【4.3】基于保守性和规则性的预测方法SIFT和PolyPhen
有什么特征可以帮助我们来区分导致功能和表型变化的变异和其他变异,然后我们如何综合特征来做出一个预测模型?

表型或功能的改变(phenotypical/functional effect)
- 个体表型上的体现(导致疾病的或不导致疾病的)
- 演化上的概念(它是不是会影响这个人的适应性,deleterious,还是说它对人的 这个 适应性没有影响,即neutral)
- 特征(比如头发,身高)
…… ……
一般来说,蛋白序列的改变,它就更有可能结构和功能的改变,就更有可能在细胞水平的改变,可能最终造成人的各个的表现的改变,但所有的这些都不是绝对的,都是统计的一个概念
我们如何预测非同义突变对功能表现的影响?
一、简介
SIFT是基于保守性的一个算法,这个方法是2001年由Pauline和Henikoff发表的,SIFT和BLOSUM(作者是Hennikoff)作者是一个课题组,虽然替代矩阵可以评估两个氨基酸的相似性和可替代性,但是其实在不同的蛋白,不同的位点,它对氨基酸替代的容忍程度是不一样的,所以它后来就做了一个基于同源蛋白每一个位点上的氨基酸保守性的评估,有一些位点,它就是超级保守,在所有的物种中都没有看到过其他的任何别的氨基酸,那你如果在一个个体中看到那个位点有一个变异,哪怕它不是很严重的一个变异,但可能在那个位点,它就是严重的,还有一些位点呢,就在不同物种的同源蛋白中,你看他什么氨基酸都可能出现。(说了好绕口啊,其实就是保守性嘛) SIFT基于一个重要位点它应该在一个物种中的同源蛋白中应该是比较保守的,如果在这些位点上发生了突变,那这些突变更有可能会导致个体的适应性的下降。
第一步:把可能的同源蛋白先找出来,这就是一个数据库搜索,也就是BLAST(PSI-blast是BLAST的一个变种,比BLAST更好一点)做的事情。
第二步:只挑那些相似度比较高的,那更有可能在功能上仍然一致的序列来进行后续的比对,它挑的是在比对上的这些区间要有90%的一致性。
第三部:然后做多序列比对

你可以看到有些位点就是完全保守的,有些位点会有一些变化,而有的一些位点变化比较多
第四步 根据每一个位点,你所看到的氨基酸的分布就可以算一个概率,基于这个概率,他得到最后一个值,一个数值的预测值,如果这个SCORE分数小于0.05,它就预测它是deleterious,如果是大于0.05,它就是中性的,不会造成功能和表现的改变
这个是可以通过软件实现的,应该是傻瓜式的操作不,06年他们发表一个文章,假阴性(False Negative rate)是31%,即31%影响功能和表型的变异被它预测了不影响,False Positive(假阳性),预测出来是影响表型功能其实是不影响的,Coverage,所有这些同义突变里,有60%是它可以用来做预测的。
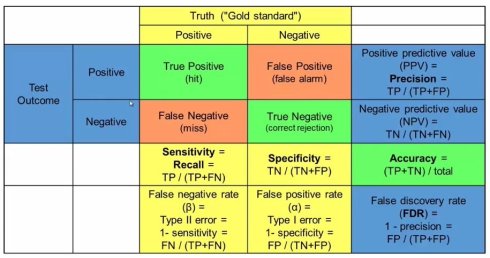
当然啦,这个准确度还是不太尽人意的。那么我们怎样地应一个准确度呢? 首先,你希望预测的是什么?你希望真正知道的就是这样的变异是不是真的影响表型,Positive就是说的确影响表型,Negative就是不影响表型 我们要有模中实验或者计算的策略做一个评估,所有的实验的结果,或者预测的结果。下面的图你一看就懂了,有点点像博弈论中的矩阵图
PolyPhen同时结合序列和结果上的信息,主要的假设就是说有一些氨基酸的改变可能会影响蛋白的折叠,影响蛋白的的相互作用区间,影响它的稳定性 ,而蛋白结构如果有改变,那蛋白的功能就更可能会发生改变,所以它整合了序列和三维结构的一些特征
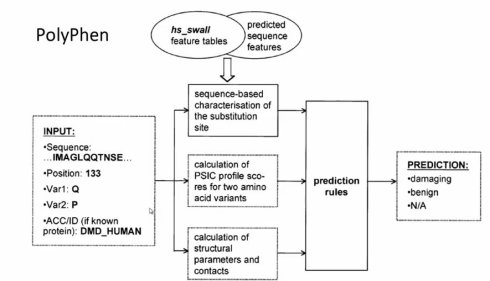
第一步 跟SIFT相似,先做一个多序列比对,即把同源蛋白,功能一样的蛋白做一个多序列比对
第二步 然后找到这个蛋白的三维结构,或者这个三维结构没有,但是有一个和你这个蛋白序列比较相类似的另外一个蛋白结构有,那你可以做一个同源建模,来预测它的三维结构
第三步 有了这个结构呢,PolyPhen就开始来算,你的这个看到的变异位点,它在结构上有什么特征,比如它是不是位于一个二硫键,因为二硫键对结构带来比较大的影响,它是不是处于一个位点呢,是不是处于一个重要的活性位点呢,它是不是出于跨膜区呢,跨膜区的变异经常会对结构和功能造成比较大的影响,它是不是出于信号肽的区域呢等等,这都是它评估的一些特征。
第四步 它也评估这个位点所在的二级结构是是什么?它是在蛋白的表面。还是在蛋白的内部,它有没有影响到它能形成的氢键的数目的改变等等。最后它做判断就是用一个所谓的rule-based,基于经验的 它的好处是在有三维结构的时候,还是比较好的,但是,没有三维结构,那它方法就用不了,也只能用在这个序列的信息,并且它的这些规则是完全基于经验的,那你的经验是对还是不对呢?
在2010年,他们课题组又开发了PolyPhen2这个版本:
-
增加了更多用来做预测的特征;
-
改成了用机器学习的一个方法,就是一个叫Naive Bayes的一种极其学习方法,这个算法的评估比原来基于经验的方法准确度是有很高的提高。
参考资料
北大魏丽萍老师的课件
