【3.9.5】一级核酸数据库-ICGC
DNA序列的变异是所有肿瘤细胞发生的重要的分子层面的原因, 当前学界已经有能力对一定规模的癌症队列样本开展全基因组变异图谱的分析. 国际肿瘤基因组协作联盟(ICGC)于2007年成立并启动了全球范围的肿瘤基因组研究工作. ICGC提出对
- 50种癌症
- 总计25000例患者样本绘制体细胞基因突变谱
多个国家的参与课题组已经阶段性地总结了 特定癌症的数据并报道了研究成果, 当前跨癌种的泛癌症基因组研究已经成为ICGC的工作 重点. 我国以中国肿瘤基因组协作组(CCGC)的形式参与了ICGC的合作研究, 选择包括食 管癌、胃癌、肝癌、大肠癌、鼻咽癌等13种癌症并取得相关进展. CCGC和ICGC研究工作将 积极推动癌症基因组学向肿瘤生物学的转化研究, 为肿瘤的个体化精准诊疗提供理论和技 术支撑.
一、项目背景
1.1 ICGC的任务与目标和运行模式
在开展国际合作之前, 英国和美国等基因组学 研究的先进国家已经启动了本国的肿瘤基因组项目
- “癌症基因组项目”(Cancer Genome Project, CGP, 英国, http://cancergenome.nih.gov/)
- “癌症基因组解剖 项目”(The Cancer Genome Atlas, TCGA, 美国, http://cancergenome.nih.gov/ ).
2007年10月, 来自11个国家从事肿瘤和基因组研 究的科学家和资助机构代表齐聚加拿大多伦多, 共 同发起了ICGC组织. 发起国成员来自加拿大、美国、 英国、德国、法国、西班牙、澳大利亚、日本、印度、 新加坡和中国, 由加拿大安大略癌症研究所(Ontario Institute for Cancer Research, OICR)主任Tom Hudson 担任总协调人. ICGC在成立伊始即强调它将协调全 球的肿瘤基因组研究, 调动基因组学和肿瘤学领域 科学家的积极性, 以实现资源、人才和技术的集成与 数据共享.
2010年4月, ICGC在Nature阐述了该组织的任务 与目标[25]. ICGC的首要目标是对50种在全球范围内 高发的癌症或亚型展开全基因组变异的分析, 每一 癌种计划完成500例患者样本的测序分析, 从而全面 绘制这些癌症的体细胞变异图谱, 即包括单碱基的 变异、插入、缺失、拷贝数的变化、染色体易位和其 他形式的重排. 数据要符合以下质量条件:
- 完整 性, 患者群体中出现频率大于3%的体细胞变异均被 识别;
- 高分辨率, 即变异检测达到单碱基分辨率;
- 高数据质量, 原始数据符合技术平台的一般标 准, 体细胞变异检测的特异性要达到95%, 敏感性要 达到90%;
- 尽可能地获得来自同一患者组织的转 录组和表观基因组的数据.
ICGC成员遵从多伦多宣 言的准则[26], 将致力于使产生的数据尽快向社会公 开, 并帮助研究者个人、组织、资助机构和参与国家 的管理者使用这些数据, 同时支持新方法、软件的研 制和标准的制定与推广
为了达到上述总体目标, ICGC成立了相应的委 员会和工作组来开展不同方面的具体工作.
- 首先, 各 国研究团队推举出1~2名领域内资深科学家组成国际学 术 指 导 委 员 会 (International Scientific Steering Committee, ISSC), 全面掌控ICGC的发展方向, 并负 责与各国基金机构沟通, 积极争取资金支持.
- 下设 ICGC执行委员会(Executive Committee), 主要负责督 促各国单癌种的项目进展, 并协调不同团队对同一 肿瘤的合作研究.
- 同时, 成立伦理和政策委员会 (Ethics and Policy Committee)开展伦理方面的工作, 重点在于从各国的法规和习俗出发, 提出研究过程 和数据发布的伦理指南.
- 在该委员会内成立了 样本识别和隐私保护工作小组(Identifiability and Privacy Subgroup)细化患者隐私的保护工作.
- 在技术 方面成立技术工作组(Technologies Working Group), 发布可用于肿瘤研究的最新的基因组学和生物信息 学方法, 并对现有技术进行评估, 建立ICGC内的技 术标准并推广, 以利于不同研究组产出数据的可比 性.
