NLP中的RNN、Seq2Seq与attention注意力机制
一、RNN循环神经网络
RNN循环神经网络被广泛应用于自然语言处理中,对于处理序列数据有很好的效果,常见的序列数据有文本、语音等,至于为什么要用到循环神经网络而不是传统的神经网络,我们在这里举一个例子。
假如有一个智能订票系统,我只需要输入一句话,该系统能识别出我将在什么时间订购去哪里的车票。那么程序需要根据我们输入的文本识别出我们出发的时间,目的地以及始发地。
如:我一月一号去郑州。
那么“一月一号”是时间,“郑州”是目的地,“我”和“去”都是其他不需要提取的信息,我们统一归为其他类。
那么假如我输入另外一个句子:
我一月一号离开郑州
此时“一月一号”是时间,“郑州”就变成了始发地,“我”和“离开”都是其他。
针对这个例子,我输入不同的文本,郑州表示为不同的label,用前馈神经网络去做的话,就不能将两个不同语境下的“郑州”区分开,所以这时我们需要我们的神经网络具有记忆功能,即,当在看到第一个文本中的“郑州”的时候,神经网络已经存储了“去”这个词的信息。当在看到第二个文本中的“郑州”的时候就已经存储了“离开”这个词的信息,因为“去”和“离开”两个词的信息不同,故就可以将两个文本中的“郑州”区分开。
下面我们根据这个例子去了解循环神经网络的结构
对于一个文本的每一个词可以看做是一个时序。RNN的每一个时序是一个前馈神经网络,但是为了在每一个时刻都包含前边时序的信息,所以RNN的每个时序共享了隐藏层,即当前时刻的输入不仅包含了当前时刻的词,还包含了前一时刻的隐藏层的输出。
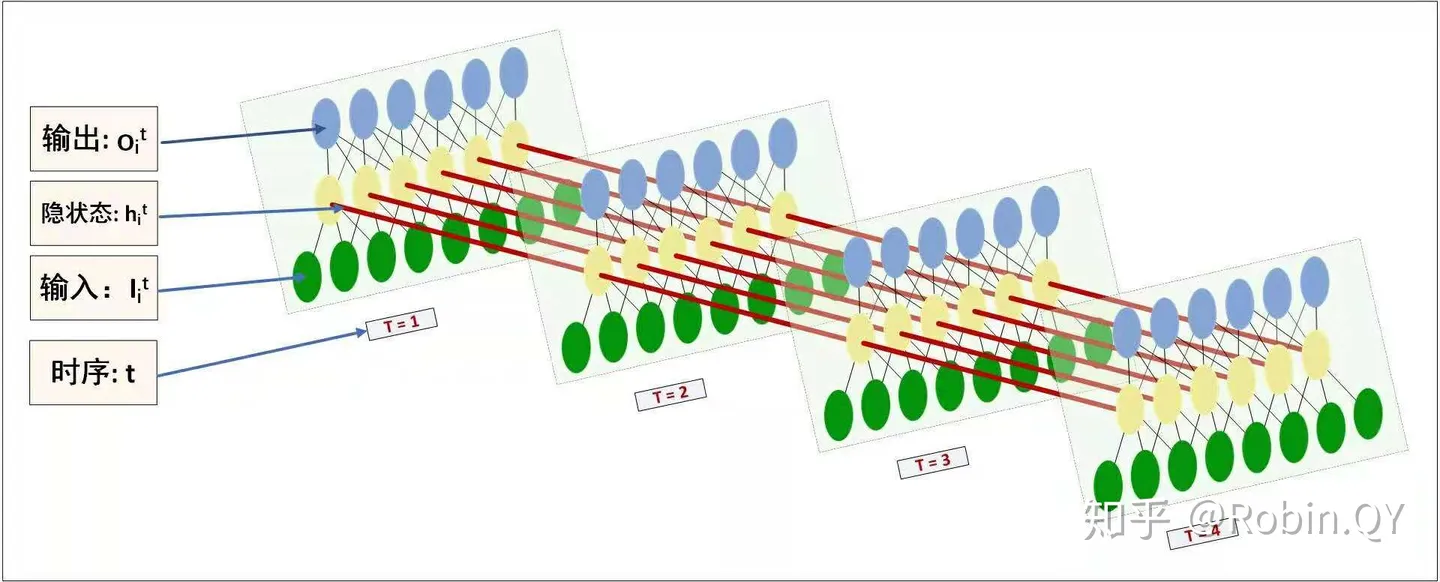
RNN结构图
因为计算机并不能读懂汉字,所以我们一般会用向量的方式去表示一个词。
