
- 应避免表示组织特异性或 分子量。
- 应避免某些字母或字母组合作为基因符号的 前、后缀而试图给出特定意义;9癌基因的符号是对应于 逆转录病毒同源癌基因,但基因符号不加“v-”或“c-” 前缀,全称要加。
此外,对于某些约定俗成的基因名称,仍沿用以前的 形式,比如 survivin 和 p53 可为小写,斜体表示基因,标准 体为蛋白质;BCL-2 或 Bcl-2 、c-Myc 大小写混用,斜体 表示基因,标准体为蛋白。
二、讨论
2.1 旧的gene symbol如何查找呢?
在TCGA提供额 gencode.v23.annotation.gene.probemap 文件中看到ensembl id和gene symbol对应表
ENSG00000249458.1 RP11-624A4.1 lincRNA long_noncoding
ENSG00000250263.1 RP11-765K14.1 lincRNA long_noncoding
用RP11-765K14.1 去 https://www.genenames.org/ (这个网站很强大,能实现绝大多数gene id 和gene symbol的转换)搜索无果,然后用ENSG00000250263搜索出结果,发现gene symbol已发生变化,并且没有提示以往的gene symbol是什么
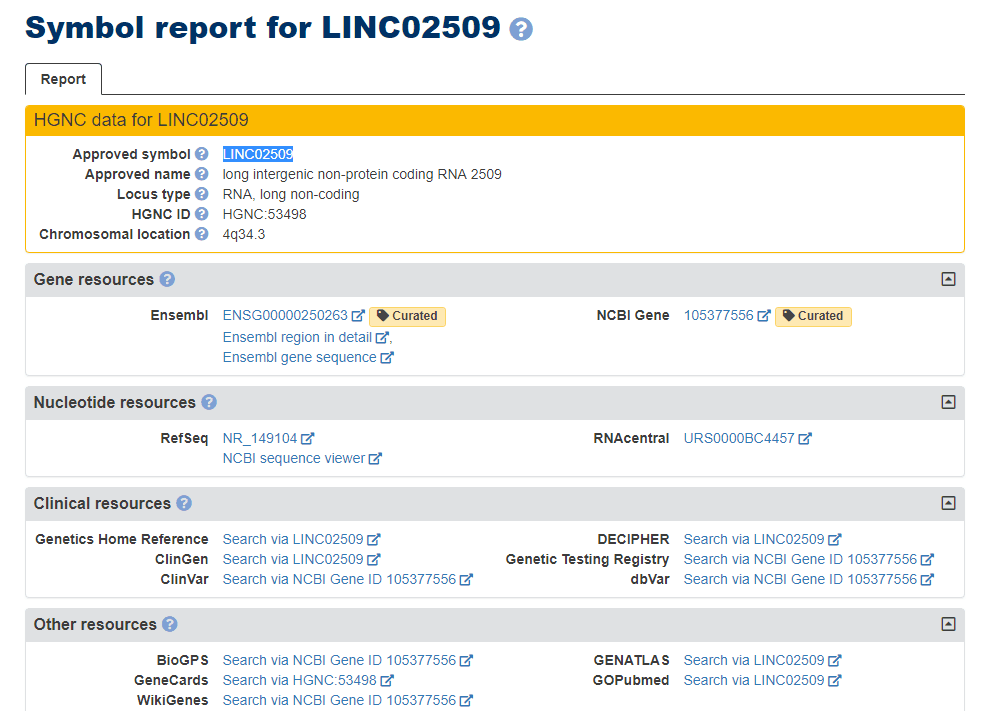
问题来了,RP11-765K14.1为什么会被删掉? RP11-765K14.1这种类型的旧的gene symbol 应该去哪查询,获知现在新的ID呢?
因为参考基因组不一样,genenames采用的hg38的基因组版本,而gencode.v23对应的还是hg19的基因组版本
参考资料
- 《人类基因命名规则》
