【6.6.4】单克隆抗体溶液浓度依赖性粘度曲线的计算机模拟预测
sam点评:
- 全长抗体,基于序列和结构来预测黏度
- 全长抗体的疏水表面积以及VH,VL和铰链区上的电荷组成的方程式能够预测抗体溶液的浓度依赖性粘度曲线
候选单克隆抗体(mAb)的早期可开发性评估可帮助降低与其产品开发相关的风险和成本。预测高浓度mAb溶液的粘度是此类可开发性评估的重要方面。平台制剂中mAb溶液的浓度依赖性粘度行为的可靠预测可以帮助筛选或优化候选药物,以实现灵活的生产和给药方式。在这里,我们提供了一种计算方法,可以仅根据mAb的序列-结构属性预测其浓度依赖性粘度曲线。该方法是根据16种不同mAb的实验数据开发的,这些单克隆抗体在标准条件下通过实验获得了浓度依赖性粘度曲线。通过对数操作,将每个浓度依赖性粘度曲线拟合为一条直线,并获得截距和斜率值。发现与抗体扩散率有关的拦截几乎是恒定的。相比之下,斜率(溶液粘度随溶质浓度的增加速率)在不同的mAb之间变化显着,表明分子间相互作用对粘度的重要性。接下来,检查了使用它们的全长同源性模型得出的16个mAb的静电和疏水性分子描述子与斜率的潜在相关性。发现由全长抗体的疏水表面积以及VH,VL和铰链区上的电荷组成的方程式能够预测抗体溶液的浓度依赖性粘度曲线。在药物发现和开发的早期阶段,此计算工具的可用性可能有助于对候选抗体进行无材料的高通量筛选。
一、前言
近年来,基于单克隆抗体(mAb)的治疗产品在制药公司的产品线中获得了更大的代表。例如,临床流程中的抗体分子总数从2013年的约350个增加到2016年的约470个。基于MAb的疗法可靶向多种疾病,目标特异性高,非机制毒性低的疾病。产品需要高浓度给药以改善患者依从性,易于给药并节省治疗成本。但是,在某些情况下,这些高浓度抗体溶液可能变得非常粘稠,从而给制造,存储和给药带来了挑战。因此,对于基于mAb的治疗剂的成功产品开发,期望在高浓度的抗体溶液中具有低粘度。
确保抗体溶液低粘度的典型方法取决于药物产品开发的阶段。如果产品处于开发后期,则可以追求配方的优化。然而,重新配制需要额外的材料和资源,这增加了药品开发本来已经很高的成本。因此,优选在早期发现阶段合理地优先化/优化抗体候选物。在早期阶段,可用于实验测试的材料是有限的。计算工具不需要任何材料,因此非常适合于单克隆抗体候选物的早期可开发性评估。