向量表示词的方法有很多,常用的比如one-hot、词袋模型、词嵌入等。
在本例中为了方便计算在这里我们使用:
[1,1]表示我
[2,2]表示去
[3,3]表示离开
[4,4]表示郑州
并且假设所有的权重都是1,所有的偏置都是0。
下图为“我去郑州”的循环神经网络结构图。
我去郑州
我离开郑州 下图为“我离开郑州”的循环神经网络结构图。
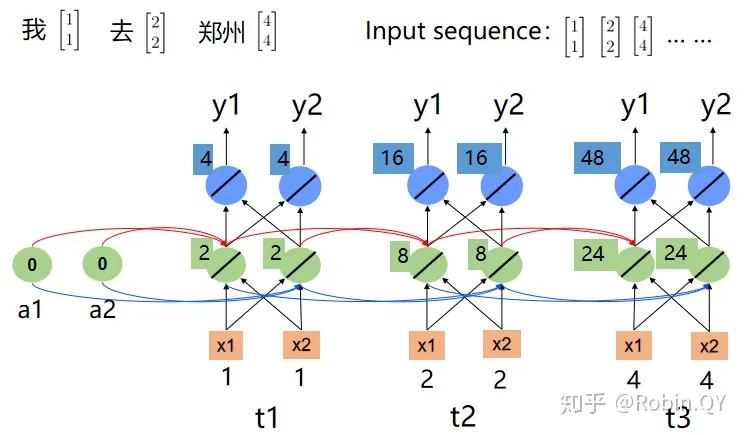
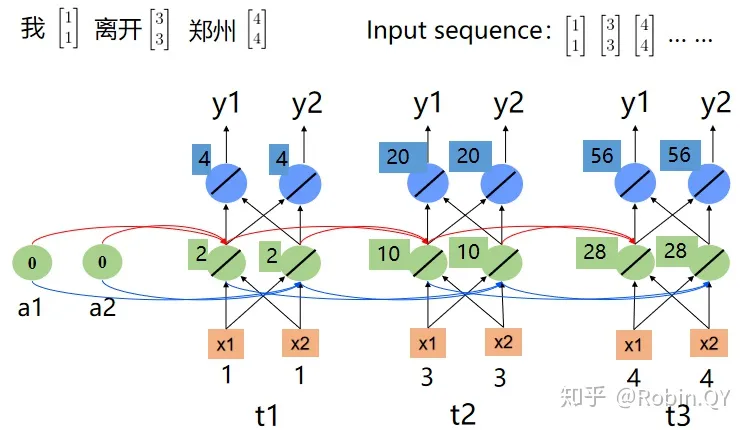
我们看到,因为“去”和“离开”的词向量不同,所以在循环神经网络中最后的“郑州”的输出也不相同,这样就能把两个“郑州”给区分开来了。
根据上边的例子可以看出来,循环神经网络中每一个时序的隐藏层不仅包含了前边时序的输入信息,也包含了前边时序的顺序信息。可以理解为包含了前边时序的语义信息。
循环神经网络展开图:
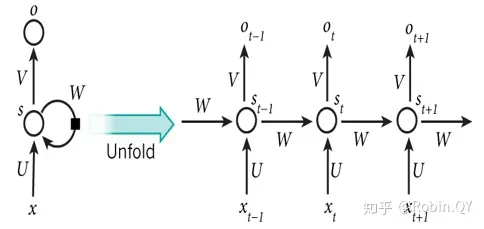
RNN展开图
可以看出,每一个时刻的输出不仅包含了该时刻的输入向量,也包含了前一时刻的隐藏层的输出。具体的计算公式如下:
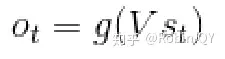
二、seq2seq模型
刚才的例子其实是N对N的循环神经网络,即我的输入序列长度是N,输出也是对应的N长度的序列。其实循环神经网络还有其他的比如:1对N、N对1。
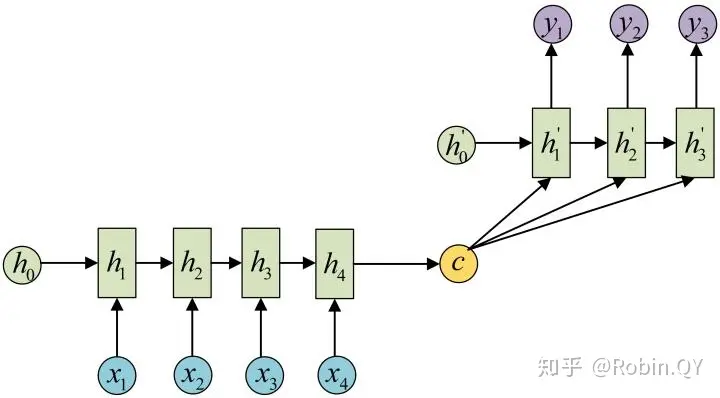
但很多时候我们会遇到输入序列和输出序列不等长的例子但又不是1对N和N对1,如机器翻译,智能问答,源语言和目标语言的句子往往并没有相同的长度。为此我们引出RNN最重要的一个变种:N vs M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。