- 最后, 数据协调和管理工作组(Data Coordination and Management Working Group)负责协调参与国的 存储和计算资源, 开发数据管理的软件, 并对快速积 累的海量数据进行日常维护工作, 该团队当前的工 作重点是建立云存储和云计算平台.
1.2 ICGC病例入组标准和数据分析存储标准
肿瘤基因组学研究能否获得实质性科研产出取 决于一个最基本的问题: 研究用生物样本的质量和 数量, 包括符合临床诊治规范的临床研究队列, 高质 量的组织样本和详细的临床、病理、治疗与随访等资 料. ICGC主要参照了美国NCI和TCGA对所资助的生 物标本采集项目提出的统一标准. 知情同意事宜需 要放在首要位置. 知情同意书的模板由ICGC的伦理 和政策委员会讨论确定. 但是, 由于是国际项目, 各 国的国情、法规和习俗不同, 翻译的因素也不得不考 虑, 因此各国的知情同意书稍有差别. 在符合生物伦 理规范的基础上, ICGC要求进行基因组分析的样本 需要符合以下条件:
- 所有入组病例采集肿瘤组织标本和同个体 的正常配对组织, DNA检测建议使用术前外周血, 用 来区分体细胞突变患者个体的多态性位点; RNA和 甲基化检测则使用癌旁正常组织, 用来比较得出差异表达基因和差异甲基化位点.
- 送检肿瘤组织和血液标本最好在未经放疗和化疗前采集, 如有治疗需注明.
- 送检肿瘤标本病理诊断须明确, 对于大部分实体瘤癌细胞含量需70%以上, 对于个别难以达到 的癌症(如胰腺癌)需要专门的协作小组讨论确定; 同 时癌组织坏死比例低于20%.
- 手术标本必须迅速置于液氮中, 然后保存于 −80°C或−130°C冰箱, 这一过程要求在手术离体后30 min内完成.
- 为验证病理学诊断的结论, 每个癌组织需保 留5~10张组织切片, 冰冻组织、石腊组织或活检组织 均可, 但要尽量接近基因组测序所用的组织块.
如前所述, 癌症基因组数据分析软件众多; 很 多参与ICGC的实验室都开发了自己的生物信息学工 具. 为了使各国实验室产出的数据具有更好的可比 性, ICGC技术工作组成立标准流程分析工作组 (Benchmark Analysis Working Group)专门比较分析 不同平台和不同信息学流程. 该小组联合了全球14 个实验室对相同的数据进行统一的验证和校准, 已 完成论文文稿, 已投Nature Biotechnology. 另外, 该 小组与TCGA合作开展ICGC-TCGA-DREAM Somatic Mutation Calling Challenge. 这是一个开放的项目, 希 望国际上更多的生物信息研究者贡献力量, 共同改进 肿瘤基因组变异识别的方法. 需要承认的是, ICGC数 据处理流程的标准化相对不足, 流程统一的进度迟缓, 这对于下一步开展泛癌症基因组分析造成了一些障碍 (关于泛癌症基因组的内容将在下文详述).
由于数据量巨大, ICGC的数据将采用分布式存 储, 有利于参与的课题组对数据的下载和使用[27]. 这些数据由位于OICR的数据协调中心(Data Coordi- nation Centre, DCC)统一管理, 全球6个计算资源中 心参与, 并以云平台的方式运作: 芝加哥大学、欧洲 生物信息学研究所(Hinxton, 英国)、巴塞罗那超算中 心(Barcelona Supercomputing Center)、德国国家癌症 研究中心(Deutsches Krebsforschungszentrum, DKFZ)、 日本理化学研究所(RIkagaku KENkyusho/Institute of Physical and Chemical Research, RIKEN)、韩国电子通 信研究院(Electronics Technology Research Institute, ETRI). 现在, 前3个中心的计算资源已经投入运作. 研究者获得数据授权后可以在任意地点登陆和处理 数据, 软件和数据均在云平台上安装和调用.