几十年前,开发了用于预测小分子粘度的计算工具[7-9],但迄今为止,文献中仅报道了很少的生物学研究。 Li和他的同事们率先使用计算出的分子特性预测高浓度mAb溶液的粘度。这些作者在标准化条件下实验测量了11种不同mAb的浓度依赖性粘度行为,并发现了与计算估计的分子描述符,如抗体的可变片段(Fv区)的电荷,ζ电位和聚集倾向的相关性。制剂在150 mg / mL时表现出高粘度的抗体分子在其Fv区含有带负电荷的斑块。这是因为这些Fv区的pI低于制剂缓冲液的pH。 Sharma和同事[11]还使用计算得出的分子描述符来预测,Li和同事使用的配方条件不同的配制条件下在180 mg / mL浓度下的粘度。这些作者还预测了人和食蟹猴之间的血浆清除率差异以及对色氨酸氧化的化学稳定性。使用分子动力学(MD)模拟进行天冬氨酸异构化。在第三项研究中,Trout和同事[12]开发了一种空间电荷图(SCM)工具,用于使用有关mAb Fv部分上电荷分布的信息来筛选抗体溶液。作者使用有关3家制药公司开发的mAb的数据验证了他们的方法。此外,Nichols等人[13]使用了粘度挑战的IgG1λmAb的Fv部分的分子模型来合理设计点突变,以改善其粘度行为。最近,Geoghegan等人[14]还证明,对IgG1 mAb的Fv部分进行基于结构的合理改造,可以帮助减轻其粘度和形成可逆自缔合的趋势。这些研究证明了分子建模和模拟对治疗性抗体候选药物的可开发性评估的实用性。
上述研究专注于仅使用Fv区的分子模型预测和提高高浓度mAb的粘度,而粘度数据是使用对全长mAb进行的实验收集的。仅针对Fv区的分子模型的使用忽略了恒定区对全长抗体的浓度依赖性粘度行为的贡献。由于抗体同种型的变化而对粘度行为的影响也被忽略。相反,Buck等人[15]对抗体溶液进行的粗粒度模拟显示,涉及可变(Fv)和恒定(CL,CH1和Fc)区域的域间相互作用参与了瞬态分子间网络的形成 ,因此有助于增加高浓度抗体溶液的粘度。 这种观察促使我们在本研究中使用全长抗体模型。