seq2seq模型
还有一种做法是将c当做每一步的输入:
 seq2seq模型
seq2seq模型
对于序列到序列的数据来说,可以把Encoder和Decoder分别看成是RNN,在Encoder中根据输入数据生成一个语义编码C,C的获取方式有很多种,最简单的就是把Encoder中最后一个隐藏层赋值给C,也可以对最后一个隐藏状态做一个变换得到C,还可以对所有的隐藏状态做变换得到C。
拿到C之后,就可以用另一个RNN进行解码,这部分RNN被称为Decoder,具体做法就是将C当做之前的初始状态h0输入到Decoder中,C还有一种做法是将C当做每一步的输入。
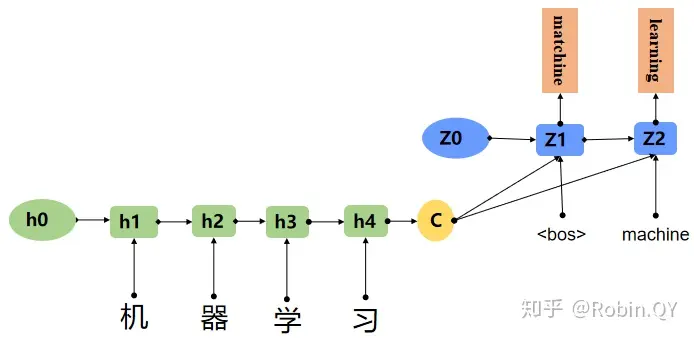
这里我们用一个机器翻译的例子解释seq2seq模型。
例:机器学习翻译 成 machine learning
三、Attention(注意力机制)
图片展示的Encoder-Decoder框架是没有体现“注意力模型”的,所以可以把它看做是注意力不集中分心模型。因为在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子的语义编码C都是一样的,没有任何区别。而语义编码C是由原句子中的每个单词经过Encoder编码产生的,这意味着原句子中任意单词对生成某个目标单词来说影响力都是相同的,这就是模型没有体现出注意力的缘由。
在上边那个例子中在生成“machine”时,“机”,“器”,“学”,““习"的贡献是相同的,很明显,这是不太合理,显然,“机”,“器”,对于翻译成"machine"更为重要。所以我们希望在模型翻译"machine"的时候,“机”,“器"两个字的贡献(权重)更大,当在翻译成"learning"时,“学”,“习"两个字贡献(权重)更大。