1.3 ICGC的项目进展和亮点成果
截至2014年5月, ICGC共协调启动了针对22个癌 症类型的74个研究项目, 这些项目承诺完成至少 25000例肿瘤患者的癌组织测序分析. 研究团队来自 亚洲、欧洲、北美洲、南美洲和澳大利亚(图2(a)). 现 在数据库中已经记录了26846份肿瘤样本符合ICGC 的伦理规范和病理质控. 从癌症类型来看, 排在前4 位的分别是乳腺癌、中枢神经系统癌症、血液系统癌 症和前列腺癌(图2(b)). 其中成人肿瘤样本24426例, 儿童肿瘤样本2520例(图2(c))
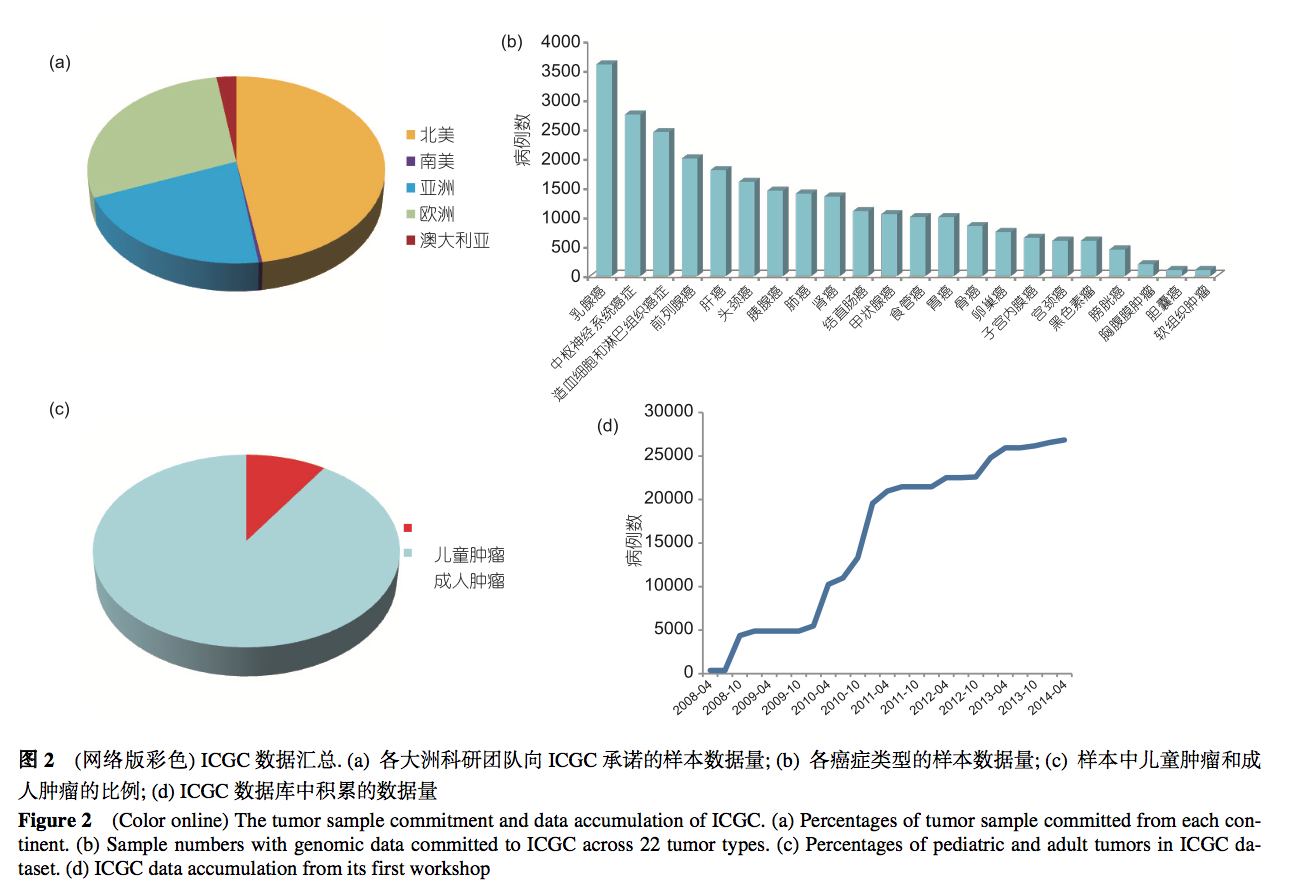
截至2014年5月, 总计 18000余份样本完成了不同程度的“组学”分析: 1096 个全基因组数据, 5560个外显子数据, 16936个拷贝数 变异谱, 17297个转录组数据和9017个表观基因组数 据上传到了ICGC数据库中(图2(d)). 每个样本的变异 位点和注释信息可以在DCC (http://dcc.icgc.org)直接 得到.