在药物开发过程中,不仅需要在一个任意选择的高浓度下,而且还要在很宽的浓度范围内了解抗体溶液的粘度行为。在制造,原料药存储,药品展示和给药过程中,抗体溶液的浓缩程度不同。在所有这些步骤中,浓度依赖性粘度行为的先验知识可能非常有用。在这里,我们提出了一种算法,可以仅根据氨基酸序列和基于同源性的结构模型预测同一制剂中不同单克隆抗体的浓度依赖性粘度曲线。将实验确定的16种不同抗体分子的浓度依赖性粘度曲线与从基于全长同源性的结构模型计算得出的分子描述符相结合,以构建该算法。尽管在早期研究中已强调了静电相互作用对抗体溶液粘度行为的贡献[6,10-13],但该分析表明疏水性也对蛋白质:蛋白质相互作用做出了重要贡献,最终导致在某些浓缩抗体溶液中的高粘度。
二、部分结果展示
2.1 黏度与浓度的相关性

黏度可以通过 A和B的公式来模拟出来

根据试验值,A和B都可以算出来。
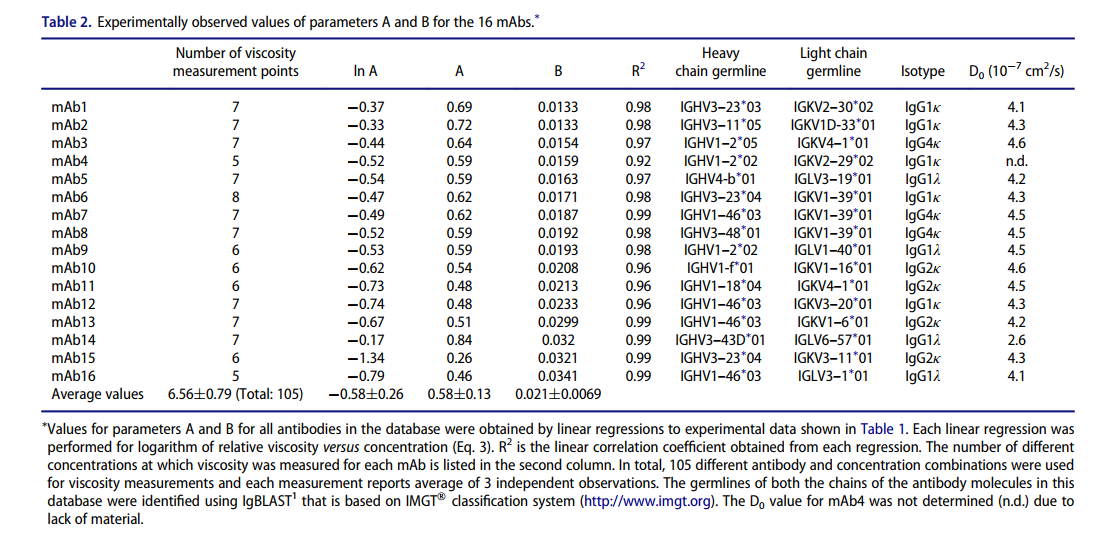
哪些特征可以用来预测B
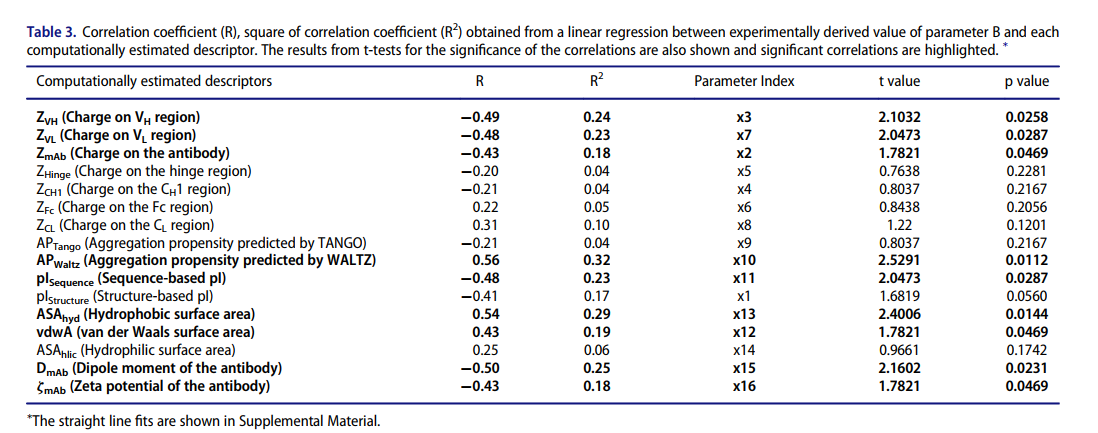
最终,B的公式为:
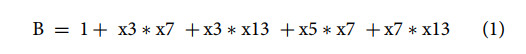
该公式的表现为: An R2 of 0.885 and adjusted R2 of 0.754 were obtained for this model. The F-statistic and p-value for the model in Eq. 1 are 6.75 and 0.0104
B预测的效果为:
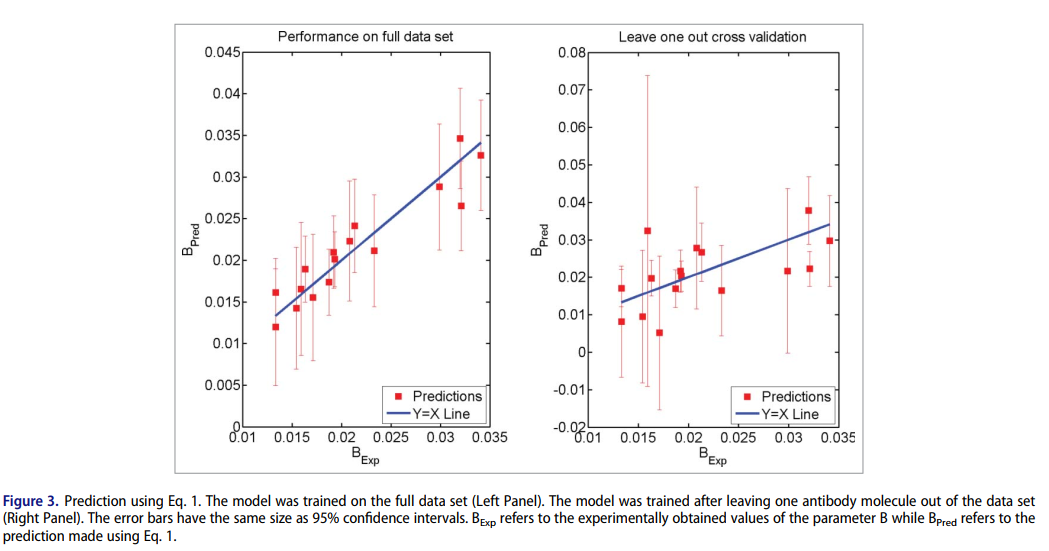
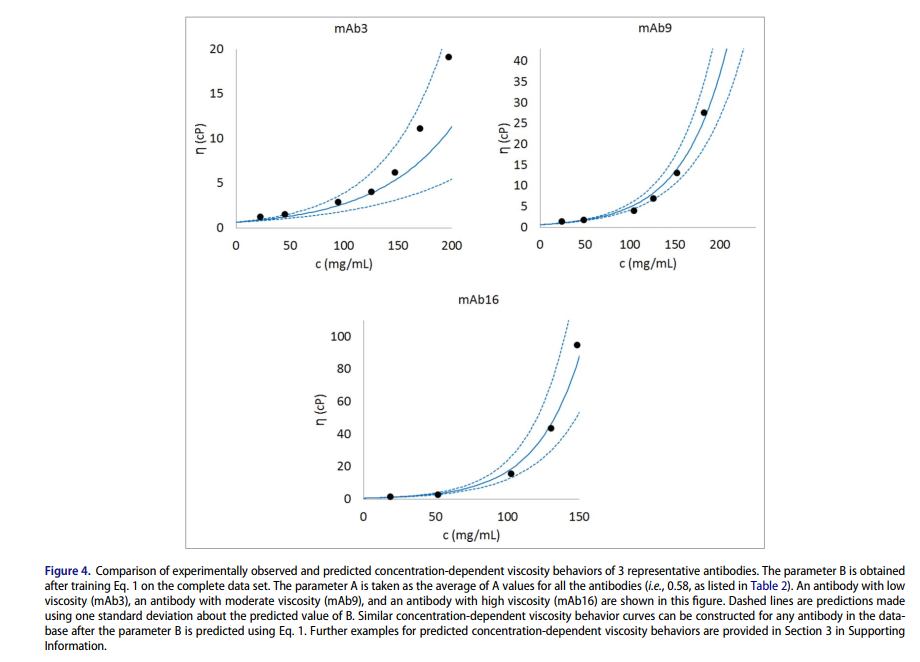
用预测的B来预测黏度
参考资料
- MAbs. 2017 Apr; 9(3): 476–489. In-silico prediction of concentration-dependent viscosity curves for monoclonal antibody solutions。 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5384706/