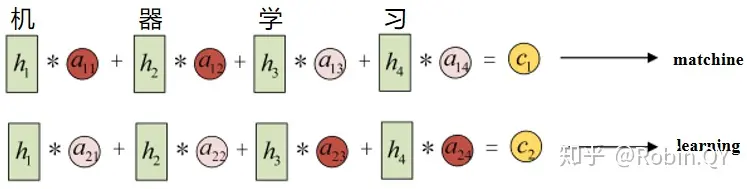
上图中,输入序列上是“机器学习”,因此Encoder中的h1、h2、h3、h4分别代表“机”,“器”,“学”,“习”的信息,在翻译"macine"时,第一个上下文向量C1应该和"机”,“器"两个字最相关,所以对应的权重a比较大,在翻译"learning"时,第二个上下文向量C2应该和"学”,“习"两个字最相关,所以"学”,“习"对应的权重a比较大。
a其实是一个0-1之间的值,a可以看成是e的softmax后的结果。
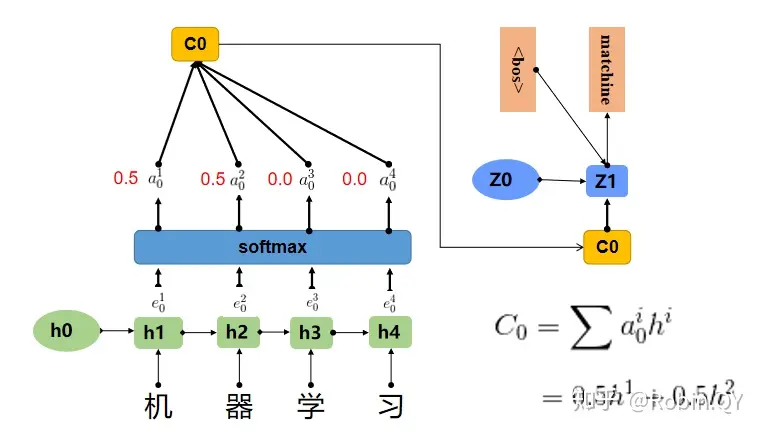
翻译matchine
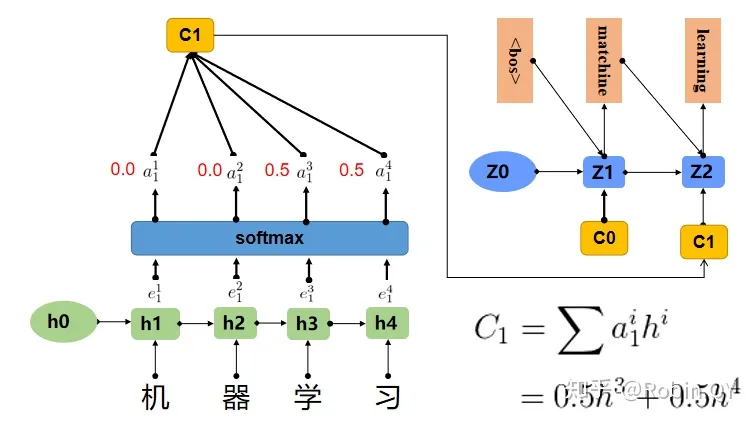
翻译learning
那现在关于attention来说就只剩下一个问题了,就是e是怎么来的。关于e的计算,业界有很多种方法,常用的有以下三种方式:
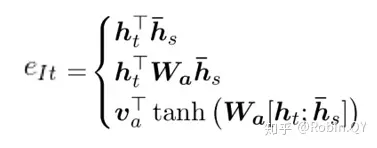
- 计算Encoder的序列h与Decoder的序列h的余弦相似度.
- 在1的基础上,乘上一个Wa,Wa是需要学习的参数,从学习到Encoder和Decoder的隐藏的打分e。
- 设计一个前馈神经网络,前馈神经网络的输入是Encoder和Decoder的两个隐藏状态,Va、Wa都是需要学习的参数。
总结
到这里,本文已经介绍了RNN循环神经网络的基本概念,seq2seq模型的基本概念及seq2seq中的注意力机制,希望能帮到大家。
参考资料