原始数据则需要向数据管理协调办公室(Data Access Compliance Office, DACO)申请. 考虑到肿瘤 样本的全基因组信息也包括患者个人的遗传隐私, 建立一套在共享科学数据的同时也能够保护患者隐 私的机制十分重要, 一个海外委员会国际数据管理 委员会(International Data Access Committee, IDAC) 将监督DACO工作并协助解决沟通和技术问题. 截至 2014年5月, DACO已经配准了497位研究者/研究团 队申请使用ICGC的数据. 关于ICGC项目进展的具体 情况可以从http://www.icgc.org获知.
从ICGC开始实施起, 已经有10篇肿瘤基因组学 的科研成果以ICGC的名义发表在生物医学期刊上. 英国Sanger的研究团队从癌细胞克隆进化的角度以 乳腺癌为对象开展了探索性的工作. 首先, 他们分析 了21例患者组织的全基因组突变位点以及相邻碱基 的序列, 提出了突变过程标签(mutational process signature)的概念. 利用这种分子标签对患者聚类, 发现与患者生殖系BRCA1/2的突变情况相吻合[28]. 与此同时, 通过对癌组织超高深度的测序(188x), 可 以对癌组织突变的等位基因频率(allele frequency)的 进行估算和定相(phasing), 从而对一例患者的癌组织 系统发生在分子水平进行勾画, 更重要的是可以识 别出癌细胞克隆亚群形成过程中的关键节点基因[29
ICGC框架内针对骨髓异常增生综合征(myelody- splasia syndromes, MDS)的基因组学研究团队由英国 和意大利的学者组成, 他们在New England Journal of Medicine和Blood上集中报道了一批研究成果
首先, 他们在骨髓异常增生伴环状铁幼粒细胞 (myelodysplasia with ring sideroblasts, MRS)中发现 SF3B1的突变频率高达65%, 生物学实验进一步证实 该基因突变导致mRNA的异常剪切从而诱发MDS的 发生[30]. 在其他MDS, 骨髓增生性肿瘤(myelopro- liferative neoplasm, MPN)以及MDS诱发的急性髓性 白血病(acute myeloid leukemia, AML)中, 他们也发 现SF3B1的突变分布广泛, 同时携带突变的 MDS/MPN患者预后较好且不易演化为AML[31]. 除 了SF3B1外, 该团队进一步在多种MDS患者DNA (共 738例)中检测了的111个候选驱动基因, 他们发现在 78%的患者中至少有一个原癌性质的突变, 并提出 了一个“遗传宿命(genetic predestination)”的假说, 即 早期的驱动性突变, 特别是RNA剪切相关基因的突 变决定了癌细胞之后的克隆演化的轨迹[32].
来自印度的科研团队对龈颊鳞状细胞癌(gingivo- buccal oral squamous cell carcinoma, OSCC-GB)进行 了外显子组分析, 他们发现USP9X, MLL4, ARID2, UNC13C和TRPM3在OSCC-GB中突变频率较高,DROSHA和YAP1在OSCC-GB患者中经常发生扩增, 而DDX3X则经常缺失[33]. 来自德国的科研团队对纤 维性星形细胞瘤(pilocytic astrocytoma)进行了全基因 组分析, 发现FGFR1和PTPN11的体细胞突变以及 NTRK2的基因融合在纤维性星形细胞瘤患者中重复 出现; 更重要的是所有此类癌症患者的组织都携带 至少一个MAPK通路家族的突变, 并且没有其他生 物学通路富集突变, 说明这种癌症是一类单通路的 疾病[34]. 来自法国的研究者对Ewing肉瘤的基因组分 析发现, STAG2的突变和CDKN2A的缺失在患者群体 中经常互斥的发生; 但是与之相反的, STAG2和TP53 的突变则倾向于在共同出现并与预后不良相关[35]. 在与肿瘤基因组相关的生物伦理研究中, ICGC的伦 理和政策委员会发布了他们的调查报告和一些讨论, 当前云计算在基因组数据分析中作用越来越大, 一 些忧虑随之产生, 如数据安全, 控制和可靠性等. 这 些方面需要协调不同国家的法规、习俗并制定相应的 国际标准[36]. 最后, 在技术研发方面, ICGC的生物信 息技术组报道了信息学方法判断“组学”得到的变异位点和变异基因是否具有生物学意义[37].
1.4 ICGC面临的挑战和泛肿瘤基因组(Pan- Cancer Genome)研究计划
ICGC的工作也表现出不 足的方面:
- 第一, 由于没有统一的经费资助来源, ICGC的组织更多依赖于参与的科学家的兴趣, 造成 各国课题组研究进度不一, 样本和信息学流程的质 量控制标准也不一致, 从而对比较癌症基因组的研 究带来困难. 与之对照的是美国独立运作的TCGA计 划, 由于其组织严密, 数据产出效率高, 在ICGC中 已经有一家独大的趋势.
- 第二, 由于取样困难, ICGC 积累的数据中儿童肿瘤和罕见肿瘤比例很少.
事实上, ICGC的指导团队也充分正视了上述经 验教训, Tom Hudson教授代表ICGC ISSC提出, 今后 5年ICGC仍会致力于它的创始初衷并设立了一些新 的目标:
- 加大儿童肿瘤和罕见肿瘤的研究力度, 积极在全球寻找样本资源以及基金支持;
- 改进 ICGC数据库中的数据质量;
- 开发软件和信息学 平台来支持数据管理和应用;
- 建立一套高效的数 据提供平台, 提高基因组数据的使用效率为下游研 究服务, 同时要保护患者的隐私信息;
- 协调跨癌 种的基因组学研究;
- 为基础和临床医学工作者提 供使用ICGC数据和工具的培训.
2014年上半年, Tom Hudson向多个国家15位基金负责人和24位科学领袖 调查开展进一步研究计划的可行性(暂时定名为 ICGC 2), 得到了绝大多数参与者的积极支持
当前TCGA走在泛肿瘤基因组分析的前 沿, 启动了专门的TCGA Pan-Cancer Analysis项目, 并已经集中发表了一批研究报告( http://www.nature.com/tcga/ ). 借鉴TCGA的成功经验, ICGC ISSC邀请 全体参与者共同开展泛肿瘤基因组分析并收集研究方案. 经过委员会及受邀专家审核, 最后共有135个 研究方案被列入ICGC的计划中. 为了协调众多的参 与者, ICGC成立了泛癌症基因组分析工作组(Pan- cancer Analysis Working Group, PAWG). 经过北京工 作会议的讨论, 决定将所有研究课题归纳入16个研 究方向(表2)并成立相应的工作小组, 每个小组均由 国际知名基因组或生物信息学家牵头和召集, 每个 方向的研究任务和它们之间的配合关系也已经明确. 先期的研究工作已经取得了部分成果. Wong等人[38] 对7651个样本的基因组数据综合分析发现CUX1的功 能丢失性突变在各类肿瘤1%~5%的患者中发生, 同时 对2519例各类髓系恶性病变患者数据分析发现CUX1 的突变患者预后不良, 他们通过小鼠和果蝇的实验模 型证实了CUX1作为抑癌基因的功能. 这一工作也证 实了泛癌症基因组研究的重要意义. 我国在这方面工 作落实的差距较大, 需要高度关注.

1.5 CCGC的任务和面临的挑战
我国科研工作者在基因组学领域起步较早, 早 在HGP时期就承担了1%的国际合作任务, 后来又在 人类单体型图计划(Hap-map)中顺利完成了10%的任 务. 尚在国际基因组学和肿瘤学界对肿瘤基因组计 划凝聚共识之际, 我国就积极参与讨论, 并在ICGC 启动之时成为发起国之一, 杨焕明教授和吕有勇教 授负责协调中国的研究事务. 为了更好地集成我国 肿瘤医学和基因组学领域的资源、人才和技术的优 势, 我国从事基因组和肿瘤学的科学家借参与ICGC 之际, 组建了“中国肿瘤基因组协作组”(CCGC). 之 后, 国内的研究者和项目即以CCGC的名义加入 ICGC国际合作之中. 在CCGC的协调下, 国内相关 临床、病理和技术人员有组织地参加ICGC各委员会 和工作小组, 并派代表参加了历次工作会议
由于ICGC并没有统一的经费来源, 因此CCGC 成立之初的一个重要目标是凝聚学界共识、争取基金 支持. 这里需要强调的是国家“十二五”国家高技术 研究发展计划(863)项目“重大疾病的基因组学研究” 对CCGC工作的支持. 该项目设立12个课题, 除前2 个课题为基因组技术和表观基因组技术的开发外, 其他10个课题均为肿瘤研究, 涵盖13个癌种, 依次为 胃癌、肝癌(HBV相关)、食管癌、大肠癌和鼻咽癌、胰腺癌、脑瘤、肺癌、乳腺癌、膀胱癌、肾癌、甲状 腺癌和白血病. 其中前5种癌症按照ICGC的标准计 划完成500例样本的基因组分析工作. 该项目主要研 究与肿瘤发生、发展、转移、预后和药物反应相关的 基因组和基因变异、阐明代谢、信号传导和表达调控 “三大网络”, 为肿瘤的个体化诊疗研究提供基础数 据, 同时选择有科学代表性和技术可行性的癌种进 行单细胞分析、发展无创早期诊断等基因组学和生物 信息学的优化、整合和临床应用的创新研究. 项目首 席科学家为张学军教授. 在ICGC成立伊始, 我国仅 以胃癌作为探索全基因组分析的首选肿瘤参与合作. 之后, 在“863”课题的支持下, 2012年, 肝癌(HBV相 关)、食管癌、大肠癌和鼻咽癌也被列入ICGC计划之 中. 2014年初, 其他研究规模较小的10余癌种也参与 到ICGC合作研究中
中国常见高发肿瘤基因组研究进展
国内肿瘤基因组研究的首项标志性成果来自于 瑞金医院陈竺团队, 他们用外显子测序技术发现急 性髓细胞样白血病(AML-M5和AML-M4)的发生与 DNMT3A基因突变相关, DNMT3A的突变可以改变肿 瘤细胞的甲基化谱和表达谱(如HOXB)[39]. 瑞金医院 其他的课题组对内分泌系统癌症的基因组研究做出 了贡献. 宁光课题组通过外显子组测序在胰腺神经 内分泌瘤中发现YY1上的T372R突变在30%的样本均 有发生[40], 并利用同样的技术在肾上腺库欣综合征 中发现PRKACA基因上的L205R位点在65.5%的样本 中均有突变[41]
国内在肿瘤基因组领域取得重要成果的另一个 单位是北大深圳医院/深圳市第二人民医院, 他们对 泌尿生殖系统的肿瘤基因组展开了重点研究. 该实 验室发现泛素介导的蛋白酶解途径中的基因在肾癌 中发生了广泛的DNA突变, 这些突变与HIF1α或 HIF2α的表达升高有关. 同时, 他们发现染色质重塑 基因在膀胱癌中突变频率较高, 并与分型、预后等相 关[42]; 并在膀胱癌中报道了FGFR3和TACC3在RNA 水平的融合, 以及参与纺锤体形成的STAG2和ESPL1 的突变[43]; 最后, 他们测序得出雄激素受体基因的 突变在中国人群的膀胱癌中并不常见[4
食管癌是我国常见的癌症之一. 与西方不同, 我 国高发的食管癌类型为食管鳞癌. 因此, 以中国医学 科学院肿瘤医院为代表的国内众多实验室对食管鳞 癌的基因组突变图谱进行了系统的研究. 詹启敏课题组[45]对食管鳞癌的全基因组和外显子组研究发现 RTK-MAPK-PI3K通路、细胞周期和表观修饰相关基 因突变频率较高, 并报道了FAT1, FAT2, ZNF750和 KMT2D在食管癌中突变情况及其功能. 赫捷课题组 通过对例食管癌患者的癌组织和外周血外显子的对 比分析, 发现细胞周期和凋亡通路在99%的样本中 发生突变, 主要为TP53的突变所贡献. 组蛋白修饰 相关的基因同样突变频率较高, 其中EP300的突变与 患者预后不良相关. 另一项对食管鳞癌的研究来自 王明荣课题组, 他们与国外研究所合作, 在食管鳞癌 中报道了上述类似的基因突变谱, 并结合DNA 突变和蛋白表达的数据提出XPO1具有潜在的药靶 价值[46].
肝癌在我国危害较大, 国内多个实验室对肝癌 的基因组学变异展开了深入探索. HBV相关肝癌是 我国最常见的肝癌类型, 韩泽广课题组[48]通过外显 子测序发现ARID1A在HBV相关肝癌中突变频率较 高, 并通过RNA干扰技术证实了VCAM1和CDK14的 突变对肝细胞癌有促进作用. 另一个项目组在HCV 相关的肝癌中发现了相似的突变基因, 同时在西方 人的样本中验证了这些变异, 提示了ARID1A作为抑 癌基因在肝癌中的普遍作用[49]. 亚洲癌症研究组织 (Asian Cancer Research Group, ACRG)启动了全基因 组测序研究, 鉴定了大量HBV与癌细胞染色体的整 合位点, 其中TERT, MLL4, CCNE1的HBV整合事件 促进了肝细胞癌的发生[50], 同时他们发现Wnt/beta- catenin和JAK/STAT通路基因富集了体细胞突变, 其 中JAK1的突变被证实发挥了原癌基因的作用[51]. 另 一些课题组围绕肝癌的生物学问题进行了其他层次 的研究. 吴仲义课题组[52]用基因组学手段对肿瘤细 胞的克隆进化进行了研究, 以肝癌为对象鉴定了一 些克隆形成过程的关键节点基因. 曹雪涛课题组[53] 则对小RNA进行了高通量分析, 发现miR-199a/b-3p 在肝癌组织中表达下调, 并与患者预后不良有关, 这 一 miRNA 可 能 通 过 靶 向 P AK4 从 而 抑 制 P AK4/Raf/ MEK/ERK通路在肝癌细胞中发挥作用.
二、ICGC
international cancer genome consortium
tcga是属于美国的,icgc是属于世界的。。。
分析数据的 ICGC Data Portal
…..
三、下载数据
-
由于icgc连接了世界多个数据库(云端)资源,所以架构比GDC复杂很多,conda也没有channel提供编译好的icgc-get
-
icgc-get提供了ICGC数据库的搜索与下载功能,但它本身下载功能的实现需要特定的软件,也就是icgc-get包是ICGC与多个软件的连接器
-
因为hpc无root权限,尝试安装ICGC直接提供的压缩包安装软件失败,也不能用docker,所以只能一步一步把这些软件拼起来。我也是在逐步的摸索中了解ICGC数据库的布局以及数据下载的大致轮廓。
-
ICGC本身的官方文档看似不错,实则很混乱,通过对比和研究可以真正理解如何下载、安装以及配置。几个重要doc
-
https://docs.icgc.org/download/icgc-get/#icgc-get-user-guide
3.1 安装icgc-get (暂时还没试)
- github链接: https://github.com/icgc/icgc-get
- 克隆仓库,然后运行pip install -r ./requirements.txt
- 再运行pyinstaller –clean icgc-get-data.spec得到可执行文件(位于dist目录下)
3.2 不同repository的数据下载
ICGC的数据存储在不同的repository中,不同的仓库有不同的下载工具,所以当在ICGC上搜索到想要下载的数据后,确定其仓库,安装好对应的客户端。
3.2.1 Collaboratory和AWS使用客户端 score-client
cd /home/sam/project/neoantigen/lib
wget -c https://artifacts.oicr.on.ca/artifactory/dcc-release/bio/overture/score-client/5.8.1/score-client-5.8.1-dist.tar.gz
tar -xvzf score-client-5.8.1-dist.tar.gz
3.2.2 GDC使用客户端gdc-client
这个没什么好说的,文档很多,也很简单。
3.2.3 EGA
看https://ega-archive.org/download/using-ega-download-client#DownloadClient, 我暂时也用不到
3.2.4 PDC这个仓库很重要
It is a secure data cloud that stores US PCAWG data. 它存了PCAWG很多样本的WGS数据,里面就有TCGA的!使用的客户端是Amazon Web Services Command Line Interface,需要follow
https://docs.aws.amazon.com/cli/latest/userguide/installing.html 进行安装,其实也使用pip,一句话
pip install awscli --upgrade --user
安装完后要把执行文件添加到路径中去
export PATH=~/.local/bin:$PATH
3.3 权限
除了安装,另外一个重要点就是获取下载权限了。
参考资料
- 《肿瘤基因组学与全球肿瘤基因组计划》
- https://www.jianshu.com/p/0de229b751a9
